编写嗅探器
网络嗅探器可以让您查看在目标计算机传入和发出的数据包。因此,它们在开发利用的前后都有许多实际用途。在某些情况下,您可以使用现有的嗅探工具,如 Wireshark (https://wireshark.org/)或python解决方案,如Scapy(我们将在下一章探讨)。尽管如此,知道如何组装您自己的快速嗅探器来查看和解码网络流量也是很有好处的。
编写这样的工具还将使您对成熟的工具有一个深刻的认识,因为这些工具可以轻松地处理更精细的问题,而您只需花费很少的精力。您还可能学到一些新的Python技术,并可能更好地理解底层网络位是如何工作的。
在前一章中,我们讨论了如何使用TCP和UDP发送和接收数据。这很可能是您与大多数网络服务交互的方式。但是在这些高级协议之下才是决定网络数据包如何发送和接收的构建块。您将使用原始套接字来访问较低层的网络信息,例如原始Internet协议(IP)和Internet控制消息协议(ICMP)头。在本章中,我们不会解码任何以太网信息,但是如果您打算执行任何底层网络攻击,例如ARP毒化(ARP欺骗),或者正在开发无线评估工具,您应该非常熟悉以太网帧及其使用。
让我们先简要了解一下如何发现网段上的活动主机。
构建一个UDP主机探测工具
我们的嗅探器的主要目标是发现目标网络上的主机。攻击者希望能够看到网络上的所有潜在目标,以便集中侦察和攻击利用。
我们将使用大多数操作系统的已知行为来确定指定IP地址上是否存在活动主机。当我们向主机上的一个关闭的端口发送UDP数据报时,该主机通常会返回一个ICMP消息,表明该端口不可达。这个ICMP消息告诉我们有一个存活的主机,因为如果没有主机,我们可能不会收到任何对UDP数据报的响应。因此,我们必须选择一个不太可能被使用的UDP端口。为了达到最大的覆盖范围,我们可以探测几个端口,以确保我们没有命中一个活动的UDP服务。
为什么使用用户数据报协议UDP呢?因为它可以在整个子网中洪泛消息并等待ICMP响应相应到达而没有开销。这是一个相当简单的扫描器,因为大部分工作都是解码和分析各种网络协议头。我们将在Windows和Linux上实现这个主机扫描程序,以最大限度地提高在企业环境中使用它的可行性。
我们还可以在扫描器中构建额外的规则我们发现的任何主机上启动完整的Nmap端口扫描。这样我们就能确定它们是否有可行的网络攻击面。这是留给读者的练习,我们作者期待听到一些创造性的方法,你可以扩展这个核心概念。让我们开始吧。
Windows和Linux的包嗅探
在Windows中访问原始套接字的过程与Linux上略有不同,但我们希望能够灵活地将相同的嗅探器部署到多种平台上。为此,我们将创建一个套接字对象,然后确定我们在哪个平台上运行。Windows系统要求我们,通过套接字输入/输出控制(IOCTL)设置一些额外的标志,设置网络接口为混杂模式。 input/output control (IOCTL)是用户空间程序与内核模式组件通信的一种手段。您在这里了解一下:http://en.wikipedia.org/wiki/Ioctl
在第一个例子中,我们只需设置原始套接字嗅探器,读取单个数据包,然后退出:
1 | import socket |
我们首先将 HOST IP定义为我们自己的机器地址,并使用嗅探网络接口[1]上的数据包所需的参数构造套接字对象。Windows和Linux之间的区别是,Windows允许我们嗅探所有传入的数据包,而不用考虑协议,而Linux强制指定我们嗅探ICMP数据包。请注意,我们使用的是混杂模式,它需要Windows上的管理员权限或Linux上的root权限。混杂模式允许我们嗅探网卡经过的所有数据包,甚至那些目标不是我们特定主机的数据包。然后,我们设置一个套接字选项[2],其中包括捕获的数据包中的IP头。下一步[3]是确定我们是否使用Windows,如果是,执行额外的步骤,发送IOCTL到网卡驱动程序,以启用混杂模式。如果你在虚拟机上运行Windows,你可能会收到一个通知,说客户操作系统启用了混杂模式;当然,你会允许的。现在,我们准备执行一些实际的嗅探任务,在本例中,我们只打印出整个没有进行解码的原始数据包[4]。这只是为了确保嗅探代码的核心能够正常工作。在嗅探到单个数据包之后,我们再次测试Windows,然后在退出脚本之前禁用混杂模式[5]。
Kicking the Tires
在Windows下打开一个新的终端或 cmd.exe shell,运行以下命令:
1 | python sniffer.py |
在另一个终端或shell窗口中,选择要ping的主机。在这里,我们ping nostarch.com:
1 | ping nostarch.com |
在你运行嗅探器的第一个窗口中,你应该会看到一些乱码输出,类似于以下内容:
1 | (b'E\x00\x00T\xad\xcc\x00\x00\x80\x01\n\x17h\x14\xd1\x03\xac\x10\x9d\x9d\x00\ |
您可以看到,我们已经捕获了发向nostarch.com的初始ICMP ping请求(根据输出末尾nostarch.com的IP可见,104.20.209.3)。如果您在Linux上运行这个示例,您将收到来自nostarch.com的响应。
嗅探一个包并不是特别有用,所以让我们添加一些功能来处理更多的包并解码它们的内容。
IP层解码
在它当前的形式,我们的嗅探器接收所有的IP头,以及任何更高的协议,如TCP, UDP,或ICMP。正如前面所示,信息被打包成二进制形式,这很难理解。让我们对数据包的IP部分进行解码,以便从中提取有用的信息,例如协议类型(TCP、UDP或ICMP)以及源IP地址和目的IP地址。这将作为以后进一步协议解析的基础。
如果我们检查网络上的实际数据包是什么样子的,您应该了解我们需要如何解码传入的数据包。IP报头的组成请参见图3-1。
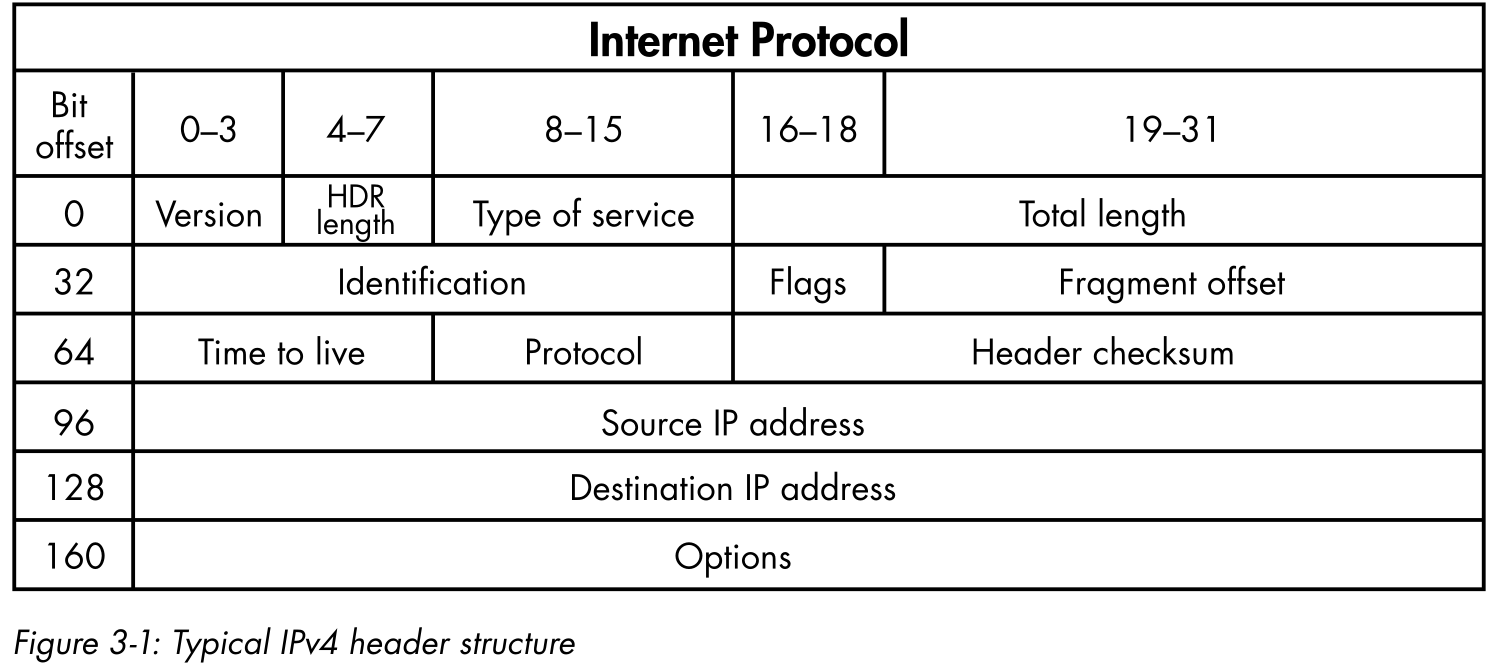
我们将解码整个IP报头(Options字段除外),并提取协议类型、源IP地址和目的IP地址。这意味着我们将直接处理二进制文件,并且我们必须想出一种用Python分离IP头的每个部分的策略。
在Python中,有两种方法可以将外部二进制数据转换为一种数据结构。您可以使用 ctypes 模块或 struct 模块来定义数据结构。 ctypes 模块是Python的外部函数库。它为基于C的语言提供了一个桥梁,使您能够使用兼容C的数据类型和调用共享库中的函数。另一方面, struct 在Python值和表示为Python字节对象的C结构之间进行转换。换句话说, ctypes 模块除了提供许多其他功能外,还处理二进制数据类型,而 struct 模块主要处理二进制数据。
当你浏览web上的工具库时,你会看到这两种方法都被使用。本节将向您展示如何使用它们从网络中读取一个IPv4报头。这取决于您选择哪种方法;两种方法都可以。
ctypes模块
下面的代码片段定义了一个新类 IP ,它可以读取数据包并将报头解析为其单独的字段:
1 | from ctypes import * |
这个类创建一个 _fields_ 结构来定义IP头的每个部分。该结构使用在 ctypes 模块中定义的C类型。例如, c_ubyte 类型是unsigned char类型, c_ushort 类型是unsigned short类型,等等。可以看到每个字段都与图3-1中的IP报头相匹配。每个字段描述都有三个参数:字段的名称(如 ihl 或 offset ),它所接受的值的类型(如 c_ubyte 或 c_ushort ),以及该字段的以位为单位的宽度(如 ihl 和 version 为4)。能够指定位宽是很方便的,因为它提供了指定我们需要的任何长度的自由,不仅是在字节级别(在字节级别的规范将强制我们定义的字段总是8位的倍数)。
IP 类继承自 ctypes 模块的 Structure 类,该类指定在创建任何对象之前必须有一个已定义的 _fields_ 结构。为了填充_fields*_结构, *Structure 类使用 __new__ 方法,该方法将类引用作为第一个参数。它创建并返回类的一个对象,该对象传递给 __init__ 类函数。当我们创建IP对象时,我们将按照通常的方式进行,但在下面,Python调用 __new__ ,它在对象创建之前(当 __init__类函数被调用时)填充_fields_数据结构。只要你预先定义了这个结构,你就可以将外部网络数据包数据传递给 __new__ 函数,然后这些字段就会神奇地出现在你的对象属性中。
现在您已经了解了如何将C数据类型映射到IP头的值。在转换到Python对象时使用C代码作为参考可能会很有用,因为到纯Python的转换是无缝的。有关使用该模块的详细信息,请参阅 ctypes 文档。
struct模块
struct 模块提供了可以用来指定二进制数据结构的格式字符。在下面的例子中,我们将再次定义一个 IP 类来保存头信息。但这一次,我们将使用格式字符来表示报头的各个部分:
1 | import ipaddress |
第一个格式字符(在本例中是<)总是指定数据的字节顺序,或者二进制数中的字节顺序。C类型以机器的本机格式和字节顺序表示。在本例中,我们在Kali (x64)上,这是小端序。在小端序存储的机器中,最低位字节存储在较低地址中,最高位字节存储在最高地址中。
下一个格式字符表示头的各个部分。struct 模块提供了几个格式字符。对于IP报头,我们只需要格式字符 B (1-byte unsigned char,1字节无符号字符)、 H (2-byte unsigned short,2字节无符号短字符)和s(a byte array that requires a byte-width specification; 4s means a 4-byte string,需要1字节宽度规范的字节数组;4s表示4字节字符串)。注意格式字符串是如何与图3-1中的IP报头图结构相匹配的。
记住,使用 ctypes ,我们可以指定单个头文件部分的位宽。使用 struct 模块时, nybble (4位数据单位,也就是半字节,也称为nibble)没有格式字符,因此我们必须做一些操作,从头文件的第一部分获取 ver 和 hdrlen 变量。
对于我们接收到的头数据的第一个字节,我们给 ver 变量赋值仅 high-order 半字节(字节中的第一个nybble)。获得一个字节的高位半字节的典型方式是将字节 right-shift (右移)4位,这相当于在字节的前面加上4个0,导致最后4位减少[1]。这只给我们留下了原始字节的第一个字节。Python代码本质上是这样做的:
1 | 0 1 0 1 0 1 1 0 >> 4 |
我们想给 hdrlen 变量赋值低位nybble,即字节的最后4位。获取字节的第二个半字节的典型方法是对0xF(00001111) [2]使用布尔 AND (与)运算。这将应用布尔运算,使0和1“与”运算产生0(因为0等价于FALSE,而1等价于TRUE)。要使表达式为真,第一部分和最后一部分都必须为真。因此,这个操作删除了前4位,因为任何和0进行与运算的值都将是0。它保持最后4位不变,因为任何和1进行与运算的值都将返回原始值。本质上,Python代码对字节的操作如下:
1 | 0 1 0 1 0 1 1 0 |
您不需要非常了解二进制操作来解码IP头,但您将看到某些模式,如您在探索其他黑客的代码时发现会喜欢反复使用移位和AND,因此了解这些技术是值得的。
在这种需要一些位移位的情况下,解码二进制数据需要一些努力。但在许多情况下(如阅读ICMP消息),设置会很简单的:ICMP消息的每个部分都是8位的倍数,和 struct 模块提供的格式字符是8位的倍数,所以没有必要把一个字节成nybbles半字节分开。在如图3-2所示的Echo Reply ICMP报文中,可以看到ICMP报头的每个参数都可以用现有格式字母(BBHHH)中的一个来定义。
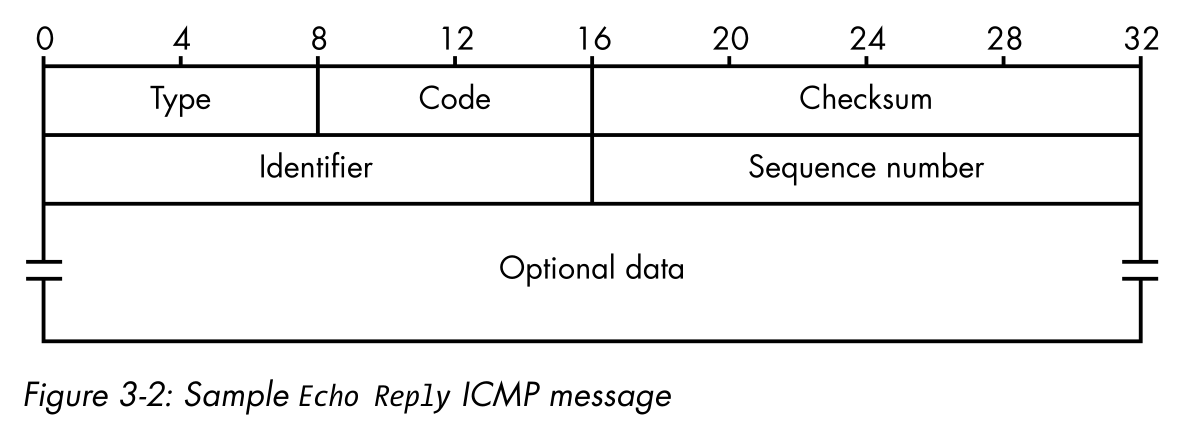
解析此消息的一种快速方法是简单地为前两个属性分配1字节,为后三个属性分配2字节:
1 | class ICMP: |
阅读 struct 文档(https://docs.python.org/3/library/struct.html)了解使用这个模块的详细信息。
你可以使用 ctypes 模块或 struct 模块来读取和解析二进制数据。不管你采用哪种方法,你都会像这样实例化这个类:
1 | mypacket = IP(buff) |
在这个例子中,您用变量 buff 中的包数据实例化IP类。
编写IP解码器
让我们实现刚才创建到 sniffer_ip_header_decode.py 文件中的IP解码程序,如下所示:
1 | import ipaddress |
首先,我们引入了IP类定义[1],它定义了一个Python结构,它将接收到的缓冲区的前20个字节映射到一个支持的IP头。正如您所看到的,我们标识的所有字段与头结构很好地匹配。我们做了一些处理,以产生一些我们可读的输出,这些输出表明正在使用的协议和连接中涉及的IP地址[2]。使用我们新创建的IP结构,我们现在编写规则断地读取包并解析它们的信息。我们读取包[3],然后传递前20个字节[4]来初始化我们的IP结构。接下来,我们只需打印捕获的信息[5]。来试试吧。
Kicking the Tires
让我们测试一下前面的代码,看看我们从发送的原始数据包中提取的是哪种信息。我们强烈建议您在您的Windows机器上进行此测试,因为您可以进行一些非常方便的测试(例如,打开一个浏览器),然后将能够看到TCP、UDP和ICMP。如果您仅限于Linux,那么可以执行前面的ping测试来查看它的运行情况。
打开一个终端,输入以下内容:
1 | python sniffer_ip_header_decode.py |
现在,因为Windows是非常chatty,您可能会立即看到输出。作者通过打开Internet Explorer并访问www.google.com来测试这个脚本,下面是我们的脚本的输出:
(笔者注:chatty我实在想不懂作者表达什么意思了。还有,竟然还有人用IE……国内用户换个网站吧,大家一定要遵守国家法律)
1 | Protocol: UDP 192.168.0.190 -> 192.168.0.1 |
因为我们没有对这些数据包做任何深入的检查,所以我们只能猜测这个流表示什么。我们的猜测是,前两个UDP数据包是域名系统(DNS)查询,以确定google.com的网络位置,而随后的TCP会话才是我们的机器实际上连接和从他们的web服务器下载内容。
要在Linux上执行相同的测试,我们可以ping google.com,结果如下所示:
1 | Protocol: ICMP 74.125.226.78 -> 192.168.0.190 |
您已经看到了限制:我们只看到响应,而且只有ICMP协议的数据包。但是因为我们是有意构建一个主机探测扫描器,所以这个结果是完全可以接受的。现在,我们将使用与解码IP报头相同的技术来解码ICMP消息。
解码ICMP
现在我们可以完全解码任何嗅探数据包的IP层,我们必须能够解码我们的扫描器捕获的发送UDP数据报到关闭的端口所引起的ICMP响应的包。ICMP消息的内容可能相差很大,但每条消息都包含保持一致的三个元素:类型、代码和校验和字段。类型和代码字段通知接收主机到达的ICMP消息的类型,然后指示如何正确解码。
为了扫描器的目标,我们要寻找类型值3和代码值3。3对应ICMP报文的 Destination Unreachable (目标不可达)类型,代码值为3表示已经导致了 Port Unreachable (端口不可达)错误。目标不可达ICMP报文示意图如图3-3所示。

如您所见,前8位是类型,后8位包含我们的ICMP代码。需要注意的一件有趣的事情是,当主机发送其中一个ICMP消息时,它实际上包含生成响应的原始消息的IP头。我们还可以看到,我们将对发送的原始数据报的8个字节进行双重检查,以确保扫描器引发ICMP响应。为此,我们只需切掉所接收缓冲区的最后8个字节,以取出扫描器发送的magic字符串。
让我们在前面的扫描器中添加更多代码,以包括解码ICMP包的能力。让我们将前面的文件保存为 sniffer_with_icmp.py ,并添加以下代码:
1 | import ipaddress |
这段简单的代码在现有IP结构下创建了一个ICMP结构[1]。当数据包接收的主循环确定我们已经收到了ICMP包时[2],我们计算原始包中的ICMP数据段[3]的偏移量,然后创建缓冲区[4]并打印type和code字段。长度计算是基于IP报头ihl字段,该字段表示IP报头中包含的32位字(4字节块)的数量。因此,通过将这个字段乘以4,我们就知道了IP报头的大小,从而知道下一个网络层(在本例中是ICMP)的开始位置。
如果我们用标准的ping测试运行这段代码,我们的输出现在应该略有不同:
1 | Protocol: ICMP 74.125.226.78 -> 192.168.0.190 |
这表明ping (ICMP Echo)响应被正确接收和解码。现在我们已经准备好实现发送UDP数据报并解释其结果的最后一点功能。
现在让我们添加 ipaddress 模块的使用,这样我们就可以使用主机探测扫描覆盖整个子网。将 sniffer_with_icmp.py 脚本保存为 scanner.py ,并添加以下代码:
1 | import ipaddress |
最后这段代码应该相当容易理解。我们定义了一个简单的字符串签名[1],以便我们可以测试响应是否来自我们最初发送的UDP包。我们的 udp_sender 函数[2]只接受我们在脚本顶部指定的子网,遍历该子网中的所有IP地址,并向它们发送UDP数据报。
然后定义一个 Scanner 类[3]。我们将一个host作为传递的参数来初始化它。当它初始化时,我们创建一个套接字,如果运行Windows则打开混杂模式,并使套接字成为 Scanner 类的一个属性。
sniff 类函数[4]扫描网络,其步骤与前面的示例相同,只是这一次它保留了一个关于哪些主机是启动活跃的记录。如果我们检测到预期的ICMP消息,我们首先检查以确保ICMP响应来自我们的目标子网[5]。然后执行最后的检查,确保ICMP响应中有我们的magic字符串[6]。如果所有这些检查都通过了,我们将打印发出ICMP消息的主机的IP地址[7]。当我们使用CTRL-C结束扫描进程时,我们处理了键盘中断[8]。也就是说,如果在Windows上,我们会关闭混杂模式,并打印出活跃主机的排序列表。
__main__块执行设置的工作是:它创建 Scanner 对象,休眠几秒钟,然后,在调用 sniff 类函数之前,在一个单独的线程中生成 udp_sender [9],以确保没有干扰到我们嗅探响应的能力。我们来试试吧。
Kicking the Tires
现在让我们在本地网络上运行扫描器。您可以使用Linux或Windows,因为结果是相同的。在作者的例子中,我们所在的本地机器的IP地址是192.168.0.187,因此我们将扫描网段设置为192.168.0.0/24。如果在运行扫描程序时输出噪声太大,只需注释掉所有的print语句,除了最后一个告诉您哪些主机正在响应的语句。
1 | python.exe scanner.py |
IPADDRESS模块
我们的扫描器将使用一个名为 ipaddress 的库,它将允许我们提供一个子网掩码,例如192.168.0.0/24,并让扫描器以适合的方法处理它。
ipaddress 模块使得使用子网和寻址非常容易。例如,您可以使用 Ipv4Network 对象运行如下简单测试:
1 | ip_address = "192.168.112.3" |
或者,如果你想把数据包发送到整个网络,你也可以创建简单的迭代器:
1 | for ip in Ipv4Network("192.168.112.1/24"): |
当一次处理整个网络时,这将极大地简化您的编程工作,并且非常适合我们的主机发现工具。
对于像我们这样的快速扫描,只需要几秒钟就能得到结果。通过将这些IP地址与家用路由器中的DHCP表进行相互参照,我们能够验证结果是准确的。您可以很容易地扩展本章中所学的内容,以解码TCP和UDP包,并围绕扫描仪构建其他工具。这个扫描器对于我们将在第7章开始构建的木马框架也很有用。这将让部署的木马可以扫描本地网络以寻找其他目标。
现在,您已经了解了网络在高层和低层如何工作的基础知识,下面让我们探索一个非常成熟的Python库Scapy。
