PWN入门到入狱-Heap
堆的漏洞利用核心就是劫持堆分配的位置,使程序把堆分配到我们指定的地址然后填入数据,造成代码与数据的混淆。
堆溢出
堆溢出是指程序向某个堆块中写入的字节数超过了堆块本身可使用的字节数(之所以是可使用而不是用户申请的字节数,是因为堆管理器会对用户所申请的字节数进行调整,这也导致可利用的字节数都不小于用户申请的字节数),因而导致了数据溢出,并覆盖到物理相邻的高地址的下一个堆块。
堆溢出漏洞发生的基本前提是
- 程序向堆上写入数据。
- 写入的数据大小没有被良好地控制。
一般来说,我们利用堆溢出的策略是
1.覆盖与其物理相邻的下一个 chunk的内容。
- prev_size
- size,主要有三个比特位,以及该堆块真正的大小。
- NON_MAIN_ARENA
- IS_MAPPED
- PREV_INUSE
- the True chunk size
- chunk content,从而改变程序固有的执行流。
2.利用堆中的机制(如 unlink 等 )来实现任意地址写入( Write-Anything-Anywhere)或控制堆块中的内容等效果,从而来控制程序的执行流。
堆溢出中比较重要的几个步骤:
寻找堆分配函数
通常来说堆是通过调用 glibc 函数 malloc 进行分配的,在某些情况下会使用 calloc 分配。calloc 与 malloc 的区别是 calloc 在分配后会自动进行清空,这对于某些信息泄露漏洞的利用来说是致命的。
1 | calloc(0x20); |
除此之外,还有一种分配是经由 realloc 进行的,realloc 函数可以身兼 malloc 和 free 两个函数的功能。
1 |
|
realloc 的操作并不是像字面意义上那么简单,其内部会根据不同的情况进行不同操作
- 当 realloc(ptr,size) 的 size 不等于 ptr 的 size 时
- 如果申请 size > 原来 size
- 如果 chunk 与 top chunk 相邻,直接扩展这个 chunk 到新 size 大小
- 如果 chunk 与 top chunk 不相邻,相当于 free(ptr),malloc(new_size)
- 如果申请 size < 原来 size
- 如果相差不足以容得下一个最小 chunk(64 位下 32 个字节,32 位下 16 个字节),则保持不变
- 如果相差可以容得下一个最小 chunk,则切割原 chunk 为两部分,free 掉后一部分
- 如果申请 size > 原来 size
- 当 realloc(ptr,size) 的 size 等于 0 时,相当于 free(ptr)
- 当 realloc(ptr,size) 的 size 等于 ptr 的 size,不进行任何操作
寻找危险函数
通过寻找危险函数,我们快速确定程序是否可能有堆溢出,以及有的话,堆溢出的位置在哪里。
常见的危险函数如下
- 输入
- gets,直接读取一行,忽略
'\x00' - scanf
- vscanf
- gets,直接读取一行,忽略
- 输出
- sprintf
- 字符串
- strcpy,字符串复制,遇到
'\x00'停止 - strcat,字符串拼接,遇到
'\x00'停止 - bcopy
- strcpy,字符串复制,遇到
确定填充长度
这一部分主要是计算我们开始写入的地址与我们所要覆盖的地址之间的距离。 一个常见的误区是 malloc 的参数等于实际分配堆块的大小,但是事实上 ptmalloc 分配出来的大小是对齐的。这个长度一般是字长的 2 倍,比如 32 位系统是 8 个字节,64 位系统是 16 个字节。但是对于不大于 2 倍字长的请求,malloc 会直接返回 2 倍字长的块也就是最小 chunk,比如 64 位系统执行malloc(0)会返回用户区域为 16 字节的块。
1 | chunk=malloc(0); |
注意用户区域的大小不等于 chunk_head.size,chunk_head.size = 用户区域大小 + 2 * 字长
还有一点是之前所说的用户申请的内存大小会被修改,其有可能会使用与其物理相邻的下一个 chunk 的 prev_size 字段储存内容。回头再来看下之前的示例代码
1 |
|
观察如上代码,我们申请的 chunk 大小是 24 个字节。但是我们将其编译为 64 位可执行程序时,实际上分配的内存会是 16 个字节而不是 24 个。
1 | 0x602000: 0x0000000000000000 0x0000000000000021 |
16 个字节的空间是如何装得下 24 个字节的内容呢?答案是借用了下一个块的 pre_size 域。我们可来看一下用户申请的内存大小与 glibc 中实际分配的内存大小之间的转换。
1 | /* pad request bytes into a usable size -- internal version */ |
当 req=24 时,request2size(24)=32。而除去 chunk 头部的 16 个字节。实际上用户可用 chunk 的字节数为 16。而根据我们前面学到的知识可以知道 chunk 的 pre_size 仅当它的前一块处于释放状态时才起作用。所以用户这时候其实还可以使用下一个 chunk 的 prev_size 字段,正好 24 个字节。实际上 ptmalloc 分配内存是以双字为基本单位,以 64 位系统为例,分配出来的空间是 16 的整数倍,即用户申请的 chunk 都是 16 字节对齐的。
堆中的 Off-By系列
严格来说 off-by-one 漏洞是一种特殊的溢出漏洞,off-by-one 指程序向缓冲区中写入时,写入的字节数超过了这个缓冲区本身所申请的字节数并且只越界了一个字节。
off-by-one 漏洞原理
off-by-one 是指单字节缓冲区溢出,这种漏洞的产生往往与边界验证不严和字符串操作有关,当然也不排除写入的 size 正好就只多了一个字节的情况。其中边界验证不严通常包括
- 使用循环语句向堆块中写入数据时,循环的次数设置错误(这在 C 语言初学者中很常见)导致多写入了一个字节。
- 字符串操作不合适
一般来说,单字节溢出被认为是难以利用的,但是因为 Linux 的堆管理机制 ptmalloc 验证的松散性,基于 Linux 堆的 off-by-one 漏洞利用起来并不复杂,并且威力强大。 此外,需要说明的一点是 off-by-one 是可以基于各种缓冲区的,比如栈、bss 段等等,但是堆上(heap based) 的 off-by-one 是 CTF 中比较常见的。我们这里仅讨论堆上的 off-by-one 情况。
off-by-one 利用思路
1.溢出字节为可控制任意字节:通过修改大小造成块结构之间出现重叠,从而泄露其他块数据,或是覆盖其他块数据。也可使用 NULL 字节溢出的方法
2.溢出字节为 NULL 字节:在 size 为 0x100 的时候,溢出 NULL 字节可以使得 prev_in_use 位被清,这样前块会被认为是 free 块。(1) 这时可以选择使用 unlink 方法(见 unlink 部分)进行处理。(2) 另外,这时 prev_size 域就会启用,就可以伪造 prev_size ,从而造成块之间发生重叠。此方法的关键在于 unlink 的时候没有检查按照 prev_size 找到的块的大小与prev_size 是否一致。
最新版本代码中,已加入针对 2 中后一种方法的 check ,但是在 2.28 及之前版本并没有该 check 。
1 | /* consolidate backward */ |
off-by-one的示例
1 | int my_gets(char *ptr,int size) |
1 | int main(void) |
程序乍看上去没有任何问题(不考虑栈溢出),可能很多人在实际的代码中也是这样写的。 但是 strlen 和 strcpy 的行为不一致却导致了 off-by-one 的发生。 strlen 是我们很熟悉的计算 ascii 字符串长度的函数,这个函数在计算字符串长度时是不把结束符 '\x00' 计算在内的,但是 strcpy 在复制字符串时会拷贝结束符 '\x00' 。这就导致了我们向 chunk1 中写入了 25 个字节。
1 | 0x602000: 0x0000000000000000 0x0000000000000021 <=== chunk1 |
在我们输入’A’*24 后执行 strcpy
1 | 0x602000: 0x0000000000000000 0x0000000000000021 |
可以看到 next chunk 的 size 域低字节被结束符 '\x00' 覆盖,这种又属于 off-by-one 的一个分支称为 NULL byte off-by-one、off-by-NULL,我们在后面会看到 off-by-one 与 NULL byte off-by-one 在利用上的区别。 还是有一点就是为什么是低字节被覆盖呢,因为我们通常使用的 CPU 的字节序都是小端法的,比如一个 DWORD 值在使用小端法的内存中是这样储存的
1 | DWORD 0x41424344 |
在 libc-2.29 之后
由于这两行代码的加入
1 | if (__glibc_unlikely (chunksize(p) != prevsize)) |
由于我们难以控制一个真实 chunk 的 size 字段,所以传统的 off-by-null 方法失效。但是,只需要满足被 unlink 的 chunk 和下一个 chunk 相连,所以仍然可以伪造 fake_chunk。
伪造的方式就是使用 large bin 遗留的 fd_nextsize 和 bk_nextsize 指针。以 fd_nextsize 为 fake_chunk 的 fd,bk_nextsize 为 fake_chunk 的 bk,这样我们可以完全控制该 fake_chunk 的 size 字段(这个过程会破坏原 large bin chunk 的 fd 指针,但是没有关系),同时还可以控制其 fd(通过部分覆写 fd_nextsize)。通过在后面使用其他的 chunk 辅助伪造,可以通过该检测。
然后只需要通过 unlink 的检测就可以了,也就是 fd->bk == p && bk->fd == p
如果 large bin 中仅有一个 chunk,那么该 chunk 的两个 nextsize 指针都会指向自己,如下
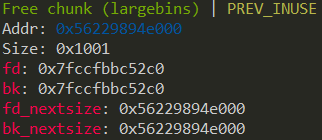
我们可以控制 fd_nextsize 指向堆上的任意地址,可以容易地使之指向一个 fastbin + 0x10 - 0x18,而 fastbin 中的 fd 也会指向堆上的一个地址,通过部分覆写该指针也可以使该指针指向之前的 large bin + 0x10,这样就可以通过 fd->bk == p 的检测。
由于 bk_nextsize 我们无法修改,所以 bk->fd 必然在原先的 large bin chunk 的 fd 指针处(这个 fd 被我们破坏了)。通过 fastbin 的链表特性可以做到修改这个指针且不影响其他的数据,再部分覆写之就可以通过 bk->fd==p 的检测了。
然后通过 off-by-one 向低地址合并就可以实现 chunk overlapping 了,之后可以 leak libc_base 和 堆地址,tcache 打 __free_hook 即可。
Chunk Extend and Overlapping
chunk extend 是堆漏洞的一种常见利用手法,通过 extend 可以实现 chunk overlapping 的效果。这种利用方法需要以下的时机和条件:
- 程序中存在基于堆的漏洞
- 漏洞可以控制 chunk header 中的数据
原理
chunk extend 技术能够产生的原因在于 ptmalloc 在对堆 chunk 进行操作时使用的各种宏。
在 ptmalloc 中,获取 chunk 块大小的操作如下
1 | /* Get size, ignoring use bits */ |
一种是直接获取 chunk 的大小,不忽略掩码部分,另外一种是忽略掩码部分。
在 ptmalloc 中,获取下一 chunk 块地址的操作如下
1 | /* Ptr to next physical malloc_chunk. */ |
即通过 malloc_chunk->prev_size 获取前一块大小,然后使用本 chunk 地址减去所得大小。
在 ptmalloc,判断当前 chunk 是否是 use 状态的操作如下:
1 |
|
即查看下一 chunk 的 prev_inuse 域,而下一块地址又如我们前面所述是根据当前 chunk 的 size 计算得出的。
通过上面几个宏可以看出,ptmalloc 通过 chunk header 的数据判断 chunk 的使用情况和对 chunk 的前后块进行定位。简而言之,chunk extend 就是通过控制 size 和 pre_size 域来实现跨越块操作从而导致 overlapping 的。
与 chunk extend 类似的还有一种称为 chunk shrink 的操作。这里只介绍 chunk extend 的利用。
Unlink
Unlink原理
- 简介
俗称脱链,就是将链表处的free堆块unsorted bin中脱离出来,然后和物理地址相邻的新free的堆块合并成大堆块(向前合并或者向后合并),再放入到unsorted bin中
- 危害原理
通过伪造free状态的fake_chunk,伪造fd指针和bk指针,通过绕过unlink的检测实现unlink,unlink就会往ptr(已经合并的堆块)所在的位置写入ptr-0x18,从而实现任意地址写的漏洞
- 漏洞产生原因
- off-by-null、off-by-one、堆溢出,修改了堆块的使用标志位
- UAF ,可修改 free 状态下 smallbin 或是 unsorted bin 的 fd 和 bk 指针
两个条件:修改标志位(使用状态变成free状态);修改fd、bk指针绕过检测,(未开启PIE)
- 思路
设指向可 UAF chunk 的指针的地址为 ptr
- 修改 fd 为 ptr - 0x18
- 修改 bk 为 ptr - 0x10
- 触发 unlink
ptr 处的指针会变为 ptr - 0x18。
- 效果
使得已指向 UAF chunk 的指针 ptr 变为 ptr - 0x18
unlink的绕过&利用
1 | ptr=0x602300 # 准备合并的堆块的位置 |
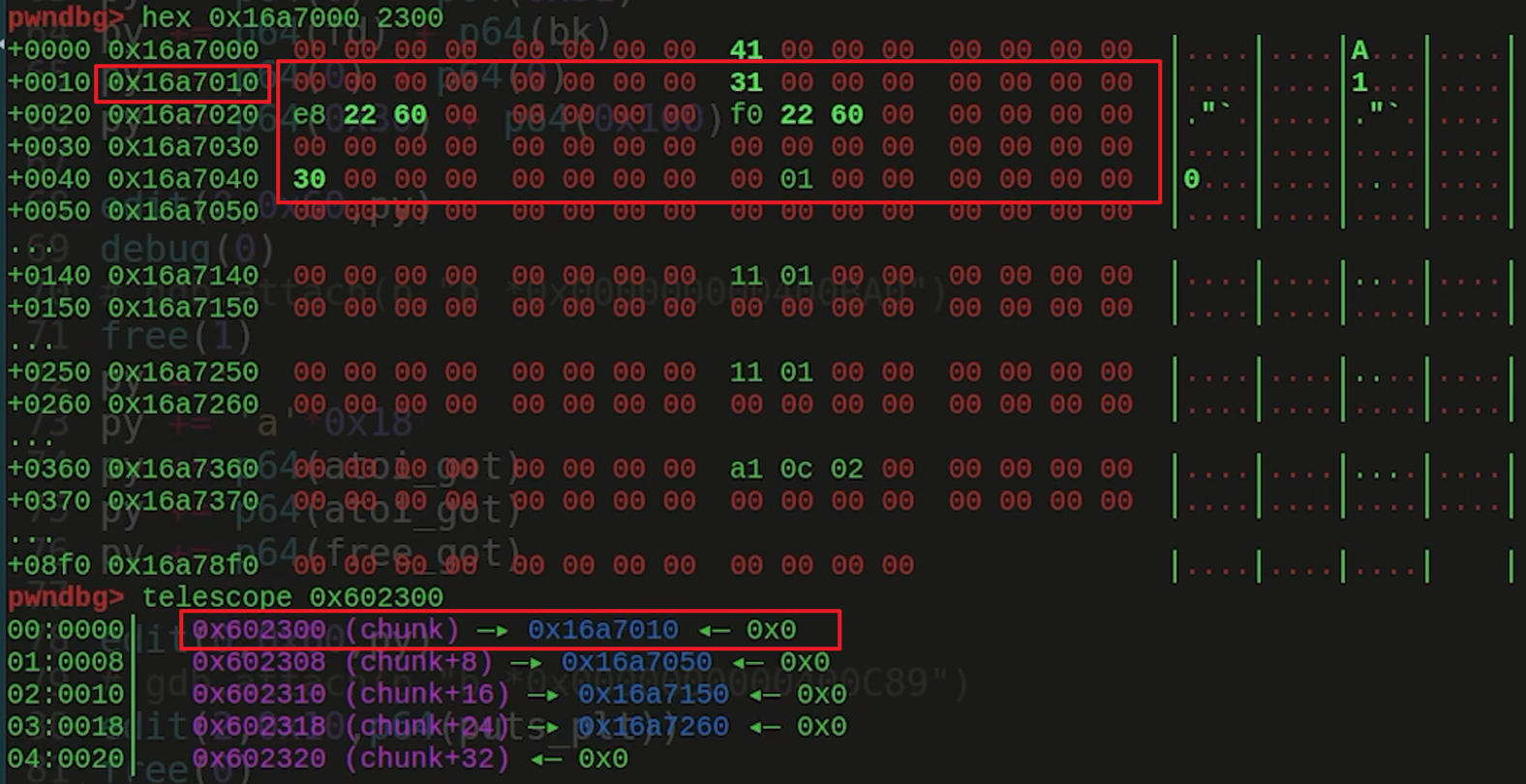
free(1)后
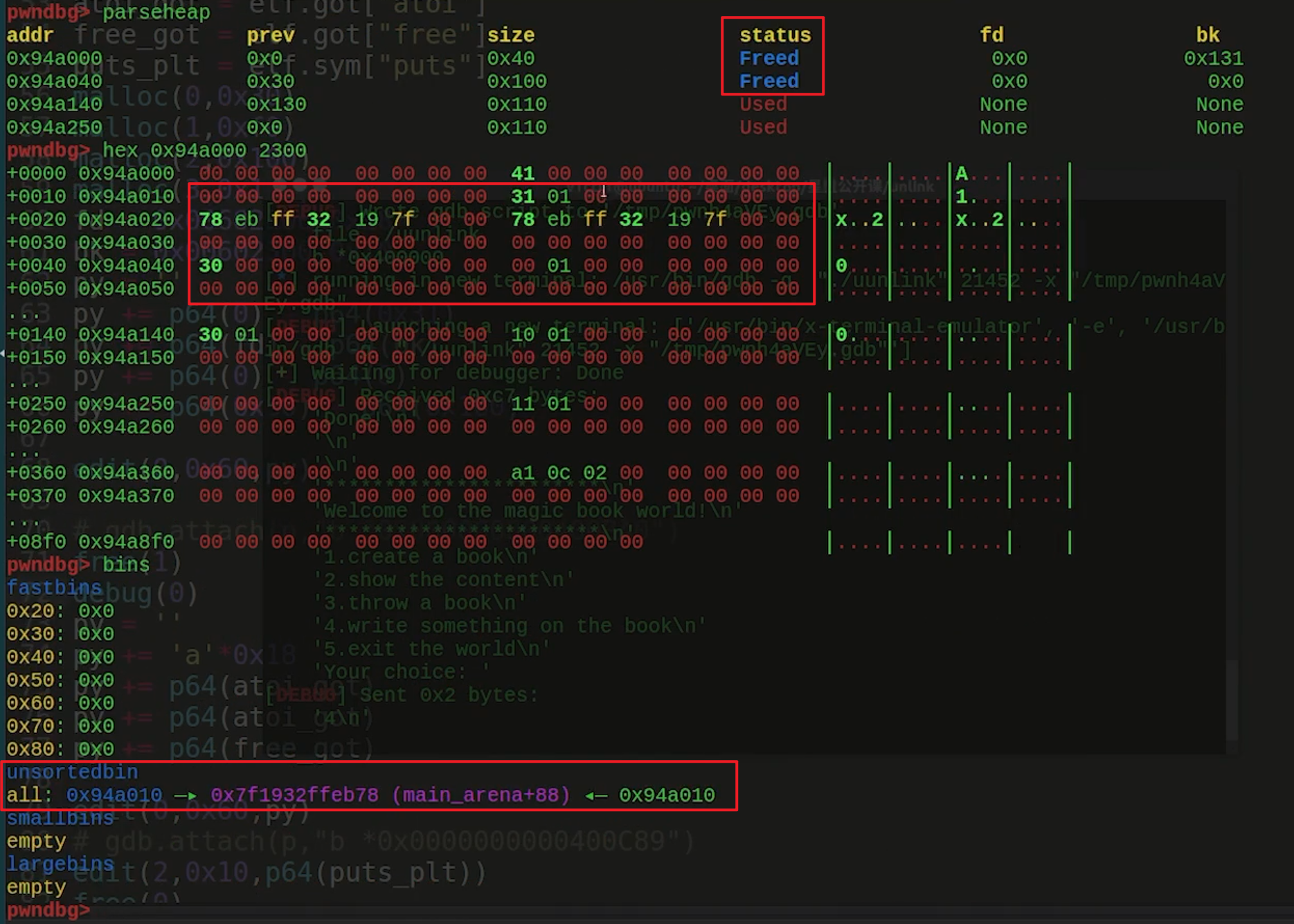
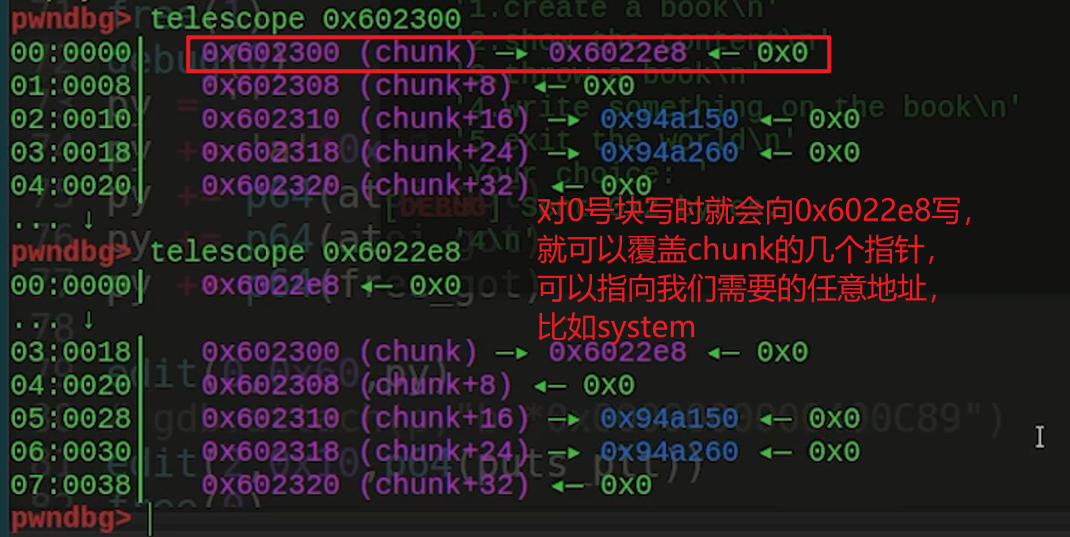
对0号块写时就会向0x6022e8写,就可以覆盖chunk的几个指针,可以指向我们需要的任意地址,比如system,对这些chunk操作就可以操作到对应位置。
1 | py=b'a'*0x18 |

1 | edit(2,0x10,p64(puts_plt)) |

1 | free(0) # puts(atoi_addr) |
1 | addr=u64(p.recv(6).ljust(8,b'\x00'))-libc.sym["atoi"] |
或者另一种
1 | edit(2,0x10,p64(system)) # free->system |
Use After Free
UAF原理
- 内存块被释放后,其对应的指针被设置为 NULL , 然后再次使用,自然程序会崩溃。
- 内存块被释放后,其对应的指针没有被设置为 NULL ,然后在它下一次被使用之前,没有代码对这块内存块进行修改,那么程序很有可能可以正常运转。
- 内存块被释放后,其对应的指针没有被设置为 NULL,但是在它下一次使用之前,有代码对这块内存进行了修改,那么当程序再次使用这块内存时,就很有可能会出现奇怪的问题。
而我们一般所指的 Use After Free 漏洞主要是后两种。此外,我们一般称被释放后没有被设置为 NULL 的内存指针为 dangling pointer。
Fastbin attack
fastbin attack 是一类漏洞的利用方法,是指所有基于 fastbin 机制的漏洞利用方法。这类利用的前提是:
- 存在堆溢出、use-after-free 等能控制 chunk 内容的漏洞
- 漏洞发生于 fastbin 类型的 chunk 中
漏洞成因
fastbin通过单链表连接,修改其fd即可控制下一个申请的地址。
并且由 fastbin 管理的 chunk 即使被释放,其 next_chunk 的 prev_inuse 位也不会被清空。
条件:size位与fastbin对应。
攻击方法分类
- Fastbin Double Free
- House of Spirit
- Alloc to Stack
- Arbitrary Alloc
其中,前两种主要漏洞侧重于利用 free 函数释放真的 chunk 或伪造的 chunk,然后再次申请 chunk 进行攻击,后两种侧重于故意修改 fd 指针,直接利用 malloc 申请指定位置 chunk 进行攻击。
Fastbin Double Free
Fastbin Double Free 是指 fastbin 的 chunk 可以被多次释放,因此可以在 fastbin 链表中存在多次。这样导致的后果是多次分配可以从 fastbin 链表中取出同一个堆块,相当于多个指针指向同一个堆块,结合堆块的数据内容可以实现类似于类型混淆 (type confused) 的效果。
Fastbin Double Free 能够成功利用主要有两部分的原因
- fastbin 的堆块被释放后 next_chunk 的 pre_inuse 位不会被清空
- fastbin 在执行 free 的时候仅验证了 main_arena 直接指向的块,即链表指针头部的块。对于链表后面的块,并没有进行验证。
通过 fastbin double free 我们可以使用多个指针控制同一个堆块,这可以用于篡改一些堆块中的关键数据域或者是实现类似于类型混淆的效果。 如果更进一步修改 fd 指针,则能够实现任意地址分配堆块的效果 (首先要通过验证),这就相当于任意地址写任意值的效果。
House of Spirit
House of Spirit 是 the Malloc Maleficarum 中的一种技术。
该技术的核心在于在目标位置处伪造 fastbin chunk,并将其释放,从而达到分配指定地址的 chunk 的目的。
要想构造 fastbin fake chunk,并且将其释放时,可以将其放入到对应的 fastbin 链表中,需要绕过一些必要的检测,即
- fake chunk 的 ISMMAP 位不能为 1,因为 free 时,如果是 mmap 的 chunk,会单独处理。
- fake chunk 地址需要对齐, MALLOC_ALIGN_MASK
- fake chunk 的 size 大小需要满足对应的 fastbin 的需求,同时也得对齐。
- fake chunk 的 next chunk 的大小不能小于
2 * SIZE_SZ,同时也不能大于av->system_mem。 - fake chunk 对应的 fastbin 链表头部不能是该 fake chunk,即不能构成 double free 的情况。
至于为什么要绕过这些检测,可以参考 free 部分的源码。
使用该技术分配 chunk 到指定地址,其实并不需要修改指定地址的任何内容,关键是要能够修改指定地址的前后的内容使其可以绕过对应的检测。
Alloc to Stack
该技术的核心点在于劫持 fastbin 链表中 chunk 的 fd 指针,把 fd 指针指向我们想要分配的栈上,从而实现控制栈中的一些关键数据,比如返回地址等。
这次我们把 fake_chunk 置于栈中称为 stack_chunk,同时劫持了 fastbin 链表中 chunk 的 fd 值,通过把这个 fd 值指向 stack_chunk 就可以实现在栈中分配 fastbin chunk。
通过该技术我们可以把 fastbin chunk 分配到栈中,从而控制返回地址等关键数据。要实现这一点我们需要劫持 fastbin 中 chunk 的 fd 域,把它指到栈上,当然同时需要栈上存在有满足条件的 size 值。
Arbitrary Alloc
Arbitrary Alloc 其实与 Alloc to stack 是完全相同的,唯一的区别是分配的目标不再是栈中。 事实上只要满足目标地址存在合法的 size 域(这个 size 域是构造的,还是自然存在的都无妨),我们可以把 chunk 分配到任意的可写内存中,比如 bss、heap、data、stack 等等。
我们使用字节错位来实现直接分配 fastbin 到_malloc_hook 的位置,相当于覆盖 _malloc_hook 来控制程序流程。
Arbitrary Alloc 在 CTF 中用地更加频繁。我们可以利用字节错位等方法来绕过 size 域的检验,实现任意地址分配 chunk,最后的效果也就相当于任意地址写任意值。
Unsorted Bin Attack
Unsorted Bin Attack,顾名思义,该攻击与 Glibc 堆管理中的的 Unsorted Bin 的机制紧密相关。
Unsorted Bin Attack 被利用的前提是控制 Unsorted Bin Chunk 的 bk 指针。
Unsorted Bin Attack 可以达到的效果是实现修改任意地址值为一个较大的数值。
基本来源
- 当一个较大的 chunk 被分割成两半后,如果剩下的部分大于 MINSIZE,就会被放到 unsorted bin 中。
- 释放一个不属于 fast bin 的 chunk,并且该 chunk 不和 top chunk 紧邻时,该 chunk 会被首先放到 unsorted bin 中。
- 当进行 malloc_consolidate 时,可能会把合并后的 chunk 放到 unsorted bin 中,如果不是和 top chunk 近邻的话。
基本使用情况
- Unsorted Bin 在使用的过程中,采用的遍历顺序是 FIFO,即插入的时候插入到 unsorted bin 的头部,取出的时候从链表尾获取。
- 在程序 malloc 时,如果在 fastbin,small bin 中找不到对应大小的 chunk,就会尝试从 Unsorted Bin 中寻找 chunk。如果取出来的 chunk 大小刚好满足,就会直接返回给用户,否则就会把这些 chunk 分别插入到对应的 bin 中。
Unsorted Bin Leak
Unsorted Bin 的结构
Unsorted Bin 在管理时为循环双向链表,若 Unsorted Bin 中有两个 bin,那么该链表结构如下
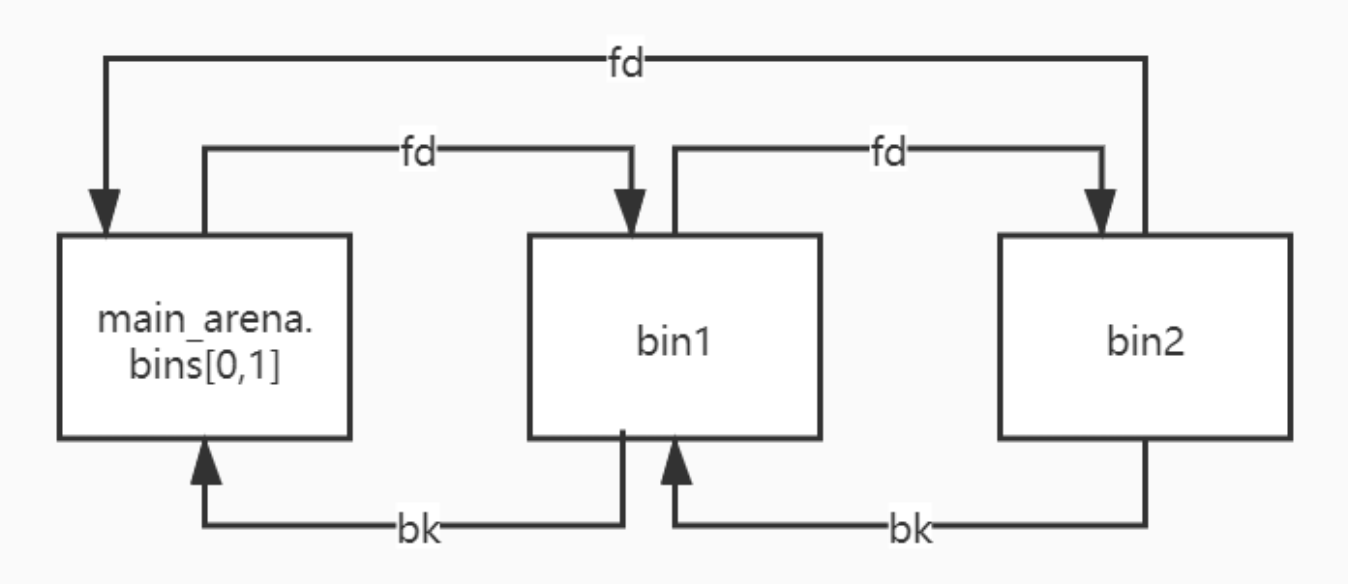
我们可以看到,在该链表中必有一个节点的 fd 指针会指向 main_arena 结构体内部。
Leak 原理
如果我们可以把正确的 fd 指针 leak 出来,就可以获得一个与 main_arena 有固定偏移的地址,这个偏移可以通过调试得出。而main_arena 是一个 struct malloc_state 类型的全局变量,是 ptmalloc 管理主分配区的唯一实例。说到全局变量,立马可以想到他会被分配在 .data 或者 .bss 等段上,那么如果我们有进程所使用的 libc 的 .so 文件的话,我们就可以获得 main_arena 与 libc 基地址的偏移,实现对 ASLR 的绕过。
那么如何取得 main_arena 与 libc 基址的偏移呢?这里提供两种思路。
通过 __malloc_trim 函数得出
在 malloc.c 中有这样一段代码
1 | int |
注意到 mstate ar_ptr = &main_arena; 这里对 main_arena 进行了访问,所以我们就可以通过 IDA 等工具分析出偏移了。
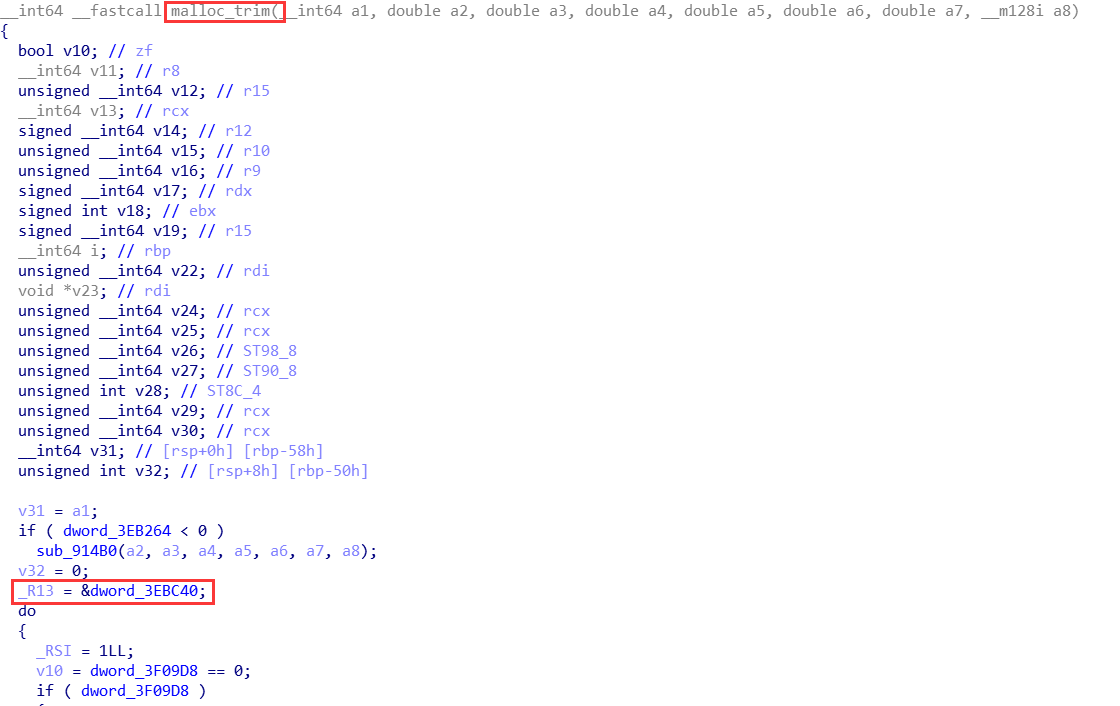
比如把 .so 文件放到 IDA 中,找到 malloc_trim 函数,就可以获得偏移了。
通过 __malloc_hook 直接算出
比较巧合的是,main_arena 和 __malloc_hook 的地址差是 0x10,而大多数的 libc 都可以直接查出 __malloc_hook 的地址,这样可以大幅减小工作量。以 pwntools 为例
1 | main_arena_offset = ELF("libc.so.6").symbols["__malloc_hook"] + 0x10 |
这样就可以获得 main_arena 与基地址的偏移了。
实现 Leak 的方法
一般来说,要实现 leak,需要有 UAF,将一个 chunk 放入 Unsorted Bin 中后再打出其 fd。一般的笔记管理题都会有 show 的功能,对处于链表尾的节点 show 就可以获得 libc 的基地址了。
特别的,CTF 中的利用,堆往往是刚刚初始化的,所以 Unsorted Bin 一般都是干净的,当里面只存在一个 bin 的时候,该 bin 的 fd 和 bk 都会指向 main_arena 中。
另外,如果我们无法做到访问链表尾,但是可以访问链表头,那么在 32 位的环境下,对链表头进行 printf 等往往可以把 fd 和 bk 一起输出出来,这个时候同样可以实现有效的 leak。然而在 64 位下,由于高地址往往为 \x00,很多输出函数会被截断,这个时候可能就难以实现有效 leak。
Unsorted Bin Attack 原理
在 glibc/malloc/malloc.c 中的 _int_malloc 有这么一段代码,当将一个 unsorted bin 取出的时候,会将 bck->fd 的位置写入本 Unsorted Bin 的位置。
1 | /* remove from unsorted list */ |
换而言之,如果我们控制了 bk 的值,我们就能将 unsorted_chunks (av) 写到任意地址。
Large Bin Attack
分配跟 large bin 有关的 chunk,要经过 fastbin,unsorted bin,small bin 的分配。
这种攻击方式主要利用的是 chunk 进入 bin 中的操作,在 malloc 的时候,遍历 unsorted bin 时,对每一个 chunk,若无法 exact-fit 分配或不满足切割分配的条件,就会将该 chunk 置入相应的 bin 中,而此过程中缺乏对 largebin 的跳表指针的检测。
以 2.33 版本的 libc 为例,从 4052 行开始就是对 largebin chunk 的入 bin 操作
1 | else |
在 2.29 及以下的版本中,根据 unsorted chunk 的大小不同
1 | fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim; |
在 unsorted chunk 小于链表中最小的 chunk 的时候会执行前一句,反之执行后一句。
由于两者大小相同的时候只会使用如下的方法插入,所以此时无法利用。
1 | if ((unsigned long) size |
所以有两种利用方法。
在 2.30 版本新加入了对 largebin 跳表的完整性检查,使 unsorted chunk 大于链表中最小的 chunk 时的利用失效,必须使 unsorted chunk 小于链表中最小的 chunk,通过
1 | victim->bk_nextsize->fd_nextsize = victim; |
实现利用,也就是将本 chunk 的地址写到 bk_nextsize + 0x20 处。
总结 large bin attack 的利用方法
large bin attack 是未来更深入的利用。现在我们来总结一下利用的条件:
- 可以修改一个 large bin chunk 的 data
- 从 unsorted bin 中来的 large bin chunk 要紧跟在被构造过的 chunk 的后面
- 通过 large bin attack 可以辅助 Tcache Stash Unlink+ 攻击
- 可以修改 _IO_list_all 便于伪造 _IO_FILE 结构体进行 FSOP。
Tcache attack
tcache 是 glibc 2.26 (ubuntu 17.10) 之后引入的一种技术,目的是提升堆管理的性能。但提升性能的同时舍弃了很多安全检查,也因此有了很多新的利用方式。
tcache 引入了两个新的结构体,tcache_entry 和 tcache_perthread_struct。
这其实和 fastbin 很像,但又不一样。
tcache_entry
1 | /* We overlay this structure on the user-data portion of a chunk when |
tcache_entry 用于链接空闲的 chunk 结构体,其中的 next 指针指向下一个大小相同的 chunk。
需要注意的是这里的 next 指向 chunk 的 user data,而 fastbin 的 fd 指向 chunk 开头的地址。
而且,tcache_entry 会复用空闲 chunk 的 user data 部分。
tcache_perthread_struct
1 | /* There is one of these for each thread, which contains the |
每个 thread 都会维护一个 tcache_perthread_struct,它是整个 tcache 的管理结构,一共有 TCACHE_MAX_BINS 个计数器和 TCACHE_MAX_BINS项 tcache_entry,其中
tcache_entry用单向链表的方式链接了相同大小的处于空闲状态(free 后)的 chunk,这一点上和 fastbin 很像。counts记录了tcache_entry链上空闲 chunk 的数目,每条链上最多可以有 7 个 chunk。
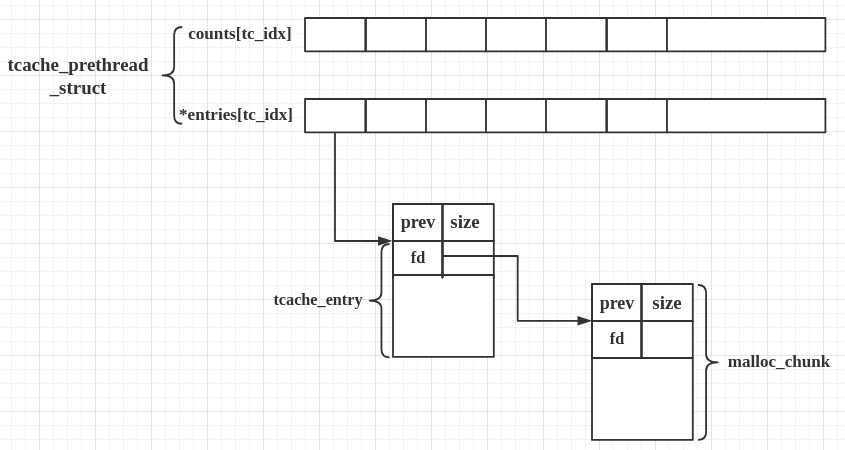
基本工作方式
- 第一次 malloc 时,会先 malloc 一块内存用来存放
tcache_perthread_struct。 - free 内存,且 size 小于 small bin size 时
- tcache 之前会放到 fastbin 或者 unsorted bin 中
- tcache 后:
- 先放到对应的 tcache 中,直到 tcache 被填满(默认是 7 个)
- tcache 被填满之后,再次 free 的内存和之前一样被放到 fastbin 或者 unsorted bin 中
- tcache 中的 chunk 不会合并(不取消 inuse bit)
- malloc 内存,且 size 在 tcache 范围内
- 先从 tcache 取 chunk,直到 tcache 为空
- tcache 为空后,从 bin 中找
- tcache 为空时,如果
fastbin/smallbin/unsorted bin中有 size 符合的 chunk,会先把fastbin/smallbin/unsorted bin中的 chunk 放到 tcache 中,直到填满。之后再从 tcache 中取;因此 chunk 在 bin 中和 tcache 中的顺序会反过来
其中有两个重要的函数, tcache_get() 和 tcache_put():
1 | static void |
这两个函数会在函数 _int_free 和 __libc_malloc 的开头被调用,其中 tcache_put 当所请求的分配大小不大于0x408并且当给定大小的 tcache bin 未满时调用。一个 tcache bin 中的最大块数mp_.tcache_count是7。
1 | /* This is another arbitrary limit, which tunables can change. Each |
在 tcache_get 中,仅仅检查了 tc_idx ,此外,我们可以将 tcache 当作一个类似于 fastbin 的单独链表,只是它的 check,并没有 fastbin 那么复杂,仅仅检查 tcache->entries[tc_idx] = e->next;
Tcache Usage
- 内存释放:
可以看到,在 free 函数的最先处理部分,首先是检查释放块是否页对齐及前后堆块的释放情况,便优先放入 tcache 结构中。
- 内存申请:
在内存分配的 malloc 函数中有多处,会将内存块移入 tcache 中。
(1)首先,申请的内存块符合 fastbin 大小时并且在 fastbin 内找到可用的空闲块时,会把该 fastbin 链上的其他内存块放入 tcache 中。
(2)其次,申请的内存块符合 smallbin 大小时并且在 smallbin 内找到可用的空闲块时,会把该 smallbin 链上的其他内存块放入 tcache 中。
(3)当在 unsorted bin 链上循环处理时,当找到大小合适的链时,并不直接返回,而是先放到 tcache 中,继续处理。
tcache 取出:在内存申请的开始部分,首先会判断申请大小块,在 tcache 是否存在,如果存在就直接从 tcache 中摘取,否则再使用_int_malloc 分配。
在循环处理 unsorted bin 内存块时,如果达到放入 unsorted bin 块最大数量,会立即返回。默认是 0,即不存在上限。
在循环处理 unsorted bin 内存块后,如果之前曾放入过 tcache 块,则会取出一个并返回。
Pwn Tcache
tcache poisoning
通过覆盖 tcache 中的 next,不需要伪造任何 chunk 结构即可实现 malloc 到任何地址。
tcache dup
类似 fastbin dup,不过利用的是 tcache_put() 的不严谨
1 | static __always_inline void |
可以看出,tcache_put() 的检查也可以忽略不计(甚至没有对 tcache->counts[tc_idx] 的检查),大幅提高性能的同时安全性也下降了很多。
因为没有任何检查,所以我们可以对同一个 chunk 多次 free,造成 cycliced list。
tcache perthread corruption
我们已经知道 tcache_perthread_struct 是整个 tcache 的管理结构,如果能控制这个结构体,那么无论我们 malloc 的 size 是多少,地址都是可控的。
因为 tcache_perthread_struct 也在堆上,因此这种方法一般只需要 partial overwrite 就可以达到目的。
tcache house of spirit
攻击之后的目的是,去控制栈上的内容,malloc 一块 chunk ,然后我们通过在栈上 fake 的 chunk,然后去 free 掉他,我们会发现Tcache 里就存放了一块 栈上的内容,我们之后只需 malloc,就可以控制这块内存。
smallbin unlink
在 smallbin 中包含有空闲块的时候,会同时将同大小的其他空闲块,放入 tcache 中,此时也会出现解链操作,但相比于 unlink 宏,缺少了链完整性校验。因此,原本 unlink 操作在该条件下也可以使用。
tcache stashing unlink attack
这种攻击利用的是 tcache bin 有剩余 (数量小于 TCACHE_MAX_BINS ) 时,同大小的 small bin 会放进 tcache 中 (这种情况可以用 calloc 分配同大小堆块触发,因为 calloc 分配堆块时不从 tcache bin 中选取)。在获取到一个 smallbin 中的一个 chunk 后会如果 tcache 仍有足够空闲位置,会将剩余的 small bin 链入 tcache ,在这个过程中只对第一个 bin 进行了完整性检查,后面的堆块的检查缺失。当攻击者可以写一个 small bin 的 bk 指针时,其可以在任意地址上写一个 libc 地址 (类似 unsorted bin attack 的效果)。构造得当的情况下也可以分配 fake chunk 到任意地址。
libc leak
在以前的 libc 版本中,我们只需这样:
1 |
|
但是在 2.26 之后的 libc 版本后,我们首先得先把 tcache 填满:
1 |
|
之后,我们就可以 leak libc 了。
1 | gdb-peda$ heapinfo |
House Of Einherjar
house of系列在近几年比赛中几乎用不到,
house of einherjar 是一种堆利用技术,由 Hiroki Matsukuma 提出。该堆利用技术可以强制使得 malloc 返回一个几乎任意地址的 chunk 。其主要在于滥用 free 中的后向合并操作(合并低地址的 chunk),从而使得尽可能避免碎片化。
此外,需要注意的是,在一些特殊大小的堆块中,off by one 不仅可以修改下一个堆块的 prev_size,还可以修改下一个堆块的 PREV_INUSE 比特位。
原理
后向合并操作
free 函数中的后向合并核心操作如下
1 | /* consolidate backward */ |
这里借用原作者的一张图片说明
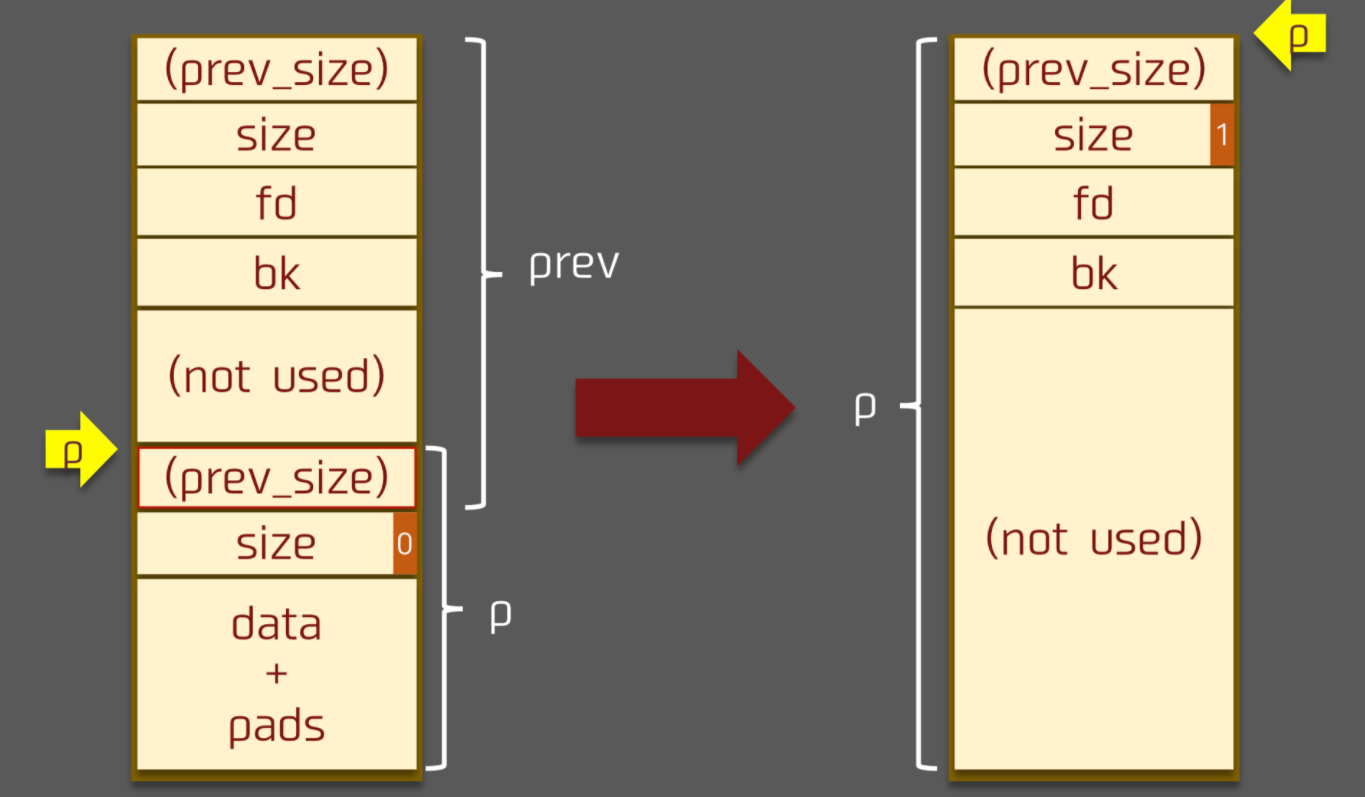
利用原理
这里我们就介绍该利用的原理。首先,在之前的堆的介绍中,我们可以知道以下的知识
- 两个物理相邻的 chunk 会共享
prev_size字段,尤其是当低地址的 chunk 处于使用状态时,高地址的 chunk 的该字段便可以被低地址的 chunk 使用。因此,我们有希望可以通过写低地址 chunk 覆盖高地址 chunk 的prev_size字段。 - 一个 chunk PREV_INUSE 位标记了其物理相邻的低地址 chunk 的使用状态,而且该位是和 prev_size 物理相邻的。
- 后向合并时,新的 chunk 的位置取决于
chunk_at_offset(p, -((long) prevsize))。
那么如果我们可以同时控制一个 chunk prev_size 与 PREV_INUSE 字段,那么我们就可以将新的 chunk 指向几乎任何位置。
利用过程
溢出前
假设溢出前的状态如下
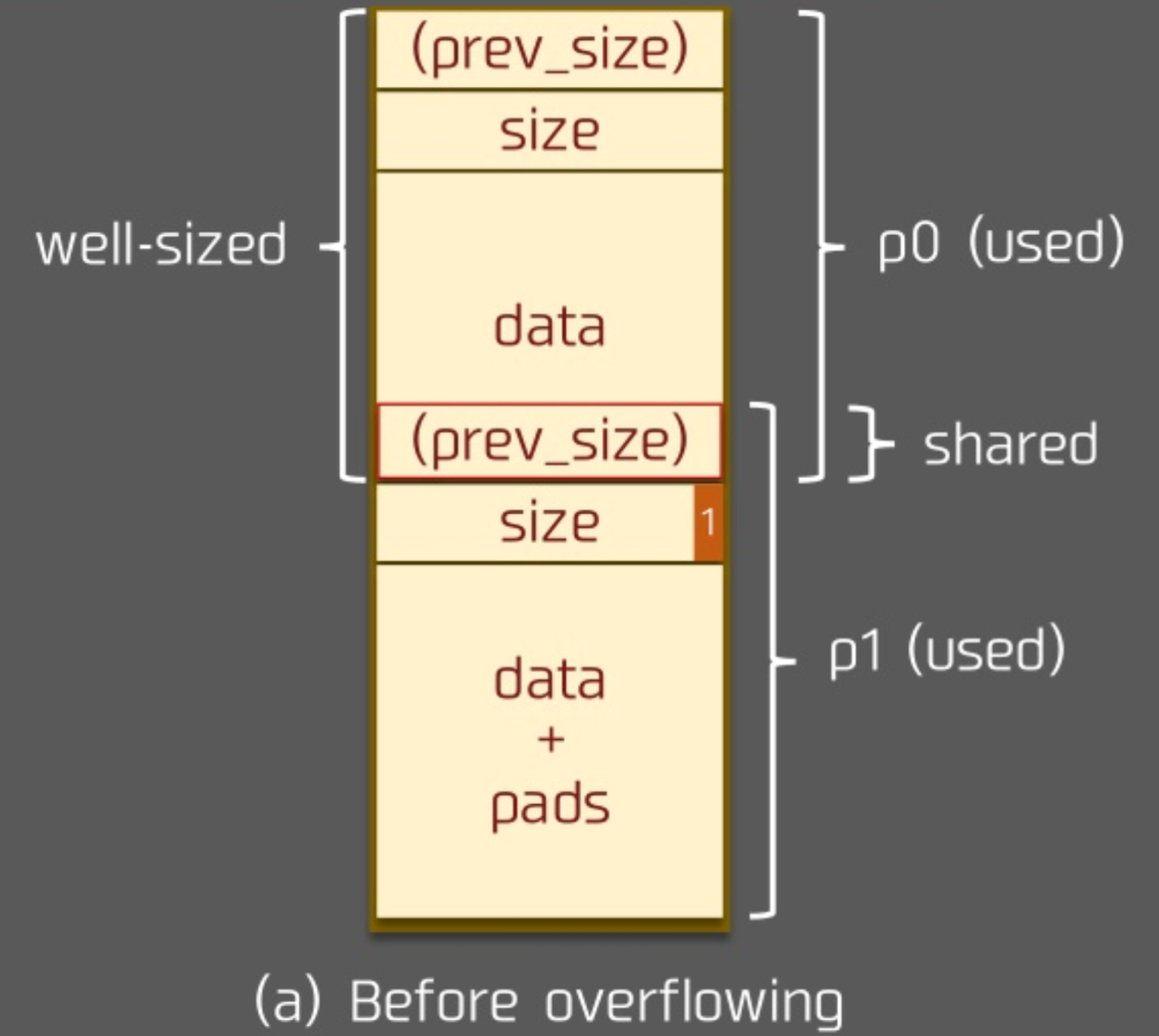
溢出
这里我们假设 p0 堆块一方面可以写 prev_size 字段,另一方面,存在 off by one 的漏洞,可以写下一个 chunk 的 PREV_INUSE 部分,那么
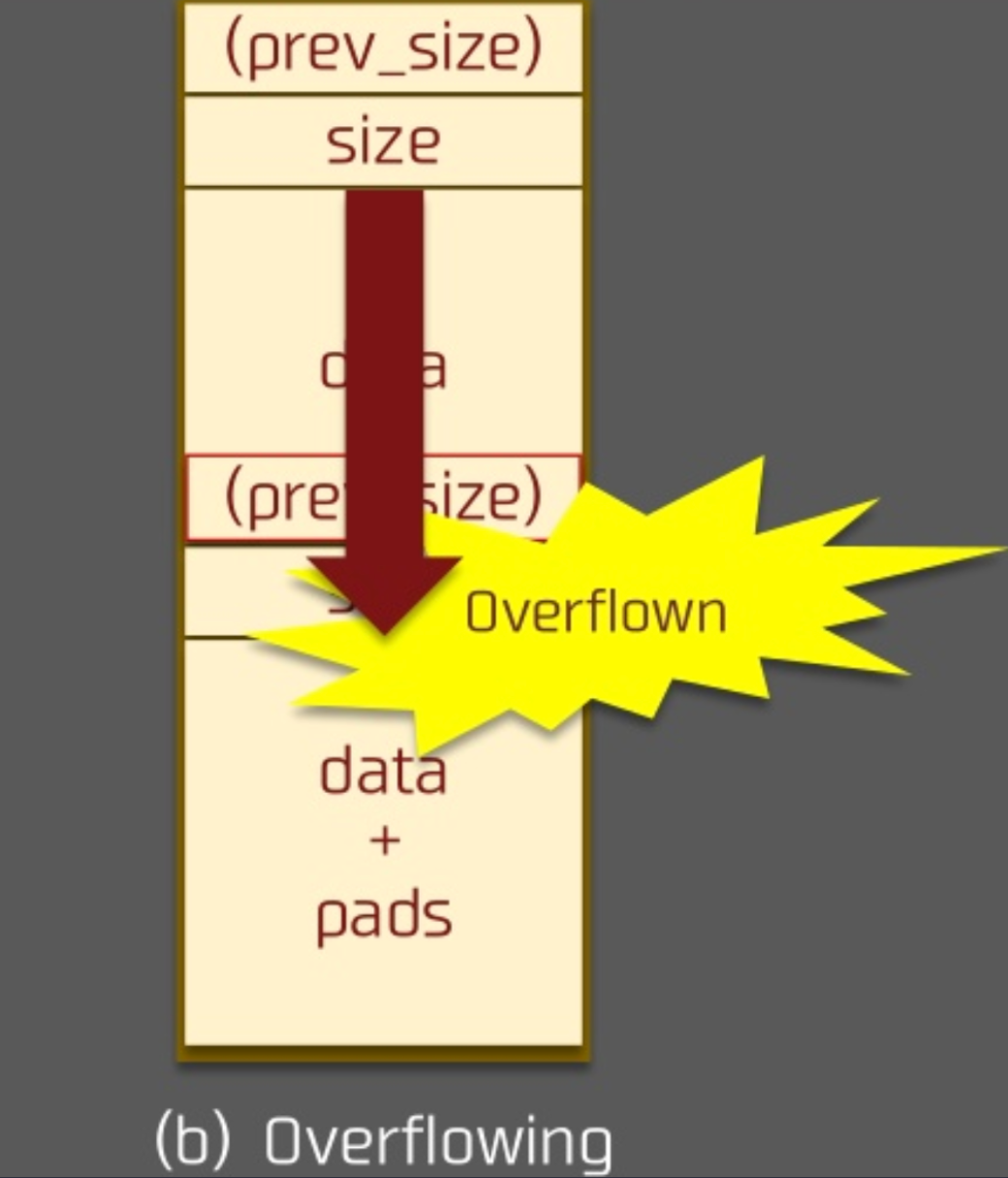
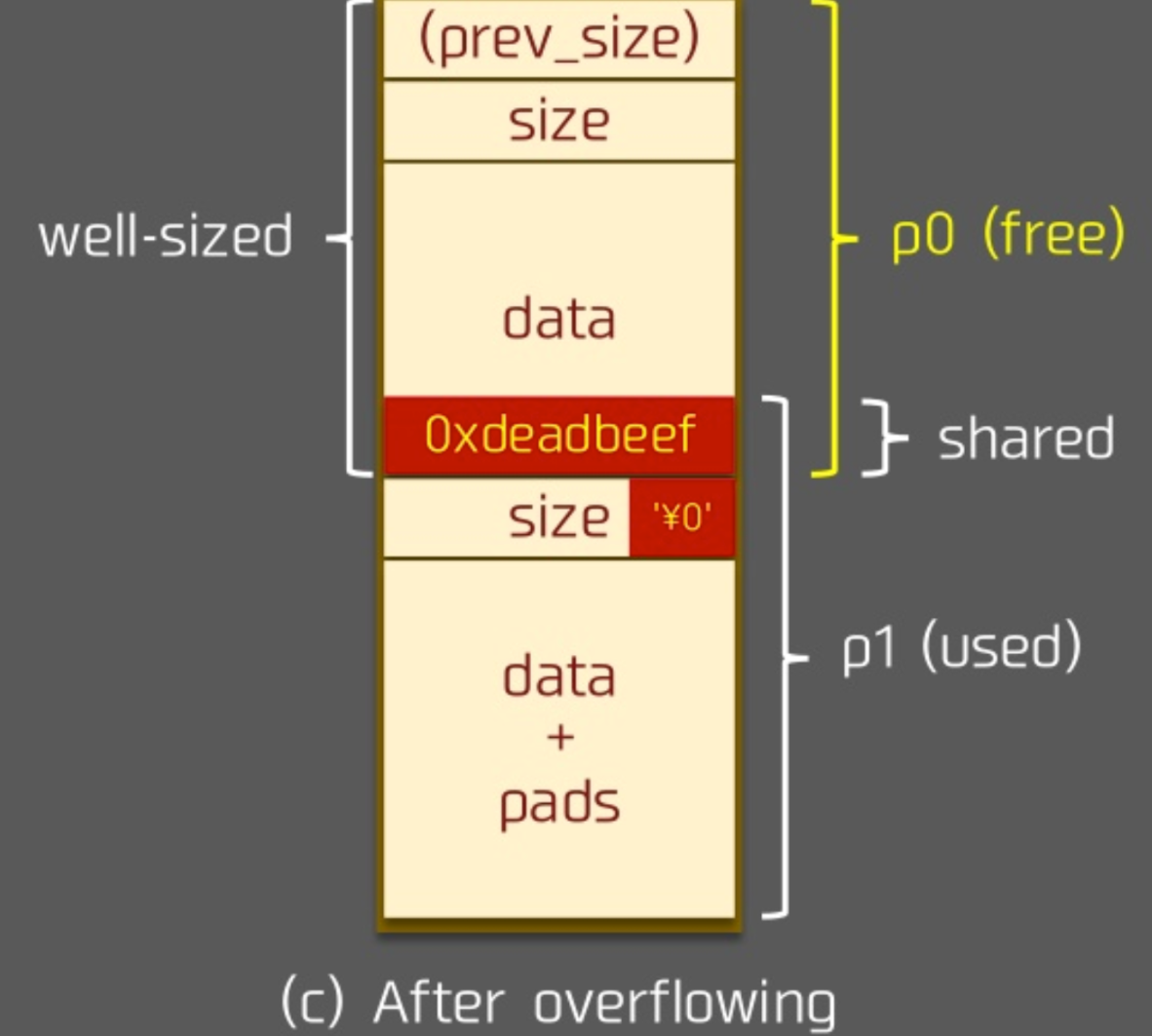
溢出后
假设我们将 p1 的 prev_size 字段设置为我们想要的目的 chunk 位置与 p1 的差值。在溢出后,我们释放 p1,则我们所得到的新的 chunk 的位置 chunk_at_offset(p1, -((long) prevsize)) 就是我们想要的 chunk 位置了。
当然,需要注意的是,由于这里会对新的 chunk 进行 unlink ,因此需要确保在对应 chunk 位置构造好了 fake chunk 以便于绕过 unlink 的检测。
总结
这里我们总结下这个利用技术需要注意的地方
- 需要有溢出漏洞可以写物理相邻的高地址的 prev_size 与 PREV_INUSE 部分。
- 我们需要计算目的 chunk 与 p1 地址之间的差,所以需要泄漏地址。
- 我们需要在目的 chunk 附近构造相应的 fake chunk,从而绕过 unlink 的检测。
其实,该技术与 chunk extend/shrink 技术比较类似。
House Of Force
原理
House Of Force 是一种堆利用方法,但是并不是说 House Of Force 必须得基于堆漏洞来进行利用。如果一个堆 (heap based) 漏洞想要通过 House Of Force 方法进行利用,需要以下条件:
- 能够以溢出等方式控制到 top chunk 的 size 域
- 能够自由地控制堆分配尺寸的大小
House Of Force 产生的原因在于 glibc 对 top chunk 的处理,根据前面堆数据结构部分的知识我们得知,进行堆分配时,如果所有空闲的块都无法满足需求,那么就会从 top chunk 中分割出相应的大小作为堆块的空间。
那么,当使用 top chunk 分配堆块的 size 值是由用户控制的任意值时会发生什么?答案是,可以使得 top chunk 指向我们期望的任何位置,这就相当于一次任意地址写。然而在 glibc 中,会对用户请求的大小和 top chunk 现有的 size 进行验证
1 | // 获取当前的top chunk,并计算其对应的大小 |
然而,如果可以篡改 size 为一个很大值,就可以轻松的通过这个验证,这也就是我们前面说的需要一个能够控制 top chunk size 域的漏洞。
1 | (unsigned long) (size) >= (unsigned long) (nb + MINSIZE) |
一般的做法是把 top chunk 的 size 改为 - 1,因为在进行比较时会把 size 转换成无符号数,因此 -1 也就是说 unsigned long 中最大的数,所以无论如何都可以通过验证。
1 | remainder = chunk_at_offset(victim, nb); |
之后这里会把 top 指针更新,接下来的堆块就会分配到这个位置,用户只要控制了这个指针就相当于实现任意地址写任意值 (write-anything-anywhere)。
与此同时,我们需要注意的是,topchunk 的 size 也会更新,其更新的方法如下
1 | victim = av->top; |
所以,如果我们想要下次在指定位置分配大小为 x 的 chunk,我们需要确保 remainder_size 不小于 x+ MINSIZE。
总结
其实 HOF 的利用要求还是相当苛刻的。
- 首先,需要存在漏洞使得用户能够控制 top chunk 的 size 域。
- 其次,需要用户能自由控制 malloc 的分配大小
- 第三,分配的次数不能受限制
其实这三点中第二点往往是最难办的,CTF 题目中往往会给用户分配堆块的大小限制最小和最大值使得不能通过 HOF 的方法进行利用。
House of Lore
概述
House of Lore 攻击与 Glibc 堆管理中的 Small Bin 的机制紧密相关。
House of Lore 可以实现分配任意指定位置的 chunk,从而修改任意地址的内存。
House of Lore 利用的前提是需要控制 Small Bin Chunk 的 bk 指针,并且控制指定位置 chunk 的 fd 指针。
基本原理
如果在 malloc 的时候,申请的内存块在 small bin 范围内,那么执行的流程如下
1 | /* |
从下面的这部分我们可以看出
1 | // 获取 small bin 中倒数第二个 chunk 。 |
如果我们可以修改 small bin 的最后一个 chunk 的 bk 为我们指定内存地址的 fake chunk,并且同时满足之后的 bck->fd != victim 的检测,那么我们就可以使得 small bin 的 bk 恰好为我们构造的 fake chunk。也就是说,当下一次申请 small bin 的时候,我们就会分配到指定位置的 fake chunk。
House of Orange
House of Orange 的核心在于在没有 free 函数的情况下得到一个释放的堆块 (unsorted bin)。 这种操作的原理简单来说是当前堆的 top chunk 尺寸不足以满足申请分配的大小的时候,原来的 top chunk 会被释放并被置入 unsorted bin 中,通过这一点可以在没有 free 函数情况下获取到 unsorted bins。
我们来看一下这个过程的详细情况,我们假设目前的 top chunk 已经不满足 malloc 的分配需求。 首先我们在程序中的malloc调用会执行到 libc.so 的_int_malloc函数中,在_int_malloc函数中,会依次检验 fastbin、small bins、unsorted bin、large bins 是否可以满足分配要求,因为尺寸问题这些都不符合。接下来_int_malloc函数会试图使用 top chunk,在这里 top chunk 也不能满足分配的要求,因此会执行如下分支。
1 | /* |
此时 ptmalloc 已经不能满足用户申请堆内存的操作,需要执行 sysmalloc 来向系统申请更多的空间。 但是对于堆来说有 mmap 和 brk 两种分配方式,我们需要让堆以 brk 的形式拓展,之后原有的 top chunk 会被置于 unsorted bin 中。
综上,我们要实现 brk 拓展 top chunk,但是要实现这个目的需要绕过一些 libc 中的 check。 首先,malloc 的尺寸不能大于mmp_.mmap_threshold
1 | if ((unsigned long)(nb) >= (unsigned long)(mp_.mmap_threshold) && (mp_.n_mmaps < mp_.n_mmaps_max)) |
如果所需分配的 chunk 大小大于 mmap 分配阈值,默认为 128K,并且当前进程使用 mmap() 分配的内存块小于设定的最大值,将使用 mmap() 系统调用直接向操作系统申请内存。
在 sysmalloc 函数中存在对 top chunk size 的 check,如下
1 | assert((old_top == initial_top(av) && old_size == 0) || |
这里检查了 top chunk 的合法性,如果第一次调用本函数,top chunk 可能没有初始化,所以可能 old_size 为 0。 如果 top chunk 已经初始化了,那么 top chunk 的大小必须大于等于 MINSIZE,因为 top chunk 中包含了 fencepost,所以 top chunk 的大小必须要大于 MINSIZE。其次 top chunk 必须标识前一个 chunk 处于 inuse 状态,并且 top chunk 的结束地址必定是页对齐的。此外 top chunk 除去 fencepost 的大小必定要小于所需 chunk 的大小,否则在_int_malloc() 函数中会使用 top chunk 分割出 chunk。
我们总结一下伪造的 top chunk size 的要求
- 伪造的 size 必须要对齐到内存页
- size 要大于 MINSIZE(0x10)
- size 要小于之后申请的 chunk size + MINSIZE(0x10)
- size 的 prev inuse 位必须为 1
之后原有的 top chunk 就会执行_int_free从而顺利进入 unsorted bin 中。
House of Rabbit
fastbin 中会把相同的 size 的被释放的堆块用一个单向链表管理,分配的时候会检查 size 是否合理,如果不合理程序就会异常退出。而 house of rabbit 就利用了在 malloc consolidate 的时候 fastbin 中的堆块进行合并时 size 没有进行检查从而伪造一个假的堆块,为进一步的利用做准备。
前提条件: 1. 可以修改 fastbin 的 fd 指针或 size 2. 可以触发 malloc consolidate(merge top 或 malloc big chunk 等等)
House of rabbit 的优点是容易构造 overlap chunk,由于可以基于 fastbin attack,甚至不需要 leak 就可以完成攻击。
House of Roman
House of Roman 这个技巧说简单点其实就是 fastbin attack 和 Unsortbin attack 结合的一个小 trick。
该技术用于 bypass ALSR,利用 12-bit 的爆破来达到获取 shell 的目的。且仅仅只需要一个 UAF 漏洞以及能创建任意大小的 chunk 的情况下就能完成利用。
整个利用过程大概可以分为三步骤。
- 将 FD 指向 malloc_hook
- 修正 0x71 的 Freelist
- 往 malloc_hook 写入 one gadget
House of Pig
House of Pig 是一个将 Tcache Statsh Unlink+ Attack 和 FSOP 结合的攻击,同时使用到了 Largebin Attack 进行辅助。主要适用于 libc 2.31 及以后的新版本 libc 并且程序中仅有 calloc 时。
利用条件为
- 存在 UAF
- 能执行 abort 流程或程序显式调用 exit 或程序能通过主函数返回。
主要利用的函数为 _IO_str_overflow,可以参考 glibc 2.24 下 IO_FILE 的利用。
利用流程为
- 进行一个 Tcache Stash Unlink+ 攻击,把地址
__free_hook - 0x10写入 tcache_pthread_struct。由于该攻击要求__free_hook - 0x8处存储一个指向可写内存的指针,所以在此之前需要进行一次 large bin attack。 - 再进行一个 large bin attack,修改
_IO_list_all为一个堆地址,然后在该处伪造_IO_FILE结构体。 - 通过伪造的结构体触发
_IO_str_overflowgetshell。
IO_FILE Exploitation
FILE 结构
FILE 在 Linux 系统的标准 IO 库中是用于描述文件的结构,称为文件流。 FILE 结构在程序执行 fopen 等函数时会进行创建,并分配在堆中。我们常定义一个指向 FILE 结构的指针来接收这个返回值。
FILE 结构定义在 libio.h 中,如下所示
1 | struct _IO_FILE { |
进程中的 FILE 结构会通过_chain 域彼此连接形成一个链表,链表头部用全局变量_IO_list_all 表示,通过这个值我们可以遍历所有的 FILE 结构。
在标准 I/O 库中,每个程序启动时有三个文件流是自动打开的:stdin、stdout、stderr。因此在初始状态下,_IO_list_all 指向了一个有这些文件流构成的链表,但是需要注意的是这三个文件流位于 libc.so 的数据段。而我们使用 fopen 创建的文件流是分配在堆内存上的。
我们可以在 libc.so 中找到 stdin\stdout\stderr 等符号,这些符号是指向 FILE 结构的指针,真正结构的符号是
1 | _IO_2_1_stderr_ |
但是事实上_IO_FILE 结构外包裹着另一种结构_IO_FILE_plus,其中包含了一个重要的指针 vtable 指向了一系列函数指针。
在 libc2.23 版本下,32 位的 vtable 偏移为 0x94,64 位偏移为 0xd8
1 | struct _IO_FILE_plus |
vtable 是 IO_jump_t 类型的指针,IO_jump_t 中保存了一些函数指针,在后面我们会看到在一系列标准 IO 函数中会调用这些函数指针
1 | void * funcs[] = { |
fread
fread 是标准 IO 库函数,作用是从文件流中读数据,函数原型如下
1 | size_t fread ( void *buffer, size_t size, size_t count, FILE *stream) ; |
- buffer 存放读取数据的缓冲区。
- size:指定每个记录的长度。
- count: 指定记录的个数。
- stream:目标文件流。
- 返回值:返回读取到数据缓冲区中的记录个数
fread 的代码位于 / libio/iofread.c 中,函数名为_IO_fread,但真正的功能实现在子函数_IO_sgetn 中。
1 | _IO_size_t |
在_IO_sgetn 函数中会调用_IO_XSGETN,而_IO_XSGETN 是_IO_FILE_plus.vtable 中的函数指针,在调用这个函数时会首先取出 vtable 中的指针然后再进行调用。
1 | _IO_size_t |
在默认情况下函数指针是指向_IO_file_xsgetn 函数的,
1 | if (fp->_IO_buf_base |
fwrite
fwrite 同样是标准 IO 库函数,作用是向文件流写入数据,函数原型如下
1 | size_t fwrite(const void* buffer, size_t size, size_t count, FILE* stream); |
- buffer: 是一个指针,对 fwrite 来说,是要写入数据的地址;
- size: 要写入内容的单字节数;
- count: 要进行写入 size 字节的数据项的个数;
- stream: 目标文件指针;
- 返回值:实际写入的数据项个数 count。
fwrite 的代码位于 / libio/iofwrite.c 中,函数名为_IO_fwrite。 在_IO_fwrite 中主要是调用_IO_XSPUTN 来实现写入的功能。
根据前面对_IO_FILE_plus 的介绍,可知_IO_XSPUTN 位于_IO_FILE_plus 的 vtable 中,调用这个函数需要首先取出 vtable 中的指针,再跳过去进行调用。
1 | written = _IO_sputn (fp, (const char *) buf, request); |
在_IO_XSPUTN 对应的默认函数_IO_new_file_xsputn 中会调用同样位于 vtable 中的_IO_OVERFLOW
1 | /* Next flush the (full) buffer. */ |
_IO_OVERFLOW 默认对应的函数是_IO_new_file_overflow
1 | if (ch == EOF) |
在_IO_new_file_overflow 内部最终会调用系统接口 write 函数
fopen
fopen 在标准 IO 库中用于打开文件,函数原型如下
1 | FILE *fopen(char *filename, *type); |
- filename: 目标文件的路径
- type: 打开方式的类型
- 返回值: 返回一个文件指针
在 fopen 内部会创建 FILE 结构并进行一些初始化操作,下面来看一下这个过程
首先在 fopen 对应的函数__fopen_internal 内部会调用 malloc 函数,分配 FILE 结构的空间。因此我们可以获知 FILE 结构是存储在堆上的
1 | *new_f = (struct locked_FILE *) malloc (sizeof (struct locked_FILE)); |
之后会为创建的 FILE 初始化 vtable,并调用_IO_file_init 进一步初始化操作
1 | _IO_JUMPS (&new_f->fp) = &_IO_file_jumps; |
在_IO_file_init 函数的初始化操作中,会调用_IO_link_in 把新分配的 FILE 链入_IO_list_all 为起始的 FILE 链表中
1 | void |
之后__fopen_internal 函数会调用_IO_file_fopen 函数打开目标文件,_IO_file_fopen 会根据用户传入的打开模式进行打开操作,总之最后会调用到系统接口 open 函数,这里不再深入。
1 | if (_IO_file_fopen ((_IO_FILE *) new_f, filename, mode, is32) != NULL) |
总结一下 fopen 的操作是
- 使用 malloc 分配 FILE 结构
- 设置 FILE 结构的 vtable
- 初始化分配的 FILE 结构
- 将初始化的 FILE 结构链入 FILE 结构链表中
- 调用系统调用打开文件
fclose
fclose 是标准 IO 库中用于关闭已打开文件的函数,其作用与 fopen 相反。
1 | int fclose(FILE *stream) |
功能:关闭一个文件流,使用 fclose 就可以把缓冲区内最后剩余的数据输出到磁盘文件中,并释放文件指针和有关的缓冲区
fclose 首先会调用_IO_unlink_it 将指定的 FILE 从_chain 链表中脱链
1 | if (fp->_IO_file_flags & _IO_IS_FILEBUF) |
之后会调用_IO_file_close_it 函数,_IO_file_close_it 会调用系统接口 close 关闭文件
1 | if (fp->_IO_file_flags & _IO_IS_FILEBUF) |
最后调用 vtable 中的_IO_FINISH,其对应的是_IO_file_finish 函数,其中会调用 free 函数释放之前分配的 FILE 结构
1 | _IO_FINISH (fp); |
printf/puts
printf 和 puts 是常用的输出函数,在 printf 的参数是以’\n’结束的纯字符串时,printf 会被优化为 puts 函数并去除换行符。
puts 在源码中实现的函数是_IO_puts,这个函数的操作与 fwrite 的流程大致相同,函数内部同样会调用 vtable 中的_IO_sputn,结果会执行_IO_new_file_xsputn,最后会调用到系统接口 write 函数。
printf 的调用栈回溯如下,同样是通过_IO_file_xsputn 实现
1 | vfprintf+11 |
伪造 vtable 劫持程序流程
前面我们介绍了 Linux 中文件流的特性(FILE),我们可以得知 Linux 中的一些常见的 IO 操作函数都需要经过 FILE 结构进行处理。尤其是_IO_FILE_plus 结构中存在 vtable,一些函数会取出 vtable 中的指针进行调用。
因此伪造 vtable 劫持程序流程的中心思想就是针对_IO_FILE_plus 的 vtable 动手脚,通过把 vtable 指向我们控制的内存,并在其中布置函数指针来实现。
因此 vtable 劫持分为两种,一种是直接改写 vtable 中的函数指针,通过任意地址写就可以实现。另一种是覆盖 vtable 的指针指向我们控制的内存,然后在其中布置函数指针。
这里演示了修改 vtable 中的指针,首先需要知道_IO_FILE_plus 位于哪里,对于 fopen 的情况下是位于堆内存,对于 stdin\stdout\stderr 是位于 libc.so 中。
1 | int main(void) |
根据 vtable 在_IO_FILE_plus 的偏移得到 vtable 的地址,在 64 位系统下偏移是 0xd8。之后需要搞清楚欲劫持的 IO 函数会调用 vtable 中的哪个函数。关于 IO 函数调用 vtable 的情况已经在 FILE 结构介绍一节给出了,知道了 printf 会调用 vtable 中的 xsputn,并且 xsputn 的是 vtable 中第八项之后就可以写入这个指针进行劫持。
并且在 xsputn 等 vtable 函数进行调用时,传入的第一个参数其实是对应的_IO_FILE_plus 地址。比如这例子调用 printf,传递给 vtable 的第一个参数就是_IO_2_1_stdout_的地址。
利用这点可以实现给劫持的 vtable 函数传參,比如
1 |
|
但是在目前 libc2.23 版本下,位于 libc 数据段的 vtable 是不可以进行写入的。不过,通过在可控的内存中伪造 vtable 的方法依然可以实现利用。
1 |
|
我们首先分配一款内存来存放伪造的 vtable,之后修改_IO_FILE_plus 的 vtable 指针指向这块内存。因为 vtable 中的指针我们放置的是 system 函数的地址,因此需要传递参数 “/bin/sh” 或 “sh”。
因为 vtable 中的函数调用时会把对应的_IO_FILE_plus 指针作为第一个参数传递,因此这里我们把 “sh” 写入_IO_FILE_plus 头部。之后对 fwrite 的调用就会经过我们伪造的 vtable 执行 system(“sh”)。
同样,如果程序中不存在 fopen 等函数创建的_IO_FILE 时,也可以选择 stdin\stdout\stderr 等位于 libc.so 中的_IO_FILE,这些流在 printf\scanf 等函数中就会被使用到。在 libc2.23 之前,这些 vtable 是可以写入并且不存在其他检测的。
1 | print &_IO_2_1_stdin_ |
FSOP
FSOP 是 File Stream Oriented Programming 的缩写,根据前面对 FILE 的介绍得知进程内所有的_IO_FILE 结构会使用_chain 域相互连接形成一个链表,这个链表的头部由_IO_list_all 维护。
FSOP 的核心思想就是劫持_IO_list_all 的值来伪造链表和其中的_IO_FILE 项,但是单纯的伪造只是构造了数据还需要某种方法进行触发。FSOP 选择的触发方法是调用_IO_flush_all_lockp,这个函数会刷新_IO_list_all 链表中所有项的文件流,相当于对每个 FILE 调用 fflush,也对应着会调用_IO_FILE_plus.vtable 中的_IO_overflow。
1 | int |
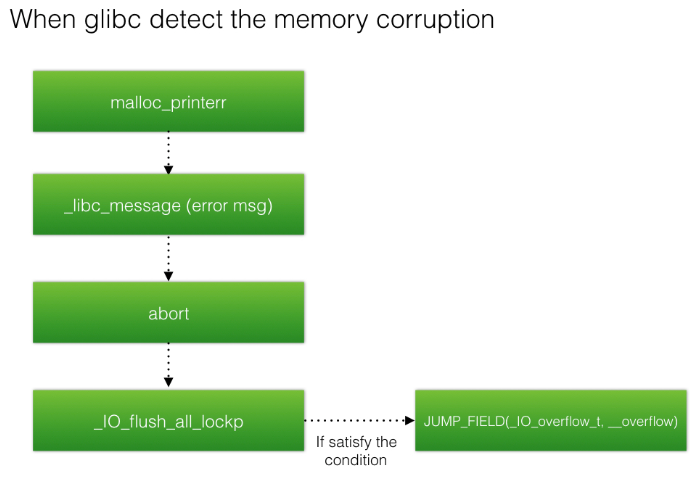
而_IO_flush_all_lockp 不需要攻击者手动调用,在一些情况下这个函数会被系统调用:
当 libc 执行 abort 流程时
当执行 exit 函数时
当执行流从 main 函数返回时
梳理一下 FSOP 利用的条件,首先需要攻击者获知 libc.so 基址,因为_IO_list_all 是作为全局变量储存在 libc.so 中的,不泄漏 libc 基址就不能改写_IO_list_all。
之后需要用任意地址写把_IO_list_all 的内容改为指向我们可控内存的指针,
之后的问题是在可控内存中布置什么数据,毫无疑问的是需要布置一个我们理想函数的 vtable 指针。但是为了能够让我们构造的 fake_FILE 能够正常工作,还需要布置一些其他数据。 这里的依据是我们前面给出的
1 | if (((fp->_mode <= 0 && fp->_IO_write_ptr > fp->_IO_write_base)) |
也就是
- fp->_mode <= 0
- fp->_IO_write_ptr > fp->_IO_write_base
在这里通过一个示例来验证这一点,首先我们分配一块内存用于存放伪造的 vtable 和_IO_FILE_plus。 为了绕过验证,我们提前获得了_IO_write_ptr、_IO_write_base、_mode 等数据域的偏移,这样可以在伪造的 vtable 中构造相应的数据
1 |
|
我们使用分配内存的前 0x100 个字节作为_IO_FILE,后 0x100 个字节作为 vtable,在 vtable 中使用 0x41414141 这个地址作为伪造的_IO_overflow 指针。
之后,覆盖位于 libc 中的全局变量 _IO_list_all,把它指向我们伪造的_IO_FILE_plus。
通过调用 exit 函数,程序会执行 _IO_flush_all_lockp,经过 fflush 获取_IO_list_all 的值并取出作为_IO_FILE_plus 调用其中的_IO_overflow
1 | ---> call _IO_overflow |
glibc 2.24 下 IO_FILE 的利用
在 2.24 版本的 glibc 中,全新加入了针对 IO_FILE_plus 的 vtable 劫持的检测措施,glibc 会在调用虚函数之前首先检查 vtable 地址的合法性。首先会验证 vtable 是否位于_IO_vtable 段中,如果满足条件就正常执行,否则会调用_IO_vtable_check 做进一步检查。
1 | /* Check if unknown vtable pointers are permitted; otherwise, |
计算 section_length = __stop___libc_IO_vtables - __start___libc_IO_vtables;,紧接着会判断 vtable - start_libc_IO_vtables 的 offset ,如果这个 offset 大于 section_length , 即大于 __stop___libc_IO_vtables - __start___libc_IO_vtables 那么就会调用 _IO_vtable_check() 这个函数。
1 | void attribute_hidden |
如果 vtable 是非法的,那么会引发 abort。
这里的检查使得以往使用 vtable 进行利用的技术很难实现
新的利用技术
fileno 与缓冲区的相关利用
在 vtable 难以被利用之后,利用的关注点从 vtable 转移到_IO_FILE 结构内部的域中。 前面介绍过_IO_FILE 在使用标准 IO 库时会进行创建并负责维护一些相关信息,其中有一些域是表示调用诸如 fwrite、fread 等函数时写入地址或读取地址的,如果可以控制这些数据就可以实现任意地址写或任意地址读。
1 | struct _IO_FILE { |
因为进程中包含了系统默认的三个文件流 stdin\stdout\stderr,因此这种方式可以不需要进程中存在文件操作,通过 scanf\printf 一样可以进行利用。
在_IO_FILE 中_IO_buf_base 表示操作的起始地址,_IO_buf_end 表示结束地址,通过控制这两个数据可以实现控制读写的操作。
示例
简单的观察一下_IO_FILE 对于调用 scanf 的作用
1 |
|
在执行程序第一次使用 stdin 之前,stdin 的内容还未初始化是空的
1 | 0x7ffff7dd18e0 <_IO_2_1_stdin_>: 0x00000000fbad2088 0x0000000000000000 |
调用 scanf 之后可以看到_IO_read_ptr、_IO_read_base、_IO_read_end、_IO_buf_base、_IO_buf_end 等域都被初始化
1 | 0x7ffff7dd18e0 <_IO_2_1_stdin_>: 0x00000000fbad2288 0x0000000000602013 |
进一步思考可以发现其实 stdin 初始化的内存是在堆上分配出来的,在这里堆的基址是 0x602000,因为之前没有堆分配因此缓冲区的地址也是 0x602010
1 | Start End Offset Perm Path |
分配的堆大小是 0x400 个字节,正好对应于_IO_buf_base~_IO_buf_end 在进行写入后,可以看到缓冲区中有我们写入的数据,之后目的地址栈中的缓冲区也会写入数据
1 | 0x602000: 0x0000000000000000 0x0000000000000411 <== 分配0x400大小 |
接下来我们尝试修改_IO_buf_base 来实现任意地址读写,全局缓冲区 buf 的地址是 0x7ffff7dd2740。修改_IO_buf_base 和_IO_buf_end 到缓冲区 buf 的地址
1 | 0x7ffff7dd18e0 <_IO_2_1_stdin_>: 0x00000000fbad2288 0x0000000000602013 |
之后 scanf 的读入数据就会写入到 0x7ffff7dd2740 的位置
1 | 0x7ffff7dd2740 <buf>: 0x00000a6161616161 0x0000000000000000 |
_IO_str_jumps -> overflow
libc中不仅仅只有_IO_file_jumps这么一个vtable,还有一个叫_IO_str_jumps的 ,这个 vtable 不在 check 范围之内。
1 | const struct _IO_jump_t _IO_str_jumps libio_vtable = |
如果我们能设置文件指针的 vtable 为 _IO_str_jumps 么就能调用不一样的文件操作函数。这里以_IO_str_overflow为例子:
1 | int |
利用以下代码来劫持程序流程
1 | new_buf |
几个条件 bypass:
1. fp->_flags & _IO_NO_WRITES为假2. (pos = fp->_IO_write_ptr - fp->_IO_write_base) >= ((fp->_IO_buf_end - fp->_IO_buf_base) + flush_only(1))3. fp->_flags & _IO_USER_BUF(0x01)为假4. 2*(fp->_IO_buf_end - fp->_IO_buf_base) + 100 不能为负数5. new_size = 2 * (fp->_IO_buf_end - fp->_IO_buf_base) + 100; 应当指向/bin/sh字符串对应的地址6. fp+0xe0指向system地址
构造:
1 | _flags = 0 |
示例
修改了 how2heap 的 houseoforange 代码,可以自己动手调试一下。
1 |
|
同时 house of pig 中的利用也是比较典型的例子,注意到满足
1 | pos = fp->_IO_write_ptr - fp->_IO_write_base; |
的时候,会先后执行
1 | size_t old_blen = _IO_blen (fp); |
三个操作,伪造 _IO_FILE 并劫持 vtable 为 _IO_str_jumps 通过一个 large bin attack 就可以轻松实现,并且我们上面三c个语句中的 new_size,old_buf 和 old_blen 是我们可控的,这个函数就可以实现以下三步
- 调用 malloc,实现从 tcache 中分配 chunk,在这里就可以把我们之前放入的 __free_hook fake chunk 申请出来
- 将一段可控长度可控内容的内存段拷贝置 malloc 得来的 chunk 中(可以修改 __free_hook 为 system)
- 调用 free,且参数为内存段起始地址(”/bin/sh\x00”,getshell)
也就是只要我们构造得当,执行该函数即可 getshell。
_IO_str_jumps -> finish
原理与上面的 _IO_str_jumps -> overflow 类似
1 | void |
条件:
- _IO_buf_base 不为空
- _flags & _IO_USER_BUF(0x01) 为假
构造如下:
1 | _flags = (binsh_in_libc + 0x10) & ~1 |
示例
修改了 how2heap 的 houseoforange 代码,可以自己动手调试一下。
1 |
|
