C语言学习到放弃
数据类型
C 中的类型可分为以下几种:
| 序号 | 类型与描述 |
|---|---|
| 1 | 基本类型: 它们是算术类型,包括两种类型:整数类型和浮点类型。 |
| 2 | 枚举类型: 它们也是算术类型,被用来定义在程序中只能赋予其一定的离散整数值的变量。 |
| 3 | void 类型: 类型说明符 void 表明没有可用的值。 |
| 4 | 派生类型: 它们包括:指针类型、数组类型、结构类型、共用体类型和函数类型。 |
整数类型
| 类型 | 存储大小 | 值范围 |
|---|---|---|
| char | 1 字节 | -128 到 127 或 0 到 255 |
| unsigned char | 1 字节 | 0 到 255 |
| signed char | 1 字节 | -128 到 127 |
| int | 2 或 4 字节 | -32,768 到 32,767 或 -2,147,483,648 到 2,147,483,647 |
| unsigned int | 2 或 4 字节 | 0 到 65,535 或 0 到 4,294,967,295 |
| short | 2 字节 | -32,768 到 32,767 |
| unsigned short | 2 字节 | 0 到 65,535 |
| long | 4 字节 | -2,147,483,648 到 2,147,483,647 |
| unsigned long | 4 字节 | 0 到 4,294,967,295 |
1 |
|
浮点类型
| 类型 | 存储大小 | 值范围 | 精度 |
|---|---|---|---|
| float | 4 字节 | 1.2E-38 到 3.4E+38 | 6 位有效位 |
| double | 8 字节 | 2.3E-308 到 1.7E+308 | 15 位有效位 |
| long double | 16 字节 | 3.4E-4932 到 1.1E+4932 | 19 位有效位 |
头文件 float.h 定义了宏,在程序中可以使用这些值和其他有关实数二进制表示的细节。下面的实例将输出浮点类型占用的存储空间以及它的范围值:
1 |
|
void 类型
void 类型指定没有可用的值。它通常用于以下三种情况下:
| 序号 | 类型与描述 |
|---|---|
| 1 | 函数返回为空 C 中有各种函数都不返回值,或者您可以说它们返回空。不返回值的函数的返回类型为空。例如 void exit (int status); |
| 2 | 函数参数为空 C 中有各种函数不接受任何参数。不带参数的函数可以接受一个 void。例如 int rand(void); |
| 3 | 指针指向 void 类型为 void * 的指针代表对象的地址,而不是类型。例如,内存分配函数 void *malloc( size_t size ); 返回指向 void 的指针,可以转换为任何数据类型。 |
数据类型转换
1、数据类型转换:C 语言中如果一个表达式中含有不同类型的常量和变量,在计算时,会将它们自动转换为同一种类型;在 C 语言中也可以对数据类型进行强制转换;
2、自动转换规则:
- a)浮点数赋给整型,该浮点数小数被舍去;
- b)整数赋给浮点型,数值不变,但是被存储到相应的浮点型变量中;
3、强制类型转换形式: (类型说明符)(表达式)
C 变量
| 类型 | 描述 |
|---|---|
| char | 通常是一个字节(八位), 这是一个整数类型。 |
| int | 整型,4 个字节,取值范围 -2147483648 到 2147483647。 |
| float | 单精度浮点值。单精度是这样的格式,1位符号,8位指数,23位小数。 |
| double | 双精度浮点值。双精度是1位符号,11位指数,52位小数。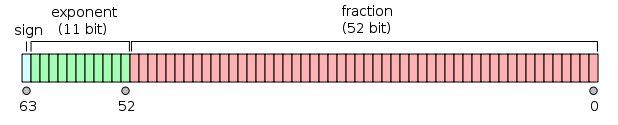 |
| void | 表示类型的缺失。 |
静态变量分为全局的静态变量和局部的静态变量。静态变量的值是可以改变的。
C 常量
常量是固定值,在程序执行期间不会改变。这些固定的值,又叫做字面量。
常量可以是任何的基本数据类型,比如整数常量、浮点常量、字符常量,或字符串字面值,也有枚举常量。
常量就像是常规的变量,只不过常量的值在定义后不能进行修改。
const类型的值是不能被修改的,但是,这个不能修改,意思是const 修饰的部分是不能被修改的。典型的应用是如下的两种:
const int* p; 这个声明的意思是:p 是一个指针,是指向const int 的一个指针。
也就是说,p这个地址是可以改变的,但是,不管地址如何变,其指向的值是不变的。
p = p + 1 是对的,但是 *p是不合法的,不能改变*p的值。
int* const p; 同样是定义一个指针,意思是:p是一个const的int类型的指针。
也就是说,p是一个地址,但是这个地址不能被改变,但是里面的值*p 是可以改变的。
p = p+1 是错误的,因为p已经固定了,但是*p是合法的。
C 中的运算符优先级
下表将按运算符优先级从高到低列出各个运算符,具有较高优先级的运算符出现在表格的上面,具有较低优先级的运算符出现在表格的下面。在表达式中,较高优先级的运算符会优先被计算。
| 类别 | 运算符 | 结合性 |
|---|---|---|
| 后缀 | () [] -> . ++ - - | 从左到右 |
| 一元 | + - ! ~ ++ - - (type)* & sizeof | 从右到左 |
| 乘除 | * / % | 从左到右 |
| 加减 | + - | 从左到右 |
| 移位 | << >> | 从左到右 |
| 关系 | < <= > >= | 从左到右 |
| 相等 | == != | 从左到右 |
| 位与 AND | & | 从左到右 |
| 位异或 XOR | ^ | 从左到右 |
| 位或 OR | | | 从左到右 |
| 逻辑与 AND | && | 从左到右 |
| 逻辑或 OR | || | 从左到右 |
| 条件 | ?: | 从右到左 |
| 赋值 | = += -= *= /= %=>>= <<= &= ^= |= | 从右到左 |
| 逗号 | , | 从左到右 |
函数参数
如果函数要使用参数,则必须声明接受参数值的变量。这些变量称为函数的形式参数。
形式参数就像函数内的其他局部变量,在进入函数时被创建,退出函数时被销毁。
当调用函数时,有两种向函数传递参数的方式:
| 调用类型 | 描述 |
|---|---|
| 传值调用 | 该方法把参数的实际值复制给函数的形式参数。在这种情况下,修改函数内的形式参数不会影响实际参数。 |
| 引用调用 | 通过指针传递方式,形参为指向实参地址的指针,当对形参的指向操作时,就相当于对实参本身进行的操作。 |
默认情况下,C 使用传值调用来传递参数。一般来说,这意味着函数内的代码不能改变用于调用函数的实际参数。
C数组
C 语言支持数组数据结构,它可以存储一个固定大小的相同类型元素的顺序集合。数组是用来存储一系列数据,但它往往被认为是一系列相同类型的变量。所有的数组都是由连续的内存位置组成。最低的地址对应第一个元素,最高的地址对应最后一个元素。
在 C 中,数组是非常重要的,我们需要了解更多有关数组的细节。下面列出了 C 程序员必须清楚的一些与数组相关的重要概念:
| 概念 | 描述 |
|---|---|
| 多维数组 | C 支持多维数组。多维数组最简单的形式是二维数组。 |
| 传递数组给函数 | 您可以通过指定不带索引的数组名称来给函数传递一个指向数组的指针。 |
| 从函数返回数组 | C 允许从函数返回数组。 |
| 指向数组的指针 | 您可以通过指定不带索引的数组名称来生成一个指向数组中第一个元素的指针。 |
C enum(枚举)
枚举是 C 语言中的一种基本数据类型,它可以让数据更简洁,更易读。
枚举语法定义格式为:
1 | enum 枚举名 {枚举元素1,枚举元素2,……}; |
1 | enum DAY |
注意:第一个枚举成员的默认值为整型的 0,后续枚举成员的值在前一个成员上加 1。我们在这个实例中把第一个枚举成员的值定义为 1,第二个就为 2,以此类推。
可以在定义枚举类型时改变枚举元素的值:
1 | enum season {spring, summer=3, autumn, winter}; |
没有指定值的枚举元素,其值为前一元素加 1。也就说 spring 的值为 0,summer 的值为 3,autumn 的值为 4,winter 的值为 5
枚举变量的定义
1、先定义枚举类型,再定义枚举变量
1 | enum DAY |
2、定义枚举类型的同时定义枚举变量
1 | enum DAY |
3、省略枚举名称,直接定义枚举变量
1 | enum |
在C 语言中,枚举类型是被当做 int 或者 unsigned int 类型来处理的,所以按照 C 语言规范是没有办法遍历枚举类型的。
不过在一些特殊的情况下,枚举类型必须连续是可以实现有条件的遍历。
以下实例使用 for 来遍历枚举的元素:
1 |
|
C 指针详解
在 C 中,有很多指针相关的概念,这些概念都很简单,但是都很重要。下面列出了 C 程序员必须清楚的一些与指针相关的重要概念:
| 概念 | 描述 |
|---|---|
| 指针的算术运算 | 可以对指针进行四种算术运算:++、–、+、- |
| 指针数组 | 可以定义用来存储指针的数组。 |
| 指向指针的指针 | C 允许指向指针的指针。 |
| 传递指针给函数 | 通过引用或地址传递参数,使传递的参数在调用函数中被改变。 |
| 从函数返回指针 | C 允许函数返回指针到局部变量、静态变量和动态内存分配。 |
函数指针
函数指针是指向函数的指针变量。
通常我们说的指针变量是指向一个整型、字符型或数组等变量,而函数指针是指向函数。
函数指针可以像一般函数一样,用于调用函数、传递参数。
函数指针变量的声明:
1 | typedef int (*fun_ptr)(int,int); // 声明一个指向同样参数、返回值的函数指针类型 |
以下实例声明了函数指针变量 p,指向函数 max:
1 |
|
回调函数
函数指针作为某个函数的参数
函数指针变量可以作为某个函数的参数来使用的,回调函数就是一个通过函数指针调用的函数。
简单讲:回调函数是由别人的函数执行时调用你实现的函数。
1 | 你到一个商店买东西,刚好你要的东西没有货,于是你在店员那里留下了你的电话,过了几天店里有货了,店员就打了你的电话,然后你接到电话后就到店里去取了货。在这个例子里,你的电话号码就叫回调函数,你把电话留给店员就叫登记回调函数,店里后来有货了叫做触发了回调关联的事件,店员给你打电话叫做调用回调函数,你到店里去取货叫做响应回调事件。 |
实例中 populate_array 函数定义了三个参数,其中第三个参数是函数的指针,通过该函数来设置数组的值。
实例中我们定义了回调函数 getNextRandomValue,它返回一个随机值,它作为一个函数指针传递给 populate_array 函数。
populate_array 将调用 10 次回调函数,并将回调函数的返回值赋值给数组。
1 |
|
C 结构体
struct 语句定义了一个包含多个成员的新的数据类型,
1 | struct tag { |
在一般情况下,tag、member-list、variable-list 这 3 部分至少要出现 2 个。以下为实例:
1 | //此声明声明了拥有3个成员的结构体,分别为整型的a,字符型的b和双精度的c |
在上面的声明中,第一个和第二声明被编译器当作两个完全不同的类型,即使他们的成员列表是一样的,如果令 t3=&s1,则是非法的。
结构体的成员可以包含其他结构体,也可以包含指向自己结构体类型的指针,而通常这种指针的应用是为了实现一些更高级的数据结构如链表和树等。
1 | //此结构体的声明包含了其他的结构体 |
如果两个结构体互相包含,则需要对其中一个结构体进行不完整声明,如下所示:
1 | struct B; //对结构体B进行不完整声明 |
为了访问结构的成员,我们使用成员访问运算符(.)。成员访问运算符是结构变量名称和我们要访问的结构成员之间的一个句号。您可以使用 struct 关键字来定义结构类型的变量。
您可以定义指向结构的指针,方式与定义指向其他类型变量的指针相似,如下所示:
1 | struct Books *struct_pointer; |
现在,您可以在上述定义的指针变量中存储结构变量的地址。为了查找结构变量的地址,请把 & 运算符放在结构名称的前面,如下所示:
1 | struct_pointer = &Book1; |
为了使用指向该结构的指针访问结构的成员,您必须使用 -> 运算符,如下所示:
1 | struct_pointer->title; |
C 共用体
共用体是一种特殊的数据类型,允许您在相同的内存位置存储不同的数据类型。您可以定义一个带有多成员的共用体,但是任何时候只能有一个成员带有值。共用体提供了一种使用相同的内存位置的有效方式。
定义共用体
为了定义共用体,您必须使用 union 语句,方式与定义结构类似。union 语句定义了一个新的数据类型,带有多个成员。union 语句的格式如下:
1 | union [union tag] |
union tag 是可选的,每个 member definition 是标准的变量定义,比如 int i; 或者 float f; 或者其他有效的变量定义。在共用体定义的末尾,最后一个分号之前,您可以指定一个或多个共用体变量,这是可选的。下面定义一个名为 Data 的共用体类型,有三个成员 i、f 和 str:
1 | union Data |
现在,Data 类型的变量可以存储一个整数、一个浮点数,或者一个字符串。这意味着一个变量(相同的内存位置)可以存储多个多种类型的数据。您可以根据需要在一个共用体内使用任何内置的或者用户自定义的数据类型。
共用体占用的内存应足够存储共用体中最大的成员。例如,在上面的实例中,Data 将占用 20 个字节的内存空间,因为在各个成员中,字符串所占用的空间是最大的。下面的实例将显示上面的共用体占用的总内存大小:
访问共用体成员
为了访问共用体的成员,我们使用成员访问运算符(.)。成员访问运算符是共用体变量名称和我们要访问的共用体成员之间的一个句号。您可以使用 union 关键字来定义共用体类型的变量。下面的实例演示了共用体的用法:
1 |
|
当上面的代码被编译和执行时,它会产生下列结果:
1 | data.i : 1917853763 |
在这里,我们可以看到共用体的 i 和 f 成员的值有损坏,因为最后赋给变量的值占用了内存位置,这也是 str 成员能够完好输出的原因。现在让我们再来看一个相同的实例,这次我们在同一时间只使用一个变量,这也演示了使用共用体的主要目的:
1 |
|
当上面的代码被编译和执行时,它会产生下列结果:
1 | data.i : 10 |
在这里,所有的成员都能完好输出,因为同一时间只用到一个成员。
C 位域
如果程序的结构中包含多个开关量,只有 TRUE/FALSE 变量,如下:
1 | struct |
这种结构需要 8 字节的内存空间,但在实际上,在每个变量中,我们只存储 0 或 1。在这种情况下,C 语言提供了一种更好的利用内存空间的方式。如果您在结构内使用这样的变量,您可以定义变量的宽度来告诉编译器,您将只使用这些字节。例如,上面的结构可以重写成:
1 | struct |
现在,上面的结构中,status 变量将占用 4 个字节的内存空间,但是只有 2 位被用来存储值。如果您用了 32 个变量,每一个变量宽度为 1 位,那么 status 结构将使用 4 个字节,但只要您再多用一个变量,如果使用了 33 个变量,那么它将分配内存的下一段来存储第 33 个变量,这个时候就开始使用 8 个字节。让我们看看下面的实例来理解这个概念:
1 |
|
当上面的代码被编译和执行时,它会产生下列结果:
1 | Memory size occupied by status1 : 8 |
位域声明
有些信息在存储时,并不需要占用一个完整的字节,而只需占几个或一个二进制位。例如在存放一个开关量时,只有 0 和 1 两种状态,用 1 位二进位即可。为了节省存储空间,并使处理简便,C 语言又提供了一种数据结构,称为”位域”或”位段”。
所谓”位域”是把一个字节中的二进位划分为几个不同的区域,并说明每个区域的位数。每个域有一个域名,允许在程序中按域名进行操作。这样就可以把几个不同的对象用一个字节的二进制位域来表示。
典型的实例:
- 用 1 位二进位存放一个开关量时,只有 0 和 1 两种状态。
- 读取外部文件格式——可以读取非标准的文件格式。例如:9 位的整数。
位域的定义和位域变量的说明
位域定义与结构定义相仿,其形式为:
1 | struct 位域结构名 |
其中位域列表的形式为:
1 | type [member_name] : width ; |
下面是有关位域中变量元素的描述:
| 元素 | 描述 |
|---|---|
| type | 只能为 int(整型),unsigned int(无符号整型),signed int(有符号整型) 三种类型,决定了如何解释位域的值。 |
| member_name | 位域的名称。 |
| width | 位域中位的数量。宽度必须小于或等于指定类型的位宽度。 |
带有预定义宽度的变量被称为位域。位域可以存储多于 1 位的数,例如,需要一个变量来存储从 0 到 7 的值,您可以定义一个宽度为 3 位的位域,如下:
1 | struct |
上面的结构定义指示 C 编译器,age 变量将只使用 3 位来存储这个值,如果您试图使用超过 3 位,则无法完成。
1 | struct bs{ |
data 为 bs 变量,共占两个字节。其中位域 a 占 8 位,位域 b 占 2 位,位域 c 占 6 位。
让我们再来看一个实例:
1 | struct packed_struct { |
在这里,packed_struct 包含了 6 个成员:四个 1 位的标识符 f1..f4、一个 4 位的 type 和一个 9 位的 my_int。
让我们来看下面的实例:
1 |
|
当上面的代码被编译时,它会带有警告,当上面的代码被执行时,它会产生下列结果:
1 | Sizeof( Age ) : 4 |
对于位域的定义尚有以下几点说明:
一个位域存储在同一个字节中,如一个字节所剩空间不够存放另一位域时,则会从下一单元起存放该位域。也可以有意使某位域从下一单元开始。例如:
1
2
3
4
5
6struct bs{
unsigned a:4;
unsigned :4; /* 空域 */
unsigned b:4; /* 从下一单元开始存放 */
unsigned c:4
}在这个位域定义中,a 占第一字节的 4 位,后 4 位填 0 表示不使用,b 从第二字节开始,占用 4 位,c 占用 4 位。
位域的宽度不能超过它所依附的数据类型的长度,成员变量都是有类型的,这个类型限制了成员变量的最大长度,: 后面的数字不能超过这个长度。
位域可以是无名位域,这时它只用来作填充或调整位置。无名的位域是不能使用的。例如:
1
2
3
4
5
6struct k{
int a:1;
int :2; /* 该 2 位不能使用 */
int b:3;
int c:2;
};
从以上分析可以看出,位域在本质上就是一种结构类型,不过其成员是按二进位分配的。
位域的使用
位域的使用和结构成员的使用相同,其一般形式为:
1 | 位域变量名.位域名 |
位域允许用各种格式输出。
请看下面的实例:
1 |
|
上例程序中定义了位域结构 bs,三个位域为 a、b、c。说明了 bs 类型的变量 bit 和指向 bs 类型的指针变量 pbit。这表示位域也是可以使用指针的。
结构体内存分配原则
原则一:结构体中元素按照定义顺序存放到内存中,但并不是紧密排列。从结构体存储的首地址开始 ,每一个元素存入内存中时,它都会认为内存是以自己的宽度来划分空间的,因此元素存放的位置一定会在自己大小的整数倍上开始。
原则二: 在原则一的基础上,检查计算出的存储单元是否为所有元素中最宽的元素长度的整数倍。若是,则结束;否则,将其补齐为它的整数倍。
1 |
|
输出:
1 | sizeof(T1) = 16 |
解析
1 | sizeof(T1.x) = sizeof(T2.x) = 1; |
T1: 若从第 0 个字节开始分配内存,则 T1.x 存入第 0 字节,T1.y 占 4 个字节,由于第一的 4 字节已有数据,所以 T1.y 存入第 4-7 个字节,T1.z 占 8 个字节,由于第一个 8 字节已有数据,所以 T1.z 存入 8-15 个字节。共占有 16 个字节。
T2: 若从第 0 个字节开始分配内存,则 T1.x 存入第 0 字节,T1.z 占 8 个字节,由于第一的 8 字节已有数据,所以 T1.z 存入第 8-15 个字节,T1.y 占 4 个字节,由于前四个 4 字节已有数据,所以 T1.z 存入 16-19 个字节。共占有 20 个字节。此时所占字节不是最宽元素(double 长度为 8)的整数倍,因此将其补齐到 8 的整数倍,最终结果为 24。
定义位域时,各个成员的类型最好保持一致,比如都用char,或都用int,不要混合使用,这样才能达到节省内存空间的目的。
C typedef
C 语言提供了 typedef 关键字,您可以使用它来为类型取一个新的名字。下面的实例为单字节数字定义了一个术语 BYTE:
1 | typedef unsigned char BYTE; |
在这个类型定义之后,标识符 BYTE 可作为类型 unsigned char 的缩写,例如:
1 | BYTE b1, b2; |
按照惯例,定义时会大写字母,以便提醒用户类型名称是一个象征性的缩写,但您也可以使用小写字母,如下:
1 | typedef unsigned char byte; |
您也可以使用 typedef 来为用户自定义的数据类型取一个新的名字。例如,您可以对结构体使用 typedef 来定义一个新的数据类型名字,然后使用这个新的数据类型来直接定义结构变量,如下:
1 | typedef struct Books |
typedef vs #define
#define 是 C 指令,用于为各种数据类型定义别名,与 typedef 类似,但是它们有以下几点不同:
- typedef 仅限于为类型定义符号名称,#define 不仅可以为类型定义别名,也能为数值定义别名,比如您可以定义 1 为 ONE。
- typedef 是由编译器执行解释的,#define 语句是由预编译器进行处理的。
下面是 #define 的最简单的用法:
1 |
|
C 文件读写
一个文件,无论它是文本文件还是二进制文件,都是代表了一系列的字节。C 语言不仅提供了访问顶层的函数,也提供了底层(OS)调用来处理存储设备上的文件。
打开文件
您可以使用 fopen( ) 函数来创建一个新的文件或者打开一个已有的文件,这个调用会初始化类型 FILE 的一个对象,类型 FILE 包含了所有用来控制流的必要的信息。下面是这个函数调用的原型:
1 | FILE *fopen( const char *filename, const char *mode ); |
在这里,filename 是字符串,用来命名文件,访问模式 mode 的值可以是下列值中的一个:
| 模式 | 描述 |
|---|---|
| r | 打开一个已有的文本文件,允许读取文件。 |
| w | 打开一个文本文件,允许写入文件。如果文件不存在,则会创建一个新文件。在这里,您的程序会从文件的开头写入内容。如果文件存在,则该会被截断为零长度,重新写入。 |
| a | 打开一个文本文件,以追加模式写入文件。如果文件不存在,则会创建一个新文件。在这里,您的程序会在已有的文件内容中追加内容。 |
| r+ | 打开一个文本文件,允许读写文件。 |
| w+ | 打开一个文本文件,允许读写文件。如果文件已存在,则文件会被截断为零长度,如果文件不存在,则会创建一个新文件。 |
| a+ | 打开一个文本文件,允许读写文件。如果文件不存在,则会创建一个新文件。读取会从文件的开头开始,写入则只能是追加模式。 |
如果处理的是二进制文件,则需使用下面的访问模式来取代上面的访问模式:
1 | "rb", "wb", "ab", "rb+", "r+b", "wb+", "w+b", "ab+", "a+b" |
对 fopen()函数补充说明几点:
1 | FILE *fopen( const char * filename, const char * mode ); |
该函数可能执行失败,返回值是NULL,安全起见必须对返回值进行合法性判断;
该函数有多种模式,其中r+和w+看似一样,都是读写其实还是有几点区别的;
1.模式r+找不到文件不会自动新建,而w+会;
2.模式r+打开文件后,不会清除文件原数据,若直接开始写入,只会从起始位置开始进行覆盖,而w+会直接清零后,再开始读写;
模式的合法性说明:不能用大写,只能是小写,且rb+和r+b都是合法的,但br+和+rb等都是非法的,w和a也是一样的处理;
模式w的自动新建文件是有条件的,只有对应的路径存在(即文件所在的文件夹存在),文件不存在才会新建,否则是不会新建的,返回NULL
关闭文件
为了关闭文件,请使用 fclose( ) 函数。函数的原型如下:
1 | int fclose( FILE *fp ); |
如果成功关闭文件,fclose( ) 函数返回零,如果关闭文件时发生错误,函数返回 EOF。这个函数实际上,会清空缓冲区中的数据,关闭文件,并释放用于该文件的所有内存。EOF 是一个定义在头文件 stdio.h 中的常量。
C 标准库提供了各种函数来按字符或者以固定长度字符串的形式读写文件。
写入文件
下面是把字符写入到流中的最简单的函数:
1 | int fputc( int c, FILE *fp ); |
函数 fputc() 把参数 c 的字符值写入到 fp 所指向的输出流中。如果写入成功,它会返回写入的字符,如果发生错误,则会返回 EOF。您可以使用下面的函数来把一个以 null 结尾的字符串写入到流中:
1 | int fputs( const char *s, FILE *fp ); |
函数 fputs() 把字符串 s 写入到 fp 所指向的输出流中。如果写入成功,它会返回一个非负值,如果发生错误,则会返回 EOF。您也可以使用 int fprintf(FILE *fp,const char *format, …) 函数把一个字符串写入到文件中。尝试下面的实例:
注意:请确保您有可用的 tmp 目录,如果不存在该目录,则需要在您的计算机上先创建该目录。
/tmp 一般是 Linux 系统上的临时目录,如果你在 Windows 系统上运行,则需要修改为本地环境中已存在的目录,例如: C:\tmp、D:\tmp等。
1 |
|
读取文件
下面是从文件读取单个字符的最简单的函数:
1 | int fgetc( FILE * fp ); |
fgetc() 函数从 fp 所指向的输入文件中读取一个字符。返回值是读取的字符,如果发生错误则返回 EOF。下面的函数允许您从流中读取一个字符串:
1 | char *fgets( char *buf, int n, FILE *fp ); |
函数 fgets() 从 fp 所指向的输入流中读取 n - 1 个字符。它会把读取的字符串复制到缓冲区 buf,并在最后追加一个 null 字符来终止字符串。
如果这个函数在读取最后一个字符之前就遇到一个换行符 ‘\n’ 或文件的末尾 EOF,则只会返回读取到的字符,包括换行符。您也可以使用 int fscanf(FILE *fp, const char *format, …) 函数来从文件中读取字符串,但是在遇到第一个空格和换行符时,它会停止读取。
1 |
|
当上面的代码被编译和执行时,它会读取上一部分创建的文件,产生下列结果:
1 | 1: This |
首先,fscanf() 方法只读取了 This,因为它在后边遇到了一个空格。其次,调用 fgets() 读取剩余的部分,直到行尾。最后,调用 fgets() 完整地读取第二行。
二进制 I/O 函数
下面两个函数用于二进制输入和输出:
1 | size_t fread(void *ptr, size_t size_of_elements, size_t number_of_elements, FILE *a_file); |
这两个函数都是用于存储块的读写 - 通常是数组或结构体。
补充
- fseek 可以移动文件指针到指定位置读,或插入写:
1 | int fseek(FILE *stream, long offset, int whence); |
fseek 设置当前读写点到 offset 处, whence 可以是 SEEK_SET,SEEK_CUR,SEEK_END 这些值决定是从文件头、当前点和文件尾计算偏移量 offset。
你可以定义一个文件指针 FILE *fp,当你打开一个文件时,文件指针指向开头,你要指到多少个字节,只要控制偏移量就好,例如, 相对当前位置往后移动一个字节:fseek(fp, 1, SEEK_CUR); 中间的值就是偏移量。 如果你要往前移动一个字节,直接改为负值就可以:fseek(fp, -1, SEEK_CUR)。
执行以下实例前,确保当前目录下 test.txt 文件已创建:
1 |
|
执行结束后,打开 test.txt 文件:
1 | This is teAting for fprintf... |
注意: 只有用 r+ 模式打开文件才能插入内容,w 或 w+ 模式都会清空掉原来文件的内容再来写,a 或 a+ 模式即总会在文件最尾添加内容,哪怕用 fseek() 移动了文件指针位置。
- 在新版的 VS 编译环境中提示 fopen 不安全,推荐使用 fopen_s 代替。
fopen_s 和 fopen 的区别在于:
1 | errno_t fopen_s( FILE** pFile, const char *filename, const char *mode ); |
fopen_s 有三个参数,第一个参数是二级指针,用于存放文件流指针地址,其他的同 fopen 一致。
也就是说,用 fopen 需要这么写:
1 | FILE* fp=NULL; |
而如果用 fopen_s:
1 | FILE* fp=NULL; |
C 预处理器
C 预处理器不是编译器的组成部分,但是它是编译过程中一个单独的步骤。简言之,C 预处理器只不过是一个文本替换工具而已,它们会指示编译器在实际编译之前完成所需的预处理。我们将把 C 预处理器(C Preprocessor)简写为 CPP。
所有的预处理器命令都是以井号(#)开头。它必须是第一个非空字符,为了增强可读性,预处理器指令应从第一列开始。下面列出了所有重要的预处理器指令:
| 指令 | 描述 |
|---|---|
| #define | 定义宏 |
| #include | 包含一个源代码文件 |
| #undef | 取消已定义的宏 |
| #ifdef | 如果宏已经定义,则返回真 |
| #ifndef | 如果宏没有定义,则返回真 |
| #if | 如果给定条件为真,则编译下面代码 |
| #else | #if 的替代方案 |
| #elif | 如果前面的 #if 给定条件不为真,当前条件为真,则编译下面代码 |
| #endif | 结束一个 #if……#else 条件编译块 |
| #error | 当遇到标准错误时,输出错误消息 |
| #pragma | 使用标准化方法,向编译器发布特殊的命令到编译器中 |
预处理器实例
分析下面的实例来理解不同的指令。
1 |
这个指令告诉 CPP 把所有的 MAX_ARRAY_LENGTH 替换为 20。使用 #define 定义常量来增强可读性。
1 |
这些指令告诉 CPP 从系统库中获取 stdio.h,并添加文本到当前的源文件中。下一行告诉 CPP 从本地目录中获取 myheader.h,并添加内容到当前的源文件中。
1 |
这个指令告诉 CPP 取消已定义的 FILE_SIZE,并定义它为 42。
1 |
这个指令告诉 CPP 只有当 MESSAGE 未定义时,才定义 MESSAGE。
1 |
|
这个指令告诉 CPP 如果定义了 DEBUG,则执行处理语句。在编译时,如果您向 gcc 编译器传递了 -DDEBUG 开关量,这个指令就非常有用。它定义了 DEBUG,您可以在编译期间随时开启或关闭调试。
预定义宏
ANSI C 定义了许多宏。在编程中您可以使用这些宏,但是不能直接修改这些预定义的宏。
| 宏 | 描述 |
|---|---|
| DATE | 当前日期,一个以 “MMM DD YYYY” 格式表示的字符常量。 |
| TIME | 当前时间,一个以 “HH:MM:SS” 格式表示的字符常量。 |
| FILE | 这会包含当前文件名,一个字符串常量。 |
| LINE | 这会包含当前行号,一个十进制常量。 |
| STDC | 当编译器以 ANSI 标准编译时,则定义为 1。 |
1 |
|
当上面的代码(在文件 test.c 中)被编译和执行时,它会产生下列结果:
1 | File :test.c |
预处理器运算符
C 预处理器提供了下列的运算符来帮助您创建宏:
宏延续运算符(\)
一个宏通常写在一个单行上。但是如果宏太长,一个单行容纳不下,则使用宏延续运算符(\)。例如:
1 |
|
字符串常量化运算符(#)
在宏定义中,当需要把一个宏的参数转换为字符串常量时,则使用字符串常量化运算符(#)。在宏中使用的该运算符有一个特定的参数或参数列表。例如:
1 |
|
当上面的代码被编译和执行时,它会产生下列结果:
1 | Carole and Debra: We love you! |
标记粘贴运算符(##)
宏定义内的标记粘贴运算符(##)会合并两个参数。它允许在宏定义中两个独立的标记被合并为一个标记。例如:
1 |
|
当上面的代码被编译和执行时,它会产生下列结果:
1 | token34 = 40 |
这是怎么发生的,因为这个实例会从编译器产生下列的实际输出:
1 | printf ("token34 = %d", token34); |
这个实例演示了 token##n 会连接到 token34 中,在这里,我们使用了字符串常量化运算符(#)和标记粘贴运算符(##)。
defined() 运算符
预处理器 defined 运算符是用在常量表达式中的,用来确定一个标识符是否已经使用 #define 定义过。如果指定的标识符已定义,则值为真(非零)。如果指定的标识符未定义,则值为假(零)。下面的实例演示了 defined() 运算符的用法:
1 |
|
当上面的代码被编译和执行时,它会产生下列结果:
1 | Here is the message: You wish! |
参数化的宏
CPP 一个强大的功能是可以使用参数化的宏来模拟函数。例如,下面的代码是计算一个数的平方:
1 | int square(int x) { |
我们可以使用宏重写上面的代码,如下:
1 |
在使用带有参数的宏之前,必须使用 #define 指令定义。参数列表是括在圆括号内,且必须紧跟在宏名称的后边。宏名称和左圆括号之间不允许有空格。例如:
1 |
|
当上面的代码被编译和执行时,它会产生下列结果:
1 | Max between 20 and 10 is 20 |
使用#define含参时,参数括号很重要,如上例中省略括号会导致运算错误:
1 |
|
输出结果为:
1 | square 5+4 is 81 |
原因:
1 | square 等价于 (5+4)*(5+4)=81 |
C 头文件
头文件是扩展名为 .h 的文件,包含了 C 函数声明和宏定义,被多个源文件中引用共享。有两种类型的头文件:程序员编写的头文件和编译器自带的头文件。
在程序中要使用头文件,需要使用 C 预处理指令 #include 来引用它。前面我们已经看过 stdio.h 头文件,它是编译器自带的头文件。
引用头文件相当于复制头文件的内容,但是我们不会直接在源文件中复制头文件的内容,因为这么做很容易出错,特别在程序是由多个源文件组成的时候。
A simple practice in C 或 C++ 程序中,建议把所有的常量、宏、系统全局变量和函数原型写在头文件中,在需要的时候随时引用这些头文件。
引用头文件的语法
使用预处理指令 #include 可以引用用户和系统头文件。它的形式有以下两种:
1 |
这种形式用于引用系统头文件。它在系统目录的标准列表中搜索名为 file 的文件。在编译源代码时,您可以通过 -I 选项把目录前置在该列表前。
1 |
这种形式用于引用用户头文件。它在包含当前文件的目录中搜索名为 file 的文件。在编译源代码时,您可以通过 -I 选项把目录前置在该列表前。
#include < > 引用的是编译器的类库路径里面的头文件。
#include “ “ 引用的是你程序目录的相对路径中的头文件,如果在程序目录没有找到引用的头文件则到编译器的类库路径的目录下找该头文件。
引用头文件的操作
#include 指令会指示 C 预处理器浏览指定的文件作为输入。预处理器的输出包含了已经生成的输出,被引用文件生成的输出以及 #include 指令之后的文本输出。例如,如果您有一个头文件 header.h,如下:
1 | char *test (void); |
和一个使用了头文件的主程序 program.c,如下:
1 | int x; |
编译器会看到如下的代码信息:
1 | int x; |
只引用一次头文件
如果一个头文件被引用两次,编译器会处理两次头文件的内容,这将产生错误。为了防止这种情况,标准的做法是把文件的整个内容放在条件编译语句中,如下:
1 |
|
这种结构就是通常所说的包装器 #ifndef。当再次引用头文件时,条件为假,因为 HEADER_FILE 已定义。此时,预处理器会跳过文件的整个内容,编译器会忽略它。
在有多个 .h 文件和多个 .c 文件的时候,往往我们会用一个 global.h 的头文件来包括所有的 .h 文件,然后在除 global.h 文件外的头文件中 包含 global.h 就可以实现所有头文件的包含,同时不会乱。方便在各个文件里面调用其他文件的函数或者变量。
1 |
有条件引用
有时需要从多个不同的头文件中选择一个引用到程序中。例如,需要指定在不同的操作系统上使用的配置参数。您可以通过一系列条件来实现这点,如下:
1 |
|
但是如果头文件比较多的时候,这么做是很不妥当的,预处理器使用宏来定义头文件的名称。这就是所谓的有条件引用。它不是用头文件的名称作为 #include 的直接参数,您只需要使用宏名称代替即可:
1 |
|
SYSTEM_H 会扩展,预处理器会查找 system_1.h,就像 #include 最初编写的那样。SYSTEM_H 可通过 -D 选项被您的 Makefile 定义。
C 强制类型转换
强制类型转换是把变量从一种类型转换为另一种数据类型。例如,如果您想存储一个 long 类型的值到一个简单的整型中,您需要把 long 类型强制转换为 int 类型。您可以使用强制类型转换运算符来把值显式地从一种类型转换为另一种类型,如下所示:
1 | (type_name) expression |
请看下面的实例,使用强制类型转换运算符把一个整数变量除以另一个整数变量,得到一个浮点数:
1 |
|
当上面的代码被编译和执行时,它会产生下列结果:
1 | Value of mean : 3.400000 |
这里要注意的是强制类型转换运算符的优先级大于除法,因此 sum 的值首先被转换为 double 型,然后除以 count,得到一个类型为 double 的值。
类型转换可以是隐式的,由编译器自动执行,也可以是显式的,通过使用强制类型转换运算符来指定。在编程时,有需要类型转换的时候都用上强制类型转换运算符,是一种良好的编程习惯。
整数提升
整数提升是指把小于 int 或 unsigned int 的整数类型转换为 int 或 unsigned int 的过程。请看下面的实例,在 int 中添加一个字符:
1 |
|
当上面的代码被编译和执行时,它会产生下列结果:
1 | Value of sum : 116 |
在这里,sum 的值为 116,因为编译器进行了整数提升,在执行实际加法运算时,把 ‘c’ 的值转换为对应的 ascii 值。
常用的算术转换
常用的算术转换是隐式地把值强制转换为相同的类型。编译器首先执行整数提升,如果操作数类型不同,则它们会被转换为下列层次中出现的最高层次的类型:
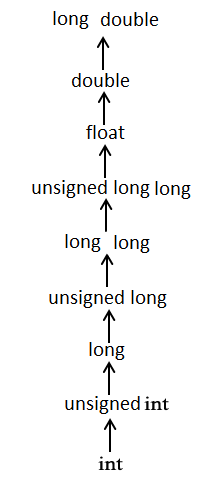
如果一个运算符两边的运算数类型不同,先要将其转换为相同的类型,即较低类型转换为较高类型,然后再参加运算,转换规则如下图所示。
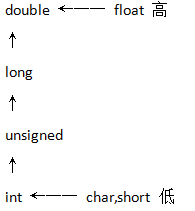
常用的算术转换不适用于赋值运算符、逻辑运算符 && 和 || 。
1 |
|
当上面的代码被编译和执行时,它会产生下列结果:
1 | Value of sum : 116.000000 |
在这里,c 首先被转换为整数,但是由于最后的值是 float 型的,所以会应用常用的算术转换,编译器会把 i 和 c 转换为浮点型,并把它们相加得到一个浮点数。
C 语言中 printf 输出 double 和 float 都可以用 %f 占位符 可以混用,而 double 可以额外用 %lf。
而 scanf 输入情况下 double 必须用 %lf,float 必须用 %f 不能混用。
C 错误处理
C 语言不提供对错误处理的直接支持,但是作为一种系统编程语言,它以返回值的形式允许您访问底层数据。在发生错误时,大多数的 C 或 UNIX 函数调用返回 1 或 NULL,同时会设置一个错误代码 errno,该错误代码是全局变量,表示在函数调用期间发生了错误。您可以在 errno.h 头文件中找到各种各样的错误代码。
所以,C 程序员可以通过检查返回值,然后根据返回值决定采取哪种适当的动作。开发人员应该在程序初始化时,把 errno 设置为 0,这是一种良好的编程习惯。0 值表示程序中没有错误。
errno、perror() 和 strerror()
C 语言提供了 perror() 和 strerror() 函数来显示与 errno 相关的文本消息。
- perror() 函数显示您传给它的字符串,后跟一个冒号、一个空格和当前 errno 值的文本表示形式。
- strerror() 函数,返回一个指针,指针指向当前 errno 值的文本表示形式。
让我们来模拟一种错误情况,尝试打开一个不存在的文件。您可以使用多种方式来输出错误消息,在这里我们使用函数来演示用法。另外有一点需要注意,您应该使用 stderr 文件流来输出所有的错误。
1 |
|
当上面的代码被编译和执行时,它会产生下列结果:
1 | 错误号: 2 |
被零除的错误
在进行除法运算时,如果不检查除数是否为零,则会导致一个运行时错误。
为了避免这种情况发生,下面的代码在进行除法运算前会先检查除数是否为零:
1 |
|
当上面的代码被编译和执行时,它会产生下列结果:
1 | 除数为 0 退出运行... |
程序退出状态
通常情况下,程序成功执行完一个操作正常退出的时候会带有值 EXIT_SUCCESS。在这里,EXIT_SUCCESS 是宏,它被定义为 0。
如果程序中存在一种错误情况,当您退出程序时,会带有状态值 EXIT_FAILURE,被定义为 -1。所以,上面的程序可以写成:
1 |
|
当上面的代码被编译和执行时,它会产生下列结果:
1 | quotient 变量的值为 : 4 |
C 递归
递归指的是在函数的定义中使用函数自身的方法。
语法格式如下:
1 | void recursion() |
C 语言支持递归,即一个函数可以调用其自身。但在使用递归时,程序员需要注意定义一个从函数退出的条件,否则会进入死循环。
递归函数在解决许多数学问题上起了至关重要的作用,比如计算一个数的阶乘、生成斐波那契数列,等等。
递归是一个简洁的概念,同时也是一种很有用的手段。但是,使用递归是要付出代价的。与直接的语句(如while循环)相比,递归函数会耗费更多的运行时间,并且要占用大量的栈空间。递归函数每次调用自身时,都需要把它的状态存到栈中,以便在它调用完自身后,程序可以返回到它原来的状态。未经精心设计的递归函数总是会带来麻烦。
C 可变参数
有时,您可能会碰到这样的情况,您希望函数带有可变数量的参数,而不是预定义数量的参数。C 语言为这种情况提供了一个解决方案,它允许您定义一个函数,能根据具体的需求接受可变数量的参数。
请注意,函数 func() 最后一个参数写成省略号,即三个点号(…),省略号之前的那个参数是 int,代表了要传递的可变参数的总数。为了使用这个功能,您需要使用 stdarg.h 头文件,该文件提供了实现可变参数功能的函数和宏。具体步骤如下:
- 定义一个函数,最后一个参数为省略号,省略号前面可以设置自定义参数。
- 在函数定义中创建一个 va_list 类型变量,该类型是在 stdarg.h 头文件中定义的。
- 使用 int 参数和 va_start 宏来初始化 va_list 变量为一个参数列表。宏 va_start 是在 stdarg.h 头文件中定义的。
- 使用 va_arg 宏和 va_list 变量来访问参数列表中的每个项。
- 使用宏 va_end 来清理赋予 va_list 变量的内存。
现在让我们按照上面的步骤,来编写一个带有可变数量参数的函数,并返回它们的平均值:
1 |
|
当上面的代码被编译和执行时,它会产生下列结果。应该指出的是,函数 average() 被调用两次,每次第一个参数都是表示被传的可变参数的总数。省略号被用来传递可变数量的参数。
1 | Average of 2, 3, 4, 5 = 3.500000 |
C 函数要在程序中用到以下这些宏:
1 | void va_start( va_list arg_ptr, prev_param ); |
va_list: 用来保存宏va_start、va_arg和va_end所需信息的一种类型。为了访问变长参数列表中的参数,必须声明 va_list 类型的一个对象,定义: typedef char * va_list;
va_start: 访问变长参数列表中的参数之前使用的宏,它初始化用 va_list 声明的对象,初始化结果供宏 va_arg 和 va_end 使用;
va_arg: 展开成一个表达式的宏,该表达式具有变长参数列表中下一个参数的值和类型。每次调用 va_arg 都会修改用 va_list 声明的对象,从而使该对象指向参数列表中的下一个参数;
va_end: 该宏使程序能够从变长参数列表用宏 va_start 引用的函数中正常返回。
va 在这里是 variable-argument(可变参数) 的意思。
这些宏定义在 stdarg.h 中,所以用到可变参数的程序应该包含这个头文件。
下面我们写一个简单的可变参数的函数,改函数至少有一个整数参数,第二个参数也是整数,是可选的。函数只是打印这两个参数的值。
1 |
|
从这个函数的实现可以看到,我们使用可变参数应该有以下步骤:
- 1)首先在函数里定义一个 va_list 型的变量,这里是 arg_ptr,这个变量是指向参数的指针。
- 2)然后用 va_start 宏初始化变量 arg_ptr,这个宏的第二个参数是第一个可变参数的前一个参数,是一个固定的参数。
- 3)然后用 va_arg 返回可变的参数,并赋值给整数 j。va_arg 的第二个参数是你要返回的参数的类型,这里是int型。
- 4)最后用 va_end 宏结束可变参数的获取。然后你就可以在函数里使用第二个参数了。如果函数有多个可变参数的,依次调用 va_arg 获取各个参数。